[논문리뷰] CIPER: A Unified Framework for Cross-view Image-retrieval and Pose-estimation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yurim Jeon, Dongseong Seo, Seung-Woo Seo
1. Key Terms & Definitions (핵심 용어 및 정의)
- Cross-view Geo-localization: 지상 이미지를 쿼리로 사용하여 위성/항공 이미지 데이터베이스에서 해당 위치와 정밀한 3-DoF pose를 추정하는 작업입니다.
- Dual-token Encoder: 공통 ViT 백본을 공유하면서, 각각 전역 검색을 위한
cls_token과 국소 위치 정보 보존을 위한pos_token을 사용하여 두 가지 작업을 동시에 최적화하는 구조입니다. - Two-way Transformer Decoder: Ground와 Aerial 이미지 특징 간의 상호작용을 위해 Bidirectional Cross-attention을 수행하여 도메인 간 간극을 효과적으로 줄이는 디코더 모듈입니다.
- Set Prediction: 고정된 단일 가설이 아닌, 다수의 후보 query를 통해 3-DoF pose를 추정하고 그중 신뢰도가 가장 높은 결과를 선택하여 회귀의 안정성을 높이는 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 Cross-view geo-localization 접근 방식인 이미지 검색(Image Retrieval)과 포즈 추정(Pose Estimation)이 별도의 파이프라인으로 운용되어 발생하는 비효율성을 해결하고자 합니다 [Figure 1]. 이미지 검색은 넓은 검색 범위를 제공하지만 위치 정밀도가 떨어지며, 포즈 추정은 정밀도는 높으나 제한된 검색 범위에 국한된다는 한계가 있습니다. 