[논문리뷰] ChildVox: A Speech, Audio, and Large Audio-Language Model Benchmark in Understanding and Characterizing Sound across Childhood
링크: 논문 PDF로 바로 열기
저자: Tiantian Feng, Anfeng Xu, Xuan Shi, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- ChildVox: 아동 발달 전 과정을 포괄하는 음성, 오디오 및 Large Audio-Language Model(LALM)을 평가하기 위한 통합 벤치마크 프레임워크입니다.
- Physiological Sounds: 심장 박동이나 호흡음과 같이 아동의 신체적 건강 상태를 파악할 수 있는 비언어적 생체 신호를 의미합니다.
- Canonical Syllables: 초기 언어 발달 단계에서 나타나는 잘 형성된 자음-모음 결합 형태의 소리를 의미합니다.
- LALMs (Large Audio-Language Models): 다양한 오디오 입력을 언어 모델과 결합하여 이해하고 추론하는 멀티모달 모델(예: Qwen2-Audio, AudioFlamingo 3)입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 아동 음성 처리 연구들이 일반적인 ASR(Automatic Speech Recognition)에만 편중되어 있어, 아동 발달 과정의 핵심인 비언어적 의사소통 신호를 충분히 포착하지 못하는 한계를 해결하고자 합니다. 기존 모델들은 성인 데이터 위주로 학습되어 아동의 발달적 음향 변동성이나 언어 발달 수준에 따른 차이를 분석하는 데 어려움을 겪습니다. 또한, 생리학적 소리나 발성 패턴 등 아동의 상태를 반영하는 중요한 신호들이 연구 영역에서 소외되어 있습니다. 이러한 문제를 극복하기 위해 저자들은 아동의 생애 전반에 걸친 다양한 음성 신호를 통합적으로 다루는 ChildVox 벤치마크를 제안합니다. [Figure 1]에서 보여주듯, 이는 단순한 음성 인식을 넘어 생리학적 소리부터 학령기 아동의 사회적 의사소통까지 포함하는 포괄적인 접근을 시도합니다.
Figure 1 — ChildVox가 다루는 4가지 핵심 소리 카테고리와 아동 발달 단계 간의 관계를 시각화한 전체 프레임워크 다이어그램
## 3. Method & Key Results (제안 방법론 및 핵심 결과)
ChildVox는 17개의 아동 중심 데이터셋을 통합하여 20개 이상의 서브 태스크를 수행하는 일관된 평가 프로토콜을 구축했습니다. 방법론적으로는 Encoder-based 모델(SSAST, WavLM, Whisper)과 LALMs를 활용하며, 데이터 효율적인 학습을 위해 모든 모델에 LoRA(Low-Rank Adaptation)를 적용하여 미세 조정(Fine-tuning)을 수행하였습니다. 핵심 결과로서, Whisper-Large 모델은 음성 인식 및 화자 분할(Speaker Diarization)에서 14.80 WER(MyST 데이터셋 기준) 및 17.70 DER(NLS 데이터셋 기준)의 우수한 성능을 입증했습니다. [Table 3]의 벤치마크 성능 분석 결과에 따르면, WavLM-Large는 생리학적 음향 분석에서, SSAST는 초기 발성 분류에서 독보적인 성능을 나타내어 모델의 사전 학습 목적(Pre-training Objectives)이 하위 태스크에 보완적인 영향을 미침을 확인했습니다. 반면, Qwen2-Audio는 전반적인 이해도에서 기존 전문 모델들과 대등한 성능을 보였으나, AudioFlamingo 3는 특정 태스크에서 일관성 없는 지시 수행 문제를 보였습니다. [Figure 4]에서 확인 가능한 것처럼, ChildVox로 학습된 전문 모델들은 일반 목적의 Gemini 2.5/3.5 Flash와 같은 제로샷 모델들보다 모든 아동 관련 태스크에서 압도적인 정확도를 보여주었습니다.
