[논문리뷰] Bayesian-Agent: Posterior-Guided Skill Evolution for LLM Agent Harnesses
링크: 논문 PDF로 바로 열기
메타데이터
저자: Xiaojun Wu, Cehao Yang, Honghao Liu, Xueyuan Lin, Wenjie Zhang, Zhichao Shi, Xuhui Jiang, Chengjin Xu, Jia Li, Jian Guo, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Bayesian-Agent: LLM 에이전트의 재사용 가능한 Skill 및 SOP를 evidence-bearing 가설로 간주하여, verified trajectory를 바탕으로 posterior를 업데이트하고 최적의 작업을 수행하는 프레임워크.
- Harness: LLM 외부의 추론 환경(prompts, tools, memory, SOPs 등)을 의미하며, 모델의 가중치를 변경하지 않고 성능을 향상시키는 핵심 요소.
- Posterior-Guided Skill Actions: 모델의 Belief State(후험적 상태)를 기반으로 자동화된 5가지 작업(Patch, Split, Compress, Retire, Explore)을 수행하는 정책.
- Verified Trajectory Evidence: 외부 그레이더(grader)나 계약에 의해 성공/실패 여부가 명확히 검증된 작업 수행 과정(Trajectory).
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 heuristic한 방식이나 단순한 성공/실패 횟수에 의존하는 Agent Skill 업데이트가 비효율적이며, noisy한 편집으로 인해 오히려 성능 저하를 초래할 수 있다는 문제를 해결하고자 한다. 기존 에이전트 시스템은 Skill과 SOP를 관리할 때 LLM의 자기 성찰이나 임의의 빈도수에 의존하는데, 이는 sparse한 에이전트 trajectory를 적절히 반영하지 못한다. 저자들은 harness 내의 Skill이 특정한 task context에 따라 성공 여부가 달라질 수 있는 복합적인 요소임을 지적하며, 단순한 prompt accumulation을 넘어선 Bayesian 프레임워크 기반의 체계적인 Skill 최적화 방법론의 필요성을 강조한다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 재사용 가능한 Skill을 Bayesian evidence 객체로 정의하고, verified trajectory로부터 학습된 categorical posterior를 기반으로 Skill을 최적화하는 Bayesian-Agent 프레임워크를 제안한다 [Figure 1]. 저자들은 각 Skill의 성능을 P(yt=1 | Mθ, Ct, hk, zt)로 공식화하고, 실시간으로 수집된 trajectory로부터 성공 확률의 posterior를 업데이트한다. 이 Posterior를 기반으로 Patch, Split, Compress, Retire, Explore 중 최적의 액션을 수행하여 harness-side context를 조정한다 [Table 1]. 실험 결과, deepseek-v4-flash 모델 환경에서 incremental repair 방식을 적용했을 때, SOP-Bench 성능은 80%에서 95%로, Lifelong AgentBench는 90%에서 100%로, RealFin-Bench는 45%에서 65%로 유의미하게 향상되었다 [Table 2]. 특히 GenericAgent, mini-swe-agent, Claude Code 등 다양한 execution backend에서도 동일한 성능 개선을 확인하여 프레임워크의 범용성을 입증하였다 [Figure 2].
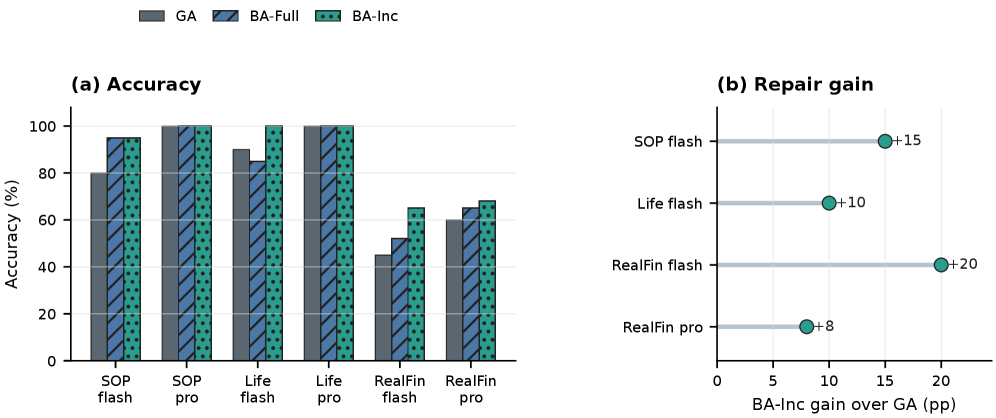
Figure 1 — Bayesian-Agent의 시각적 분석
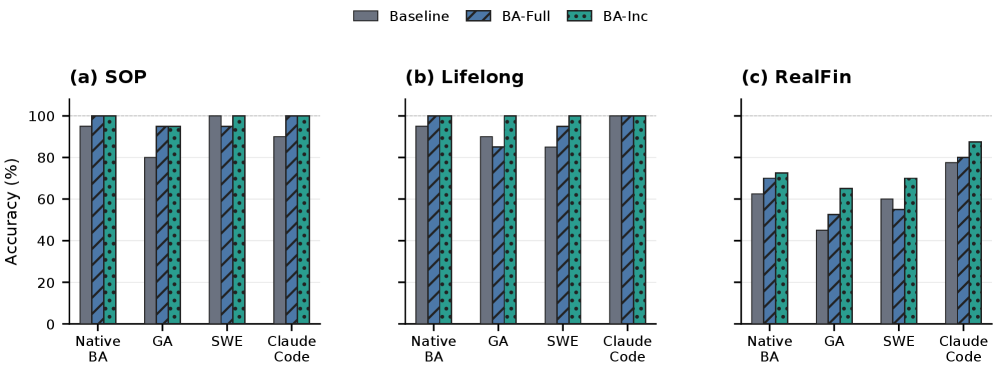
Figure 2 — 백엔드별 최종 정확도 비교
4. Conclusion & Impact (결론 및 시사점)
본 연구는 에이전트의 Skill 진화를 단순한 텍스트 수정이 아닌, posterior에 기반한 harness 최적화 문제로 재정의하였다. Bayesian-Agent는 verified evidence를 통해 데이터 효율적인 Skill 관리를 가능하게 함으로써, 에이전트의 반복적인 실패를 재사용 가능한 패치로 전환한다. 이 연구는 산업계의 복잡한 SOP 관리 및 학계의 lifelong agent 학습 분야에서 신뢰성 있는 에이전트 엔지니어링을 위한 새로운 방법론적 기반을 제공한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] HarnessBridge: Learnable Bidirectional Controller for LLM Agent Harness
- [논문리뷰] Skill-3D: Evolving Scene-Aware Skills for Agentic 3D Spatial Reasoning
- [논문리뷰] Lean4Agent: Formal Modeling and Verification for Agent Workflow and Trajectory
- [논문리뷰] SIA: Self Improving AI with Harness & Weight Updates
- [논문리뷰] OpenSkill: Open-World Self-Evolution for LLM Agents
Review 의 다른글
- 이전글 [논문리뷰] Answer Presence Drives RAG Rewriting Gains
- 현재글 : [논문리뷰] Bayesian-Agent: Posterior-Guided Skill Evolution for LLM Agent Harnesses
- 다음글 [논문리뷰] CIPER: A Unified Framework for Cross-view Image-retrieval and Pose-estimation
댓글