[논문리뷰] AdaCodec: A Predictive Visual Code for Video MLLMs
링크: 논문 PDF로 바로 열기
메타데이터
저자: Haowen Hou, Zhen Huang, Zheming Liang, Qingyi Si, Chenglin Li, Shuai Dong, Kele Shao, Ruilin Li, Dianyi Wang, Nan Duan, Jiaqi Wang
1. Key Terms & Definitions (핵심 용어 및 정의)
- Predictive Visual Code: 비디오의 시간적 중복성을 제거하기 위해, 이전 컨텍스트로부터 예측 불가능한 프레임(I-frame)에만 전체 토큰을 할당하고, 예측 가능한 프레임은 움직임과 잔차(Residual) 정보인 P-tokens로 인코딩하는 시각적 인터페이스.
- P-tokenizer: 표준 ViT를 기반으로 설계되었으며, 5채널 입력([잔차, 움직임 벡터])을 받아 Compact한 P-tokens를 생성하는 전용 인코더.
- Adaptive GOP (Group of Pictures): 고정된 길이가 아닌, 프레임 단위의 예측 비용(pcost)을 기반으로 I-frame을 동적으로 삽입하여 비디오 컨텍스트를 효율적으로 분할하는 구조.
- E2EL (End-to-End Latency): 비디오 입력부터 최종 모델 응답까지 소요되는 전체 추론 시간으로, AdaCodec은 이를 획기적으로 단축함.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 비디오 MLLMs가 비디오의 시간적 중복성(Temporal Redundancy)을 무시하고 모든 프레임을 독립적인 RGB 이미지로 처리하여 발생하는 비효율성 문제를 해결한다. 현재의 인터페이스는 비디오 길이에 비례하여 시각적 토큰 수가 선형적으로 증가하며, 이는 컨텍스트 창(Context Window) 점유 및 추론 지연(Latency)의 주원인이 된다. 기존의 프레임 샘플링이나 압축 기법들은 여전히 개별 RGB 프레임을 인코딩하는 방식에 의존하고 있어 근본적인 중복성 제거에 한계가 있다. 저자들은 인간의 시각 시스템과 현대 비디오 코덱의 예측 코딩 원리에서 착안하여, 비디오 MLLM 전용의 예측적 시각 코드인 AdaCodec을 제안한다 [Figure 1].
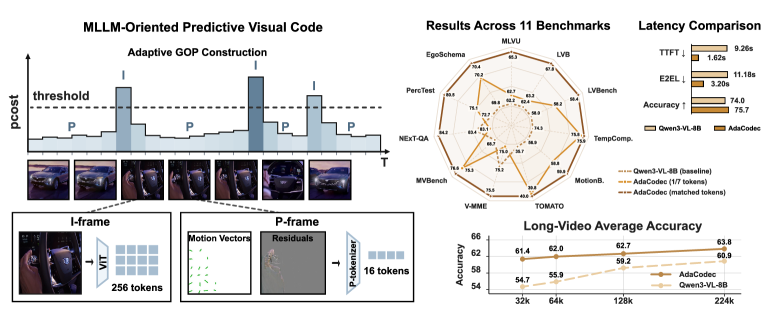
Figure 1 — AdaCodec 예측 코딩 개념
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 AdaCodec을 통해 I-frame에는 전체 ViT 토큰을 할당하고, 그 사이의 예측 가능한 프레임들은 움직임 벡터와 잔차를 결합한 P-tokens로 표현하는 방식을 제안한다 [Figure 2]. 각 비디오는 프레임별 예측 비용(pcost)이 임계값을 넘을 때마다 새로운 GOP를 시작하도록 동적으로 분할되어 정보 손실을 최소화한다. 실험 결과, AdaCodec은 기존 Qwen3-VL-8B 베이스라인 대비 1/7의 토큰 예산만으로도 Long-video 벤치마크 전체에서 우수한 성능을 달성하였다. 특히 Time-to-first-token (TTFT)을 9.26초에서 1.62초로, E2EL을 11.18초에서 3.20초로 대폭 단축하면서도 5개 일반 비디오 이해 벤치마크 평균 점수를 74.0에서 75.7로 향상시켰다 [Table 4]. 또한, 고정된 토큰 예산 내에서는 MVBench에서 최대 +7.9%의 성능 향상을 기록하며 예측 코딩의 효율성을 입증하였다 [Table 2].