이를 단순히 결합(Cascading)할 경우, 중복된 특징 추출로 인한 연산 낭비와 불일치한 특징 표현이 발생합니다. 따라서 저자들은 전역 검색과 국소 위치 추정을 단일 아키텍처 내에서 동시에 처리하는 통일된 프레임워크가 필요하다고 주장합니다.
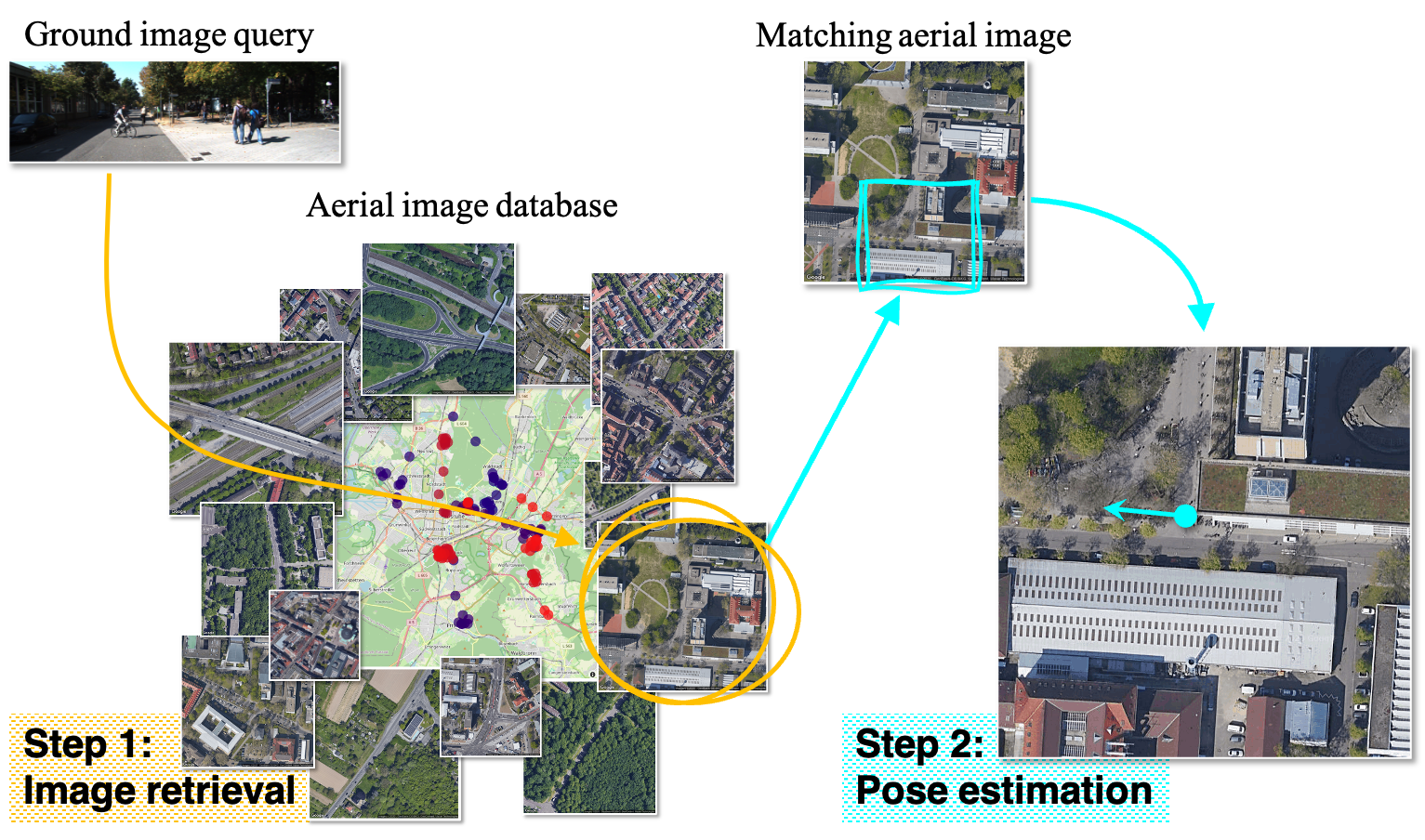
Figure 1 — 시나리오 정의
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 CIPER(Cross-view Image-retrieval and Pose-estimation transformER)를 제안하여 City-scale 검색과 고정밀 3-DoF 포즈 추정을 통합합니다 [Figure 2]. 제안 모델은 공유된 Vision Transformer 백본을 사용하여 전역 컨텍스트와 공간적 특징을 동시에 학습하며, 두 개의 학습 가능한 토큰을 통해 작업별 특성을 분리합니다. 특히 Two-way Transformer 기반의 포즈 디코더는 Ground 특징을 쿼리로, Aerial 특징을 메모리로 사용하여 Bidirectional Cross-attention을 수행함으로써 시점 변화에 강력한 정렬을 달성합니다 [Figure 3]. 실험 결과, CIPER는 VIGOR, KITTI, Ford Multi-AV 데이터셋에서 기존 방법론 대비 경쟁력 있는 성능을 입증했습니다. 특히 Orientation Prior가 없는(±180°) 까다로운 조건에서도 타 모델 대비 월등한 위치 및 방향 추정 정확도를 보여주었습니다 [Table 3, Table 4]. 또한, 통합 아키텍처를 통해 기존의 분리된 파이프라인 대비 연산 비용을 효율적으로 최적화하여 FLOPs를 현저히 감소시켰습니다 [Table 1].
