[논문리뷰] CoVEBench: Can Video Editing Models Handle Complex Instructions?
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jiangtao Wu, Jiaming Wang, Yiwen He, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Compositional Video Editing: 단일 프롬프트 내에서 주체, 행동, 카메라 움직임 등 다수의 편집 작업을 동시에 수행해야 하는 고난도 비디오 편집 워크플로우를 의미합니다.
- Instruction Compliance: 모델이 사용자의 지시사항을 얼마나 정확하게 따르는지를 평가하는 지표로, IFS(Instruction Following Score), VRS(Video Realism Score), UAS(Union Accuracy)를 포함합니다.
- MLLM-based Evaluation: 최신 Multimodal Large Language Models를 활용하여 비디오의 편집 결과가 지시사항과 일치하는지, 시각적 품질과 물리적 사실성이 유지되는지를 자동으로 진단하는 평가 방식입니다.
- Fine-grained Checklist: 전체적인 결과뿐만 아니라 특정 편집 요소별로 성공 여부를 확인하기 위해 9,990개의 세부 질문 항목으로 구성된 진단 프레임워크입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 비디오 편집 벤치마크들이 단순하고 고립된 편집 작업에만 초점을 맞추어, 실제 사용자의 복잡한 편집 요구사항을 반영하지 못하는 한계를 해결하고자 합니다 [Figure 1]. 기존 모델 평가 방식은 coarse한 글로벌 메트릭(예: CLIP Score)에 의존하여, 복잡한 편집 과정에서 발생하는 세부적인 실패 사례를 진단하지 못합니다. 실제 환경에서는 다수의 편집 작업이 상호작용하기 때문에, 단순히 하나의 지시를 수행하는 것을 넘어 여러 작업을 동시에 처리하면서 관련 없는 컨텐츠를 보존하는 능력이 필수적입니다. 따라서 저자들은 실제 창작 워크플로우를 반영한 compositional video editing을 위한 체계적인 벤치마크인 CoVEBench를 제안합니다.
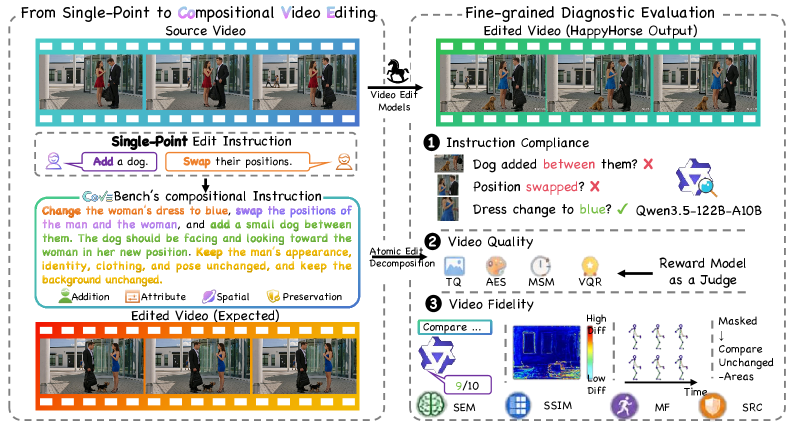
Figure 1 — 복잡한 비디오 편집 워크플로우
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 CoVEBench를 구축하기 위해 소스 비디오 수집, 복잡한 편집 지시문 생성, 그리고 검증 가능한 체크리스트 생성으로 이어지는 3단계 파이프라인을 설계했습니다 [Figure 2]. 제안된 CoVEBench는 416개의 소스 비디오와 626개의 다중 지점 편집 지시문을 포함하며, 이를 9,990개의 체크리스트 항목으로 세분화하여 평가합니다 [Table 1]. 실험 결과, 모델들은 편집 지시문의 복잡도가 증가함에 따라 성능이 급격히 하락하는 경향을 보였으며, 특히 다수의 편집 지시를 동시에 수행할 때 UAS 수치가 저조하게 나타났습니다 [Figure 4]. Wan2.7과 같은 closed-source 모델이 높은 UAS를 기록했지만, 전반적으로 모델들은 edit execution과 semantic preservation 사이의 트레이드오프 문제에 직면해 있습니다 [Table 3]. 또한, 순차적 편집보다 joint editing 방식이 품질과 효율성 측면에서 모두 우월함을 정량적으로 입증하였습니다.
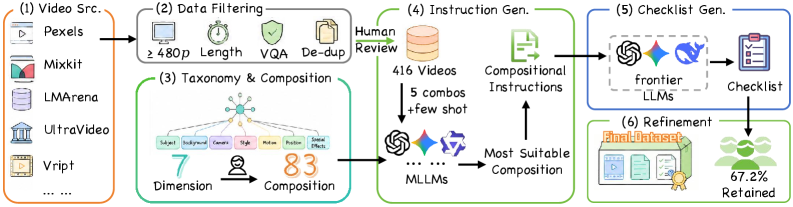
Figure 2 — CoVEBench 데이터 구축 파이프라인
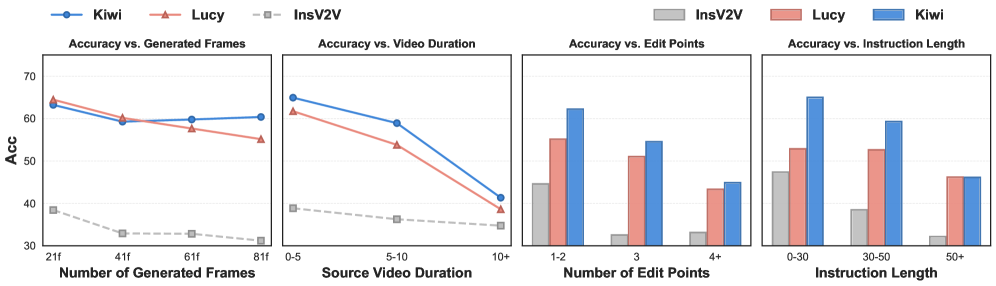
Figure 4 — 편집 복잡도에 따른 모델 강건성 분석
4. Conclusion & Impact (결론 및 시사점)
본 연구는 compositional video editing을 위한 새로운 벤치마크인 CoVEBench를 도입하여, 현존하는 비디오 편집 모델들의 복잡한 지시 수행 능력에 대한 엄격한 진단을 가능하게 했습니다. 연구 결과는 현재의 모델들이 다중 편집 작업에서 빈번하게 발생하는 artifact와 구조적 일관성 부족 문제를 안고 있음을 시사합니다. CoVEBench는 향후 연구자들이 실제 사용자의 실질적인 요구사항에 부합하는 고성능 비디오 편집 모델을 개발하는 데 있어 중요한 가이드라인과 테스트베드 역할을 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] OmniGameArena: A Unified UE5 Benchmark for VLM Game Agents with Improvement Dynamics
- [논문리뷰] WorldBench: A Challenging and Visually Diverse Multimodal Reasoning Benchmark
- [논문리뷰] When Tools Fail: Benchmarking Dynamic Replanning and Anomaly Recovery in LLM Agents
- [논문리뷰] MMAE: A Massive Multitask Audio Editing Benchmark
- [논문리뷰] GENEB: Why Genomic Models Are Hard to Compare
Review 의 다른글
- 이전글 [논문리뷰] Chiaroscuro Attention: Spending Compute in the Dark
- 현재글 : [논문리뷰] CoVEBench: Can Video Editing Models Handle Complex Instructions?
- 다음글 [논문리뷰] Cosine Misleads: Auxiliary Losses Reshape Vision Language Models, Not Their Latents
댓글