[논문리뷰] Chiaroscuro Attention: Spending Compute in the Dark
링크: 논문 PDF로 바로 열기
메타데이터
저자: Prateek Kumar Sikdar, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Spectral Entropy: 토큰 표현의 복잡도를 측정하는 지표로, DCT Power Spectrum을 기반으로 계산됩니다. 이는 특정 토큰이 DCT mixing(낮은 복잡도)에 적합한지, 혹은 full self-attention(높은 복잡도)이 필요한지를 결정하는 이론적 기준이 됩니다.
- DCT(Discrete Cosine Transform) Mixing: Fourier 기반의 linear transform 기법으로, 토큰의 주파수 성분을 활용하여 O(d log d) 복잡도로 효율적인 토큰 믹싱을 수행합니다.
- Routing Collapse: 학습 과정에서 라우터가 특정 operator(예: RBF)를 지속적으로 거부하고 특정 operator 집합(예: DCT, Attention)에만 토큰을 할당하는 현상입니다. 본 논문에서는 이를 최적의 operator 조합을 찾아내는 발견적 메커니즘으로 해석합니다.
- CHIAR-Former: 각 토큰의 Spectral Entropy에 따라 DCT, RBF, 혹은 full self-attention 중 가장 적합한 operator로 라우팅하는 4-layer hybrid transformer 구조입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 표준 Transformer가 모든 토큰에 대해 일관되게 고비용의 O(n²d) self-attention을 적용하는 비효율성을 해결하고자 합니다. 저자들은 언어 데이터 내의 토큰 정보 밀도가 서로 다르다는 점에 착안하여, 간단한 토큰은 저비용의 spectral operator로, 복잡한 토큰은 고비용의 attention으로 처리하는 동적 라우팅 방식을 제안합니다. 기존의 approximation 방식이나 단순 skip 기법들은 토큰 단위의 이론적 근거가 부족하다는 한계가 있습니다. 이를 해결하기 위해 저자들은 Spectral Entropy를 기반으로 한 이론적 프레임워크를 도입합니다 [Figure 1].
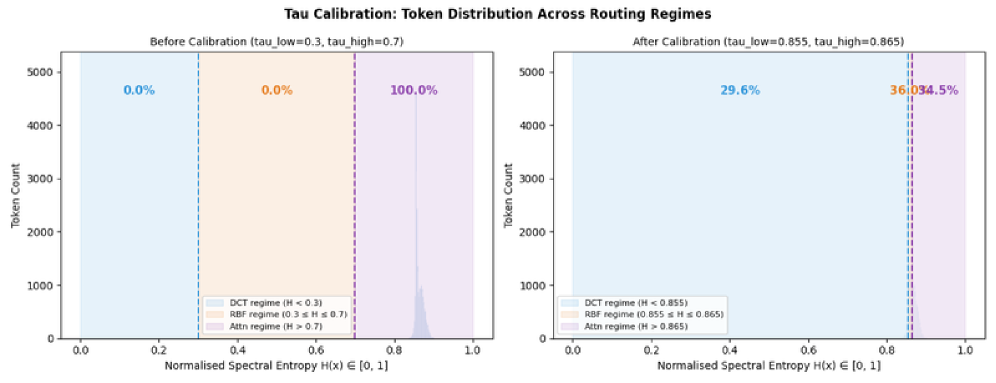
Figure 1 — Spectral Entropy 분포 변화
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 논문은 토큰의 Spectral Entropy를 계산하고, 이를 기반으로 DCT Mixing과 Full Self-Attention을 선택적으로 적용하는 CHIAR-Former 아키텍처를 제안합니다. 실험 결과, 학습 초기 단계에서 Routing Collapse 현상이 발생하여 RBF operator가 배제되고 DCT와 Attention 위주로 최적화됨을 확인하였습니다 [Figure 4]. 이러한 발견을 바탕으로 RBF를 완전히 제거한 DCT+Attn 모델을 설계한 결과, WikiText-103 데이터셋에서 Baseline 대비 Val PPL을 66.62에서 36.54로 약 45% 개선하면서도, attention FLOPs를 62.5% 감소시키는 성과를 거두었습니다 [Table 2]. 또한, 이러한 성능 향상은 토큰 다양성이 높은 대규모 데이터셋에서 더욱 두드러짐을 확인하였습니다 [Figure 2, Figure 5].
