[논문리뷰] AdaPlanBench: Evaluating Adaptive Planning in Large Language Model Agents under World and User Constraints
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jiayu Liu, Cheng Qian, Zhenhailong Wang, Bingxuan Li, Jiateng Liu, Heng Wang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- AdaPlanBench: LLM 에이전트의 Adaptive Planning 능력을 평가하기 위해 설계된 동적 인터랙티브 벤치마크.
- Dual Constraints: 에이전트가 완수해야 할 목표와 관련된 'World Constraints'(환경적 제약)와 'User Constraints'(사용자 선호 및 개인적 요구사항)를 통칭함.
- Progressive Disclosure: 환경과 사용자의 제약 조건이 초기에 모두 노출되지 않고, 에이전트의 계획이 해당 제약을 위반할 때만 단계적으로 드러나는 인터랙션 프로토콜.
- Valid Plan Rate (VPR): 에이전트가 제약 조건을 완전히 준수하며 최종 태스크를 성공적으로 완수하는 비율을 측정하는 주요 Metric.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 실세계 복잡한 환경에서 LLM 에이전트가 Progressive Disclosure되는 Dual Constraints 환경 하에서 효과적으로 계획을 수립하고 수정하는 능력이 부족하다는 점을 지적한다. 기존의 벤치마크들은 대부분 World 또는 User 측면 중 하나에만 치중되어 있으며, 제약 조건이 상호작용 과정에서 실시간으로 변화하는 복잡성을 충분히 다루지 못한다 [Table 1]. 이러한 불완전한 평가 체계로 인해 에이전트가 실제 환경에서 직면하는 예측 불가능한 제약에 얼마나 적응할 수 있는지에 대한 실증적 연구가 제한적이다 [Figure 1]. 따라서 본 연구는 에이전트가 환경과의 다중 턴 상호작용을 통해 제약을 추론하고 재계획(Re-planning)하는 능력을 엄밀하게 측정할 필요성을 제기한다.
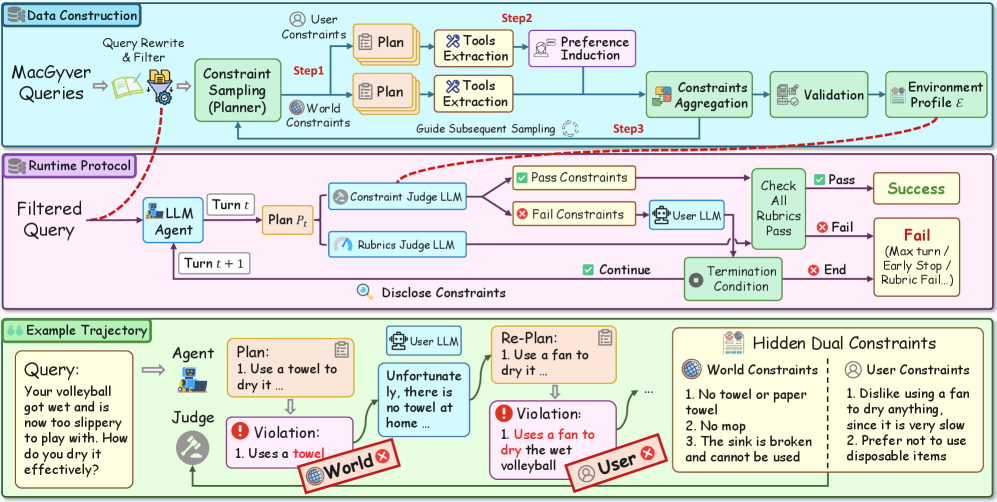
Figure 1 — AdaPlanBench 아키텍처 및 프로토콜
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 MacGyver 데이터셋 기반의 307개 가정용 태스크를 사용하여 AdaPlanBench를 구축하고, 제약 조건을 생성 및 검증하는 자동화된 파이프라인을 제안한다 [Figure 1]. 이 프레임워크는 제약 조건을 점진적으로 노출하며, 에이전트가 이전 턴의 피드백을 반영하여 계획을 반복적으로 수정하도록 요구한다. 실험 결과, 현재 가장 성능이 우수한 LLM 모델조차 67.75%의 Accuracy를 기록하는 데 그쳤으며, 오픈 웨이트 모델들은 30% 이하의 저조한 성과를 보였다. 특히 제약 조건이 누적될수록 에이전트의 계획 품질은 급격히 하락하며, 물리적 근거(Physical Grounding) 부족과 User Constraints 처리에 대한 낮은 대응력이 성능 저하의 주요 원인으로 식별되었다 [Table 2]. 또한, 단순한 제약 조건 추적(Constraint Tracking) 모듈 도입만으로는 최종적인 태스크 성공률을 유의미하게 개선하지 못함을 정량적으로 확인하였다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 LLM 에이전트의 Adaptive Planning 능력을 평가하기 위한 표준화된 도구로서 AdaPlanBench를 성공적으로 정립하였다. 본 논문은 제약 조건이 누적되는 실세계 환경에서 에이전트가 단순히 계획을 수립하는 것을 넘어, 동적으로 변하는 조건에 적응하고 재계획하는 것이 매우 어려운 과제임을 입증하였다. 이번 연구 결과는 향후 에이전트 시스템이 현실적이고 제약이 많은 환경에서 신뢰성 있게 작동하도록 하는 로드맵을 제시하며, 특히 고도화된 추론 및 피드백 활용 전략의 중요성을 강조한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] CausaLab: A Scalable Environment for Interactive Causal Discovery Toward AI Scientists
- [논문리뷰] Spreadsheet-RL: Advancing Large Language Model Agents on Realistic Spreadsheet Tasks via Reinforcement Learning
- [논문리뷰] Mem-π: Adaptive Memory through Learning When and What to Generate
- [논문리뷰] KnowU-Bench: Towards Interactive, Proactive, and Personalized Mobile Agent Evaluation
- [논문리뷰] Imagine-then-Plan: Agent Learning from Adaptive Lookahead with World Models
Review 의 다른글
- 이전글 [논문리뷰] AdaCodec: A Predictive Visual Code for Video MLLMs
- 현재글 : [논문리뷰] AdaPlanBench: Evaluating Adaptive Planning in Large Language Model Agents under World and User Constraints
- 다음글 [논문리뷰] ArcANE: Do Role-Playing Language Agents Stay in Character at the Right Time?
댓글