[논문리뷰] CoHyDE: Iterative Co-Training of LLM Rewriter & Dense Encoder for Tool Retrieval
링크: 논문 PDF로 바로 열기
메타데이터
저자: Vaishali Senthil, Ashutosh Hathidara, Sebastian Schreiber, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Tool Retrieval: 거대한 API 카탈로그에서 사용자 쿼리와 의미적으로 가장 관련성 높은 도구를 선택하여 LLM 에이전트에게 제공하는 핵심 프로세스.
- HyDE (Hypothetical Document Embeddings): 질문에 대해 LLM이 가상의 문서를 생성하고, 이를 dense encoder를 통해 임베딩하여 유사도 검색을 수행하는 방식.
- DPO (Direct Preference Optimization): LLM의 출력 결과가 특정 보상 모델(여기서는 encoder의 retrieval score)을 더 잘 따르도록 직접 최적화하는 학습 기법.
- InfoNCE: 대조 학습(contrastive learning)에서 긍정 샘플과 부정 샘플 간의 거리를 최적화하여 특징 표현(representation)을 학습시키는 손실 함수.
- Vague-query: 구체적인 API 용어가 결여된 일상적인 언어로 구성되어, 검색 시스템의 강건성(robustness)을 시험하는 난이도 높은 쿼리.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM 에이전트의 tool retrieval 과정에서 발생하는 성능 병목 문제를 해결하기 위해 CoHyDE를 제안한다. 기존의 도구 검색 방식은 dense encoder를 미세 조정(fine-tuning)하거나 frozen LLM 기반의 HyDE를 사용하는 두 가지로 나뉘는데, 이들은 각각 치명적인 한계를 가진다 [Figure 1]. 미세 조정된 인코더는 쿼리가 카탈로그와 유사한 용어를 공유할 때는 뛰어나지만, 용어가 달라지면 성능이 급격히 저하되는 취약성을 보인다. 반면, HyDE는 도구 카탈로그에 대한 지식이 부족한 가상의 설명을 생성하여, 명확한 쿼리에 대해서는 오히려 성능을 저하시킨다. 저자들은 이 두 방식을 독립적으로 학습시켜 결합할 경우, 표현 공간(representation space)의 불일치로 인해 오히려 검색 품질이 악화된다는 점을 밝혀냈다.
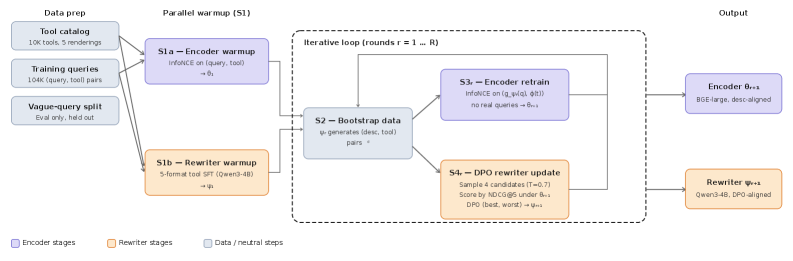
Figure 1 — CoHyDE 전체 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 dense encoder와 LLM rewriter를 단일 시스템으로 공동 학습(co-training)시키는 CoHyDE를 제안한다 [Figure 1]. 각 라운드에서 LLM은 쿼리를 기반으로 카탈로그 지향적인 가상 설명(hypothetical description)을 생성하며, 인코더는 이를 InfoNCE 손실 함수를 통해 학습하여 표현력을 강화한다. 동시에, rewriter는 인코더의 NDCG@5 검색 결과를 보상 신호로 사용하여 DPO를 통해 인코더에 최적화된 출력을 생성하도록 정렬(alignment)된다. 실험 결과, 3번의 공동 학습을 거친 CoHyDE는 가장 강력한 단일 구성 요소 기준 모델(BGE fine-tuning) 대비 표준 쿼리에서 +2.5 pp, 난이도가 높은 vague 쿼리에서는 +6.3 pp의 NDCG@5 향상을 달성하였다 [Table 1]. 특히 가장 어려운 vague tier에서는 +8 pp 이상의 비약적인 성능 향상을 보였다 [Figure 2]. 이는 인코더가 학습 과정에서 실제 쿼리를 보지 않고도 rewriter의 출력을 통해 최적의 매핑 공간을 학습했음을 시사한다 [Table 2].