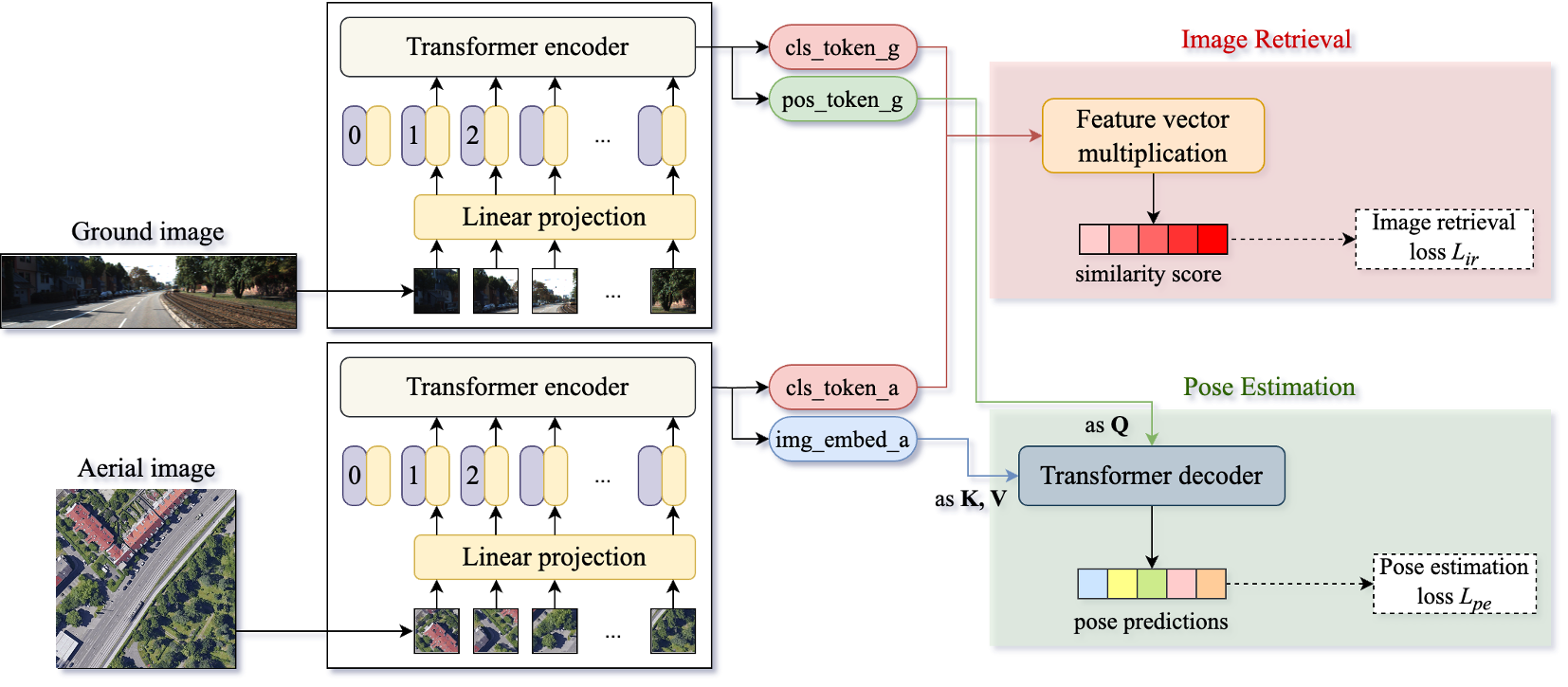
Figure 2 — CIPER 전체 아키텍처
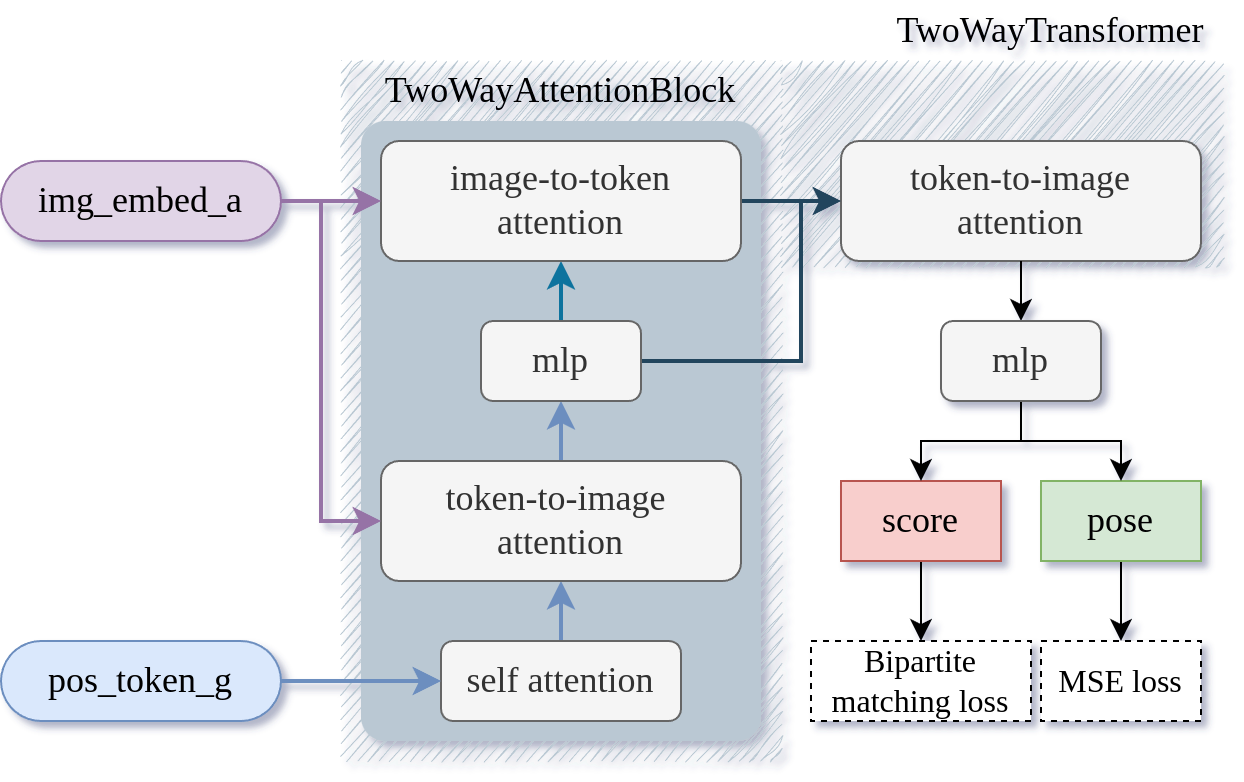
Figure 3 — 포즈 디코더 구조
4. Conclusion & Impact (결론 및 시사점)
CIPER는 검색과 포즈 추정이라는 이질적인 작업을 단일 네트워크 내에서 효율적으로 통합하여 실용적인 Cross-view geo-localization의 새로운 베이스라인을 제시합니다. 본 연구가 제안하는 작업 지향적 토큰 설계와 Bidirectional Cross-attention 구조는 복잡한 최적화 과정 없이도 고정밀 포즈 추정을 가능하게 합니다. 이러한 통합 접근 방식은 GPS-denied 환경에서의 로봇 내비게이션이나 자율 주행 등 실시간성이 중요한 산업 응용 분야에 큰 기여를 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] PixARMesh: Autoregressive Mesh-Native Single-View Scene Reconstruction
- [논문리뷰] WEAVER, Better, Faster, Longer: An Effective World Model for Robotic Manipulation
- [논문리뷰] MaskAlign: Token-Subset Representation Alignment for Efficient Diffusion Training
- [논문리뷰] Humanoid-GPT: Scaling Data and Structure for Zero-Shot Motion Tracking
- [논문리뷰] BA-T: An Iterative Transformer for Two-View Bundle Adjustment
Review 의 다른글
- 이전글 [논문리뷰] Bayesian-Agent: Posterior-Guided Skill Evolution for LLM Agent Harnesses
- 현재글 : [논문리뷰] CIPER: A Unified Framework for Cross-view Image-retrieval and Pose-estimation
- 다음글 [논문리뷰] Chiaroscuro Attention: Spending Compute in the Dark
댓글