[논문리뷰] CausaLab: A Scalable Environment for Interactive Causal Discovery Toward AI Scientists
링크: 논문 PDF로 바로 열기
저자: Junlin Yang, Dylan Zhang, Xiangchen Song, Qirun Dai, Xiao Liu, Yuen Chen, Aniket Vashishtha, Jing Shi, Chenhao Tan, Hao Peng
1. Key Terms & Definitions (핵심 용어 및 정의)
- CausaLab: LLM agent의 대화형 인과 발견(interactive causal discovery) 능력을 평가하기 위한 확장 가능한 가상 실험 환경이다.
- SCM (Structural Causal Models): 변수 간의 인과적 관계를 directed graph와 구조 방정식으로 형식화한 모델이며, CausaLab에서는 매 에피소드마다 무작위로 샘플링되어 ground truth로 사용된다.
- DSL (Domain-Specific Language): agent가 에피소드 진행 과정에서 도출한 가설(인과 그래프, 구조 방정식, 계수)을 기록하고 파싱하여, 최종 결과뿐만 아니라 Mechanism Recovery의 충실도를 평가할 수 있게 하는 도구이다.
- Mechanism Recovery: agent가 단순히 결과를 예측하는 것을 넘어, 데이터 생성 과정(ground-truth SCM)을 얼마나 정확하게 복원했는지 평가하는 지표이다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 인과 추론 벤치마크가 LLM의 진정한 인과적 사고를 평가하기보다 암기된 지식에 의존하는 'Causal parrot' 문제를 해결하기 위해 CausaLab을 제안한다 [Figure 1]. 기존 연구들은 주로 정적인 환경에서 질문-응답 방식을 사용해 LLM의 causal reasoning을 평가했으나, 이는 실제 과학적 발견에 필요한 실험 설계 및 가설 수정 과정을 반영하지 못한다. 저자들은 agent가 관찰과 개입(intervention)을 통해 미지의 SCM을 능동적으로 학습하고, 이를 통해 새로운 인스턴스의 결과를 예측하는 능력을 평가해야 한다고 주장한다.

Figure 1 — CausaLab 에피소드 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 agent가 prior measurement records를 관찰하고, budgeted intervention을 수행하며, 매 단계 DSL을 통해 가설을 수정하는 반복적인 루프를 설계했다 [Figure 1]. 실험 결과, 예측 정확도(Task accuracy)가 높다고 해서 반드시 인과적 메커니즘을 정확히 복원한 것은 아님을 확인했다. 예를 들어, GPT-5.2-high는 6-node 환경에서 92%의 높은 task accuracy를 기록했으나, all-edge F1 지표는 0.471에 불과했다 [Figure 3]. 또한, 관찰과 개입을 병행하는 mixed regime이 pure observation보다 구조적 충실도(structural fidelity) 면에서 월등히 우수함을 입증했다. agent의 많은 실패 원인은 자원 부족이 아니라 중도 포기(premature stopping)에 있었으며, 간단한 검증(verification) 단계 추가만으로도 4-node 환경에서 정확도를 48%에서 60%로 향상시킬 수 있었다.
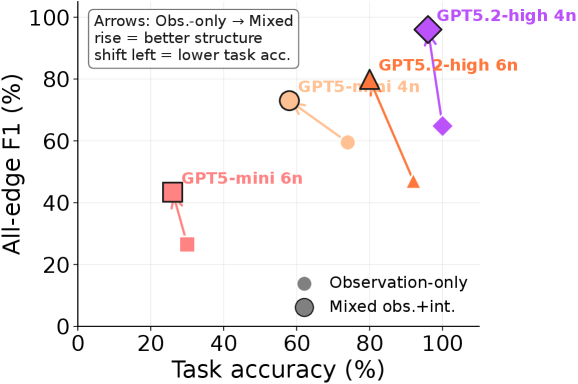
Figure 3 — 예측과 복원 성능 격차
4. Conclusion & Impact (결론 및 시사점)
본 논문은 CausaLab을 통해 LLM agent의 예측 성공과 인과적 이해 사이의 괴리를 성공적으로 분리해냈으며, 현재 모델들이 대화형 실험 환경에서 가설을 검증하고 수정하는 데 한계가 있음을 입증했다. 이 연구는 AI scientist의 인과적 사고력을 평가하는 새로운 프레임워크를 제시하며, 향후 과학적 발견을 위한 자율 agent 개발에 있어 필수적인 평가 지표와 방법론을 제공한다. 본 연구는 학계의 인과 추론 벤치마크 설계 방식을 정적인 데이터셋 중심에서 역동적인 실험 루프 중심으로 전환하는 데 기여할 것으로 기대된다.
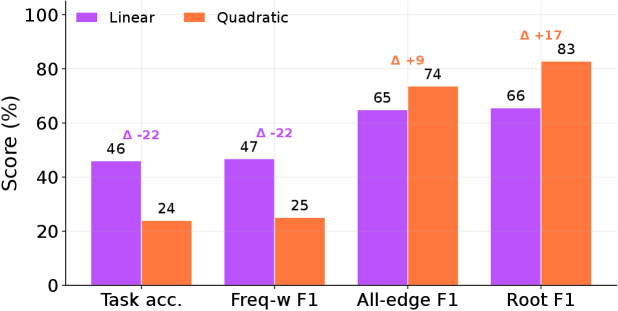
Figure 2 — 메커니즘 유형별 성능 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] AIRS-Bench: a Suite of Tasks for Frontier AI Research Science Agents
- [논문리뷰] Project Ariadne: A Structural Causal Framework for Auditing Faithfulness in LLM Agents
- [논문리뷰] Tracing Agentic Failure from the Flow of Success
- [논문리뷰] CausalDS: Benchmarking Causal Reasoning in Data-Science Agents
- [논문리뷰] Automating the Design of Embodied Agent Architectures
Review 의 다른글
- 이전글 [논문리뷰] Beyond 3D VQAs: Injecting 3D Spatial Priors into Vision-Language Models for Enhanced Geometric Reasoning
- 현재글 : [논문리뷰] CausaLab: A Scalable Environment for Interactive Causal Discovery Toward AI Scientists
- 다음글 [논문리뷰] ChildVox: A Speech, Audio, and Large Audio-Language Model Benchmark in Understanding and Characterizing Sound across Childhood
댓글