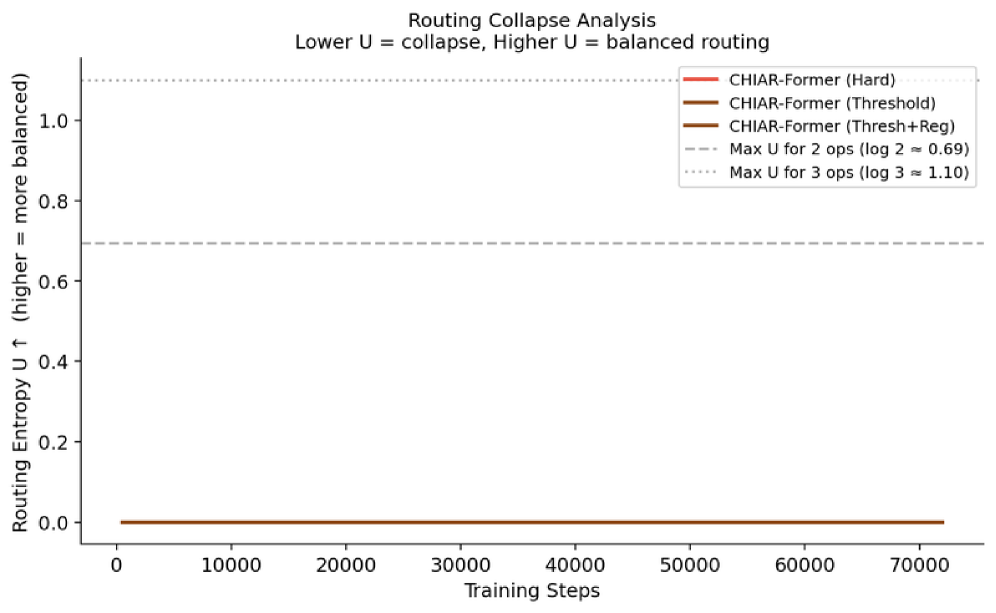
Figure 4 — 라우팅 collapse 현상 분석
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 고비용의 attention 연산을 효율적으로 대체하기 위해 토큰의 복잡도를 정량화하고 이를 구조적 라우팅에 활용할 수 있음을 입증했습니다. 특히, Routing Collapse를 학습 오류가 아닌 '최적의 연산 조합 발견'이라는 관점으로 전환한 점은 차세대 효율적 모델 설계에 중요한 시사점을 제공합니다. 향후 연구에서는 더 큰 규모의 모델과 다양한 토큰화 기법에서의 일반화 성능을 검증하는 것이 필수적입니다. 이 연구는 대규모 언어 모델의 추론 및 학습 비용을 절감하는 실용적인 경로를 제시합니다.
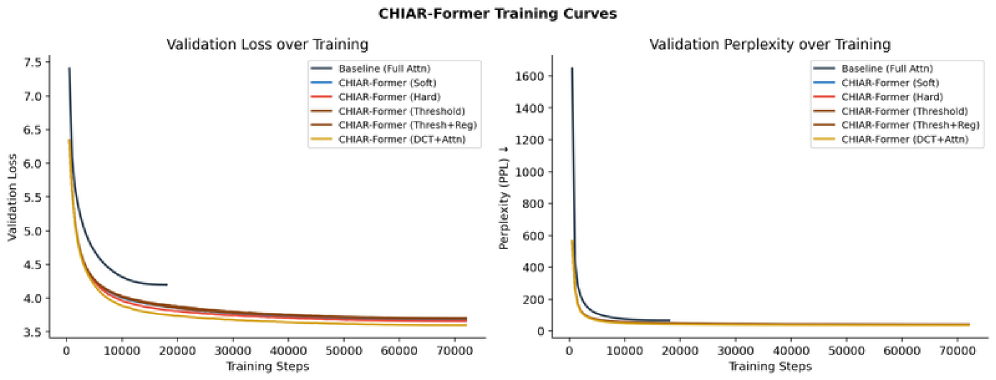
Figure 2 — 학습 과정의 PPL 수렴 결과
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Accelerating Masked Image Generation by Learning Latent Controlled Dynamics
- [논문리뷰] SkillOrchestra: Learning to Route Agents via Skill Transfer
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] Where, What, Why, and Importance: Structured Defect Grounding for Text-to-Image Feedback
- [논문리뷰] WeaveBench: A Long-Horizon, Real-World Benchmark for Computer-Use Agents with Hybrid Interfaces
Review 의 다른글
- 이전글 [논문리뷰] CIPER: A Unified Framework for Cross-view Image-retrieval and Pose-estimation
- 현재글 : [논문리뷰] Chiaroscuro Attention: Spending Compute in the Dark
- 다음글 [논문리뷰] CoVEBench: Can Video Editing Models Handle Complex Instructions?
댓글