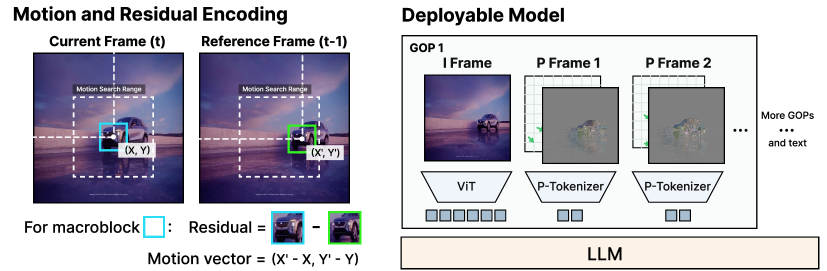
Figure 2 — AdaCodec 아키텍처
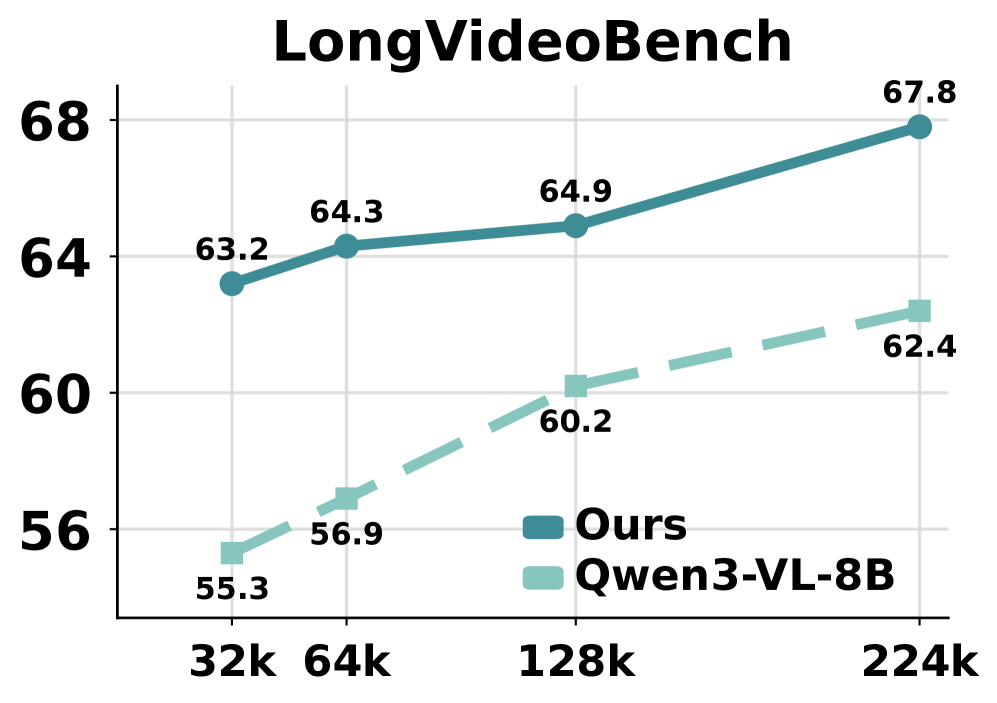
Table 4 — 지연 시간 및 성능 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 AdaCodec을 통해 비디오 MLLM의 시각적 인터페이스를 근본적으로 재설계함으로써 추론 효율성과 성능의 Pareto 개선을 달성하였다. 이 연구는 비디오 모델이 단순히 더 많은 컴퓨팅 자원을 투입하는 대신, 데이터의 시간적 특성을 고려한 예측 코딩 방식을 통해 정보를 압축 처리할 수 있음을 보여준다. 이러한 접근 방식은 향후 장시간 비디오 이해 및 실시간 비디오 모델 응용 분야에서 모델의 경량화와 응답 속도 향상을 위한 핵심적인 기술적 이정표가 될 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] WEAVER, Better, Faster, Longer: An Effective World Model for Robotic Manipulation
- [논문리뷰] VIA-SD: Verification via Intra-Model Routing for Speculative Decoding
- [논문리뷰] High-Fidelity Two-Step Image Generation via Teacher-Aligned End-to-End Distillation
- [논문리뷰] Joint Agent Memory and Exploration Learning via Novelty Signals
- [논문리뷰] AsyncTool: Evaluating the Asynchronous Function Calling Capability under Multi-Task Scenarios
Review 의 다른글
- 이전글 [논문리뷰] Absorbing Complexity: An Interaction-Native Knowledge Harness for Financial LLM Agents
- 현재글 : [논문리뷰] AdaCodec: A Predictive Visual Code for Video MLLMs
- 다음글 [논문리뷰] AdaPlanBench: Evaluating Adaptive Planning in Large Language Model Agents under World and User Constraints
댓글