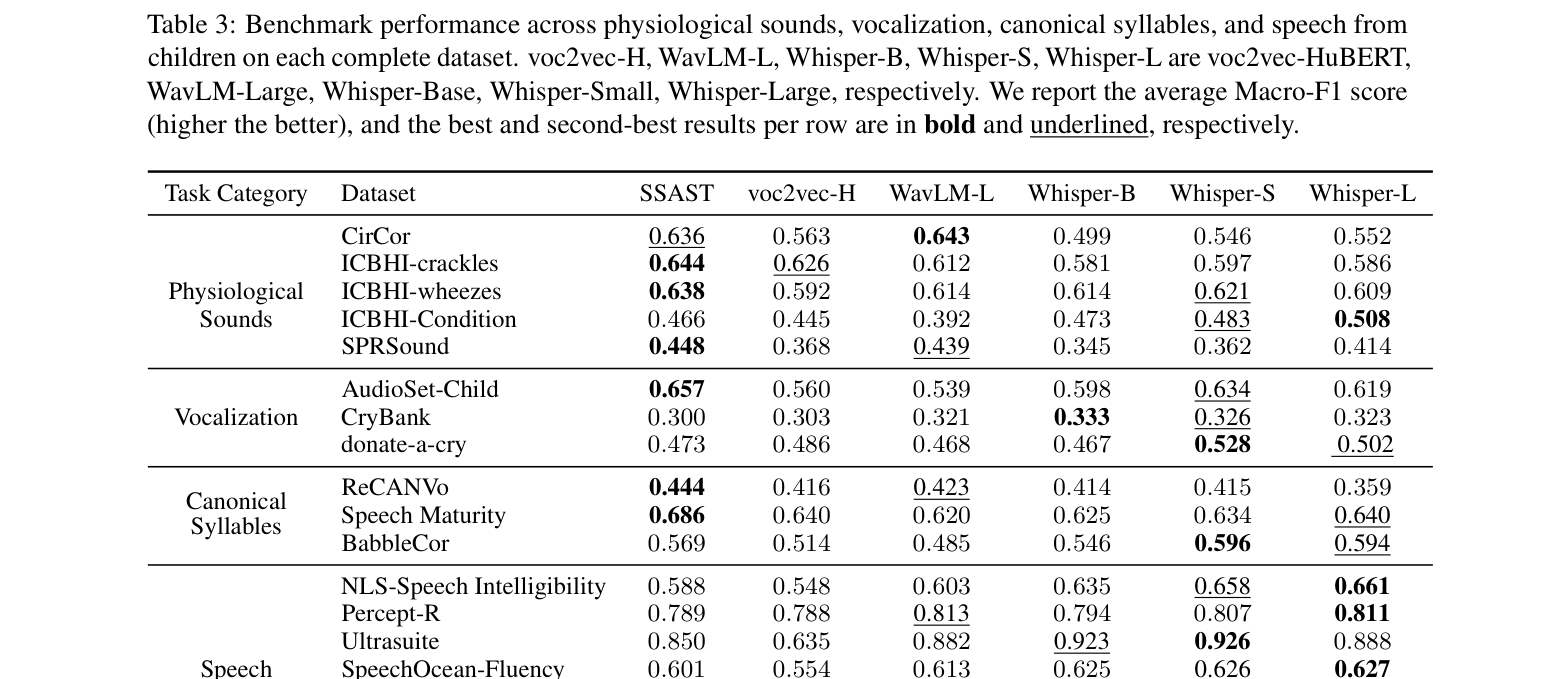
Table 3 — 다양한 encoder-based 모델들이 4개 카테고리 14개 서브 태스크에서 거둔 Macro-F1 성능 결과를 비교한 핵심 결과 테이블
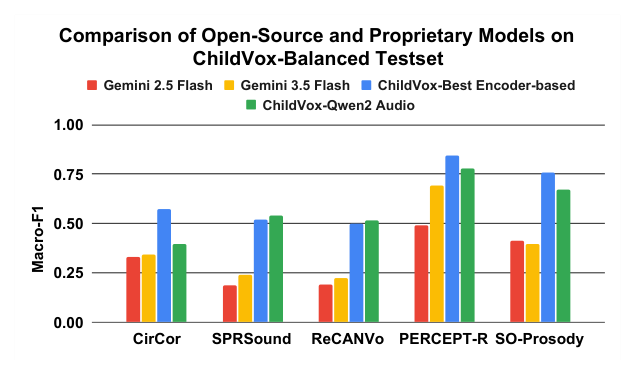
Figure 4 — ChildVox 학습 모델과 상용 모델(Gemini)의 성능 격차를 명확히 보여주는 비교 그래프
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 아동의 발달적 궤적을 반영한 포괄적 오디오 벤치마크인 ChildVox를 도입함으로써 아동 중심 오디오 인텔리전스 분야의 새로운 기준을 제시합니다. 연구 결과는 아동의 비언어적 소리와 언어적 발달을 추적하는 데 있어 맞춤형 학습된 모델이 일반 목적의 거대 모델보다 훨씬 효율적임을 시사합니다. 향후 ChildVox는 아동의 초기 발달 장애 선별, 언어 치료 모니터링, 그리고 정밀 교육 분야에서 중추적인 분석 도구로 활용될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Tadabur: A Large-Scale Quran Audio Dataset
- [논문리뷰] PRiSM: Benchmarking Phone Realization in Speech Models
- [논문리뷰] Hearing to Translate: The Effectiveness of Speech Modality Integration into LLMs
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] xHC: Expanded Hyper-Connections
Review 의 다른글
- 이전글 [논문리뷰] CausaLab: A Scalable Environment for Interactive Causal Discovery Toward AI Scientists
- 현재글 : [논문리뷰] ChildVox: A Speech, Audio, and Large Audio-Language Model Benchmark in Understanding and Characterizing Sound across Childhood
- 다음글 [논문리뷰] CoHyDE: Iterative Co-Training of LLM Rewriter & Dense Encoder for Tool Retrieval
댓글