[논문리뷰] HarnessBridge: Learnable Bidirectional Controller for LLM Agent Harness
링크: 논문 PDF로 바로 열기
저자: Xiaoxuan Wang, Haixin Wang, Alexander Taylor, Jason Cong, Yizhou Sun, Wei Wang
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Harness: LLM agent의 입출력을 매개하고, 환경과 상호작용하며 도구 호출이나 동작 검증을 수행하는 인터페이스 시스템을 지칭합니다.
- Observation Projection: Raw trajectory history를 요약하여 모델이 처리하기 적합한 decision-relevant state로 변환하는 기술입니다.
- Action Projection: 모델이 제안한 action을 검토하여, 환경에 실행할지 혹은 궤적에 근거한(trajectory-grounded) 피드백과 함께 거부(Reject)할지 결정하는 메커니즘입니다.
- Active-State Index: Observation projection의 결과물 중 하나로, unresolved errors, open constraints, established facts 등 모델이 현재 추론 과정에서 반드시 기억해야 할 핵심 정보를 별도로 인덱싱한 블록입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 기존의 수동으로 설계된(manually engineered) Harness가 복잡하고 긴 호흡의(long-horizon) 과제에서 비효율적인 상호작용을 초래하는 문제를 해결하고자 합니다. 기존 방식은 불필요한 컨텍스트가 누적되어 토큰 비용을 급증시키거나, 모델이 비효율적인 행동을 반복하게 만드는 한계가 있습니다. 이러한 수동 인터페이스는 최적화의 대상이 아닌 고정된 인프라로 취급되어 왔기 때문에, 환경과 모델 간의 흐름을 능동적으로 조절하는 체계적인 학습 정책(learning policy)이 부족한 상태입니다. 본 연구는 HarnessBridge를 도입하여 이러한 상호작용의 흐름을 End-to-End로 학습 가능한 문제로 재정의합니다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과) HarnessBridge는 agent와 환경 간의 인터페이스를 양방향 투영(bidirectional projection) 정책인 πh로 매개하는 학습 가능한 컨트롤러를 제안합니다. 이 모델은 Observation Projection을 통해 trajectory를 압축하고, Action Projection을 통해 무의미한 환경 상호작용을 제어함으로써 모델이 과제 해결에 집중하도록 유도합니다.
실험 결과, HarnessBridge는 다양한 벤치마크 환경에서 강력한 성능을 입증했습니다. SWE-bench Verified 및 Terminal-Bench 2.0에서 Qwen3.5-35B-A3B 모델을 사용했을 때, 기존 Terminus 2 대비 성공률(SR)은 최대 11.2% 포인트 상승하였으며, 평균 토큰 사용량은 42.4%에서 77% 이상 획기적으로 감소했습니다. [Table 1]은 다양한 모델 백본 환경에서 본 방법론이 토큰 효율성과 과제 성공률 측면에서 baseline들을 압도함을 보여줍니다. 또한, [Figure 5]를 통해 baseline 대비 상호작용 턴 수와 토큰 소비량이 모든 결과 카테고리에서 일관되게 감소함을 확인할 수 있습니다.