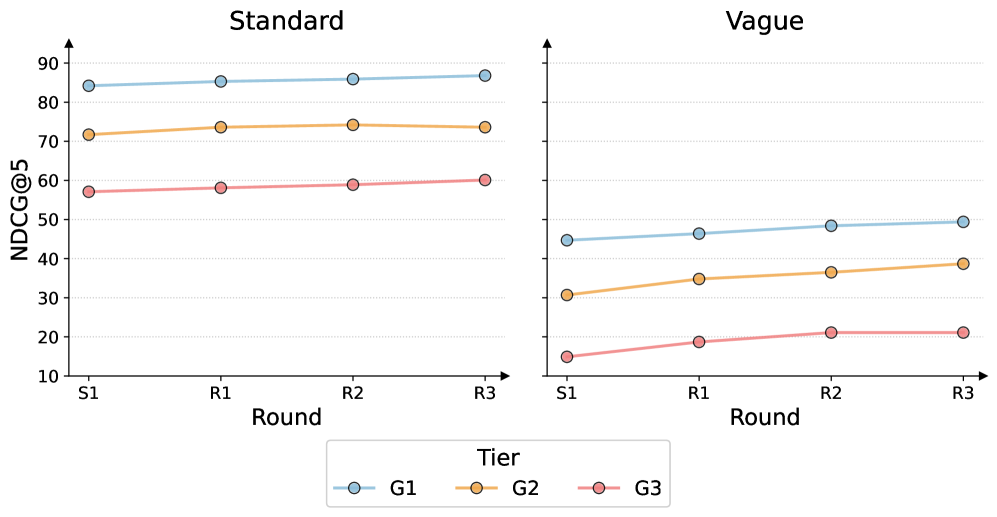
Figure 2 — 학습 라운드별 성능 향상
4. Conclusion & Impact (결론 및 시사점)
본 논문은 dense encoder와 LLM rewriter를 공동 진화시키는 CoHyDE 프레임워크가 tool retrieval의 성능 한계를 돌파할 수 있음을 입증했다. 이 연구는 독립적인 시스템 컴포넌트의 단순 조합이 아닌, 공동의 최적화를 통해 표현 공간의 불일치를 해결해야 한다는 중요한 통찰을 제시한다. 학계 및 산업계에서 거대 API 카탈로그를 다루는 LLM 에이전트의 효율성을 극대화하는 데 핵심적인 방법론적 토대를 마련한 것으로 평가된다. 향후 연구에서는 더 다양한 도메인과 복잡한 함수 호출 스키마에 대한 일반화 능력을 검증할 필요가 있다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] PalmClaw: A Native On-Device Agent Framework for Mobile Phones
- [논문리뷰] ResearchStudio-Idea: An Evidence-Grounded Research-Ideation Skill Suite from ML Conference Outcomes
- [논문리뷰] SkillHone: A Harness for Continual Agent Skill Evolution Through Persistent Decision History
- [논문리뷰] LectūraAgents: A Multi-Agent Framework for Adaptive Personalized AI-Assisted Learning and Embodied Teaching
- [논문리뷰] HarnessBridge: Learnable Bidirectional Controller for LLM Agent Harness
Review 의 다른글
- 이전글 [논문리뷰] ChildVox: A Speech, Audio, and Large Audio-Language Model Benchmark in Understanding and Characterizing Sound across Childhood
- 현재글 : [논문리뷰] CoHyDE: Iterative Co-Training of LLM Rewriter & Dense Encoder for Tool Retrieval
- 다음글 [논문리뷰] CollectionLoRA: Collecting 50 Effects in 1 LoRA via Multi-Teacher On-Policy Distillation
댓글