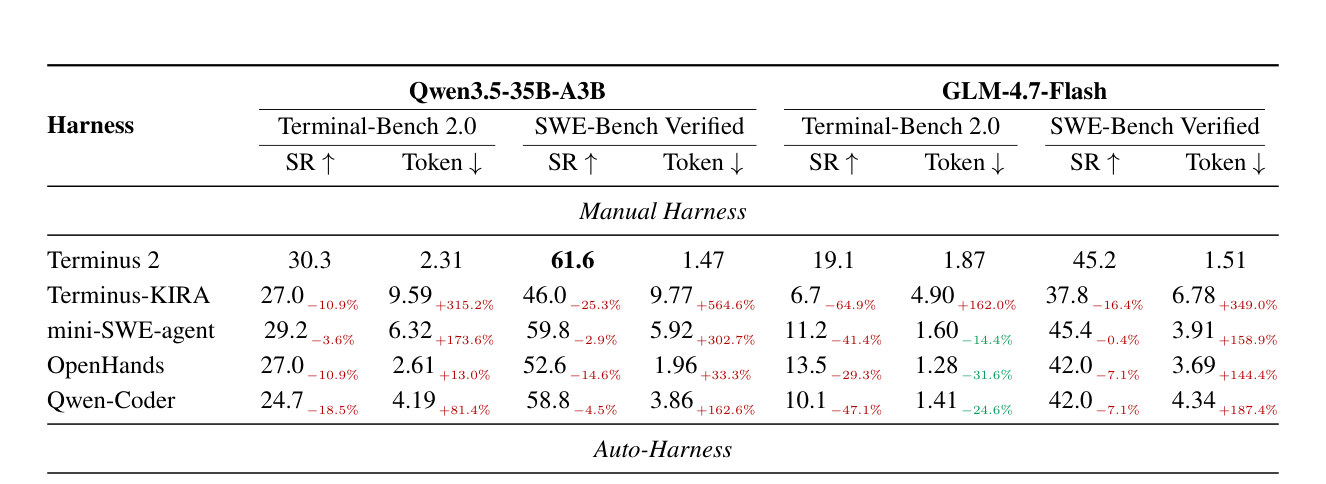
Table 1 — 다양한 모델 백본(Qwen3.5-35B-A3B, GLM-4.7-Flash)에서 기존 Harness들 대비 HarnessBridge의 우수한 성공률 및 토큰 효율성을 입증하는 핵심 결과 표
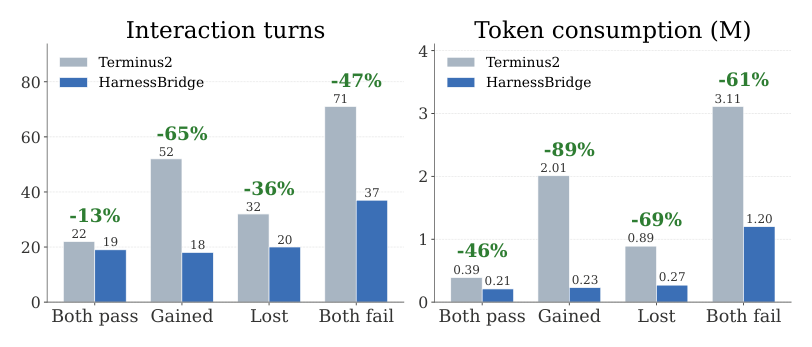
Figure 5 — Baseline 대비 상호작용 턴 수와 토큰 소비량이 카테고리별로 어떻게 개선되었는지 보여주는 결과 비교 그래프
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 Harness를 고정된 인프라에서 최적화 가능한 정책으로 전환함으로써 agent 시스템의 효율성과 성능을 동시에 확보하는 새로운 패러다임을 제시했습니다. HarnessBridge는 작은 크기의 모델로 학습된 정책이 더 큰 상업적 모델로도 일반화(generalization)될 수 있음을 증명하여, 실무적인 agent 배포 환경에서의 비용 최적화에 기여할 것으로 기대됩니다. 본 방법론은 코드 생성 과제를 넘어 웹 내비게이션이나 일반적인 tool-use agentic domains로 확장될 수 있는 범용적인 프레임워크를 제공합니다.

Figure 1 — 전체 프레임워크인 HarnessBridge의 양방향 투영 및 인터페이스 메커니즘을 시각화한 핵심 다이어그램
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Bayesian-Agent: Posterior-Guided Skill Evolution for LLM Agent Harnesses
- [논문리뷰] Lean4Agent: Formal Modeling and Verification for Agent Workflow and Trajectory
- [논문리뷰] SIA: Self Improving AI with Harness & Weight Updates
- [논문리뷰] Unsupervised Skill Discovery for Agentic Data Analysis
- [논문리뷰] Crafter: A Multi-Agent Harness for Editable Scientific Figure Generation from Diverse Inputs
Review 의 다른글
- 이전글 [논문리뷰] HYDRA-X: Native Unified Multimodal Models with Holistic Visual Tokenizers
- 현재글 : [논문리뷰] HarnessBridge: Learnable Bidirectional Controller for LLM Agent Harness
- 다음글 [논문리뷰] High-Fidelity Two-Step Image Generation via Teacher-Aligned End-to-End Distillation
댓글