[논문리뷰] Beyond 3D VQAs: Injecting 3D Spatial Priors into Vision-Language Models for Enhanced Geometric Reasoning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Chun-Hsiao Yeh, Shengyi Qian, Manchen Wang, Yi Ma, Joseph Tighe, Fanyi Xiao, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- GASP (Geometric-Aware Spatial Priors): VLM의 LLM 백본 중간 레이어에 기하학적 사전 지식을 주입하여 공간적 추론 능력을 강화하는 제안된 훈련 프레임워크입니다.
- Visual Correspondence: 서로 다른 시점에서 촬영된 이미지들 사이에서 동일한 3D 위치를 지칭하는 시각적 포인트 간의 매칭을 의미합니다.
- Depth-Aware 3D Consistency: 3D 깊이 정보를 활용하여 시각적 대응 관계의 모호성을 해결하고 객체의 3D 물리적 일관성을 강제하는 감독 신호(supervision signal)입니다.
- PCK (Percentage of Correct Keypoints): 모델의 시각적 대응(correspondence) 정확도를 측정하기 위한 지표로, 예측된 매칭 지점이 정답(ground-truth)과 임계값 이내로 일치하는지 평가합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대의 Vision-Language Models(VLMs)가 3D 공간 추론에서 겪는 근본적인 한계를 해결하고자 합니다. 기존 연구들은 대규모 3D Visual Question-Answering(VQA) 데이터셋에 의존한 Fine-tuning 방식을 주로 사용하지만, 이는 모델이 특정 데이터셋의 편향(bias)을 암기하게 하여 일반화 능력을 저하시키는 결과를 초래합니다 [Figure 1]. 또한, 별도의 전문적인 3D 인코더를 통합하는 방식은 복잡성을 증가시키고 추론 Latency를 발생시킵니다. 저자들은 진정한 공간 이해가 고수준의 VQA supervision이 아닌, 기본적인 기하학적 Priors를 학습하는 것에서 비롯되어야 한다고 강조합니다.
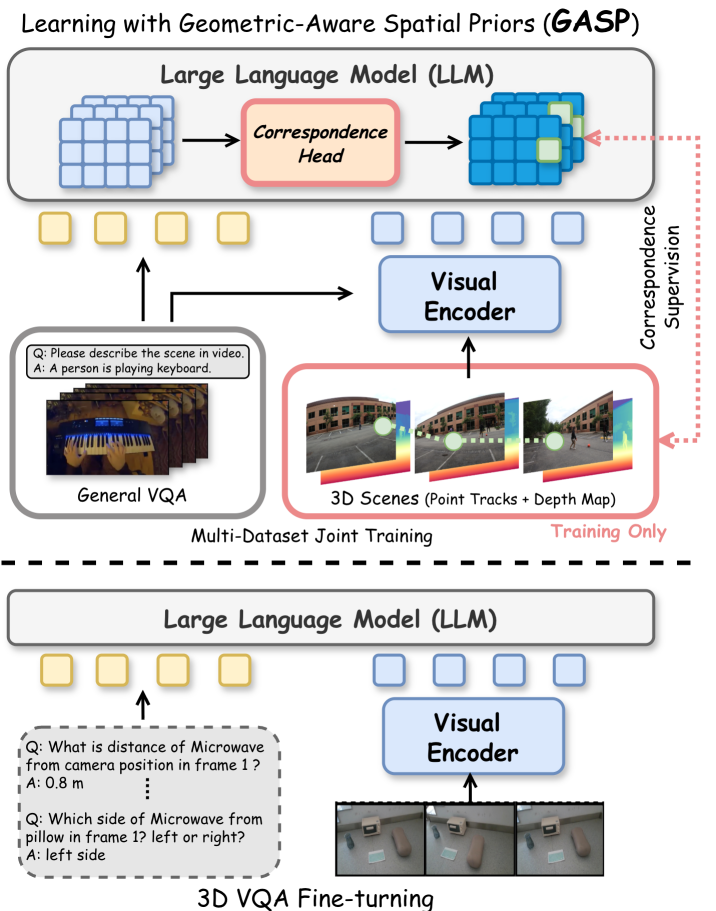
Figure 1 — GASP 프레임워크 개념도
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 LLM의 transformer 레이어 전반에 걸쳐 경량화된 correspondence head를 삽입하여 기하학적 일관성을 강제하는 GASP 프레임워크를 제안합니다 [Figure 2]. 이 head는 학습 단계에서만 사용되며, 3D 영상 데이터에서 도출된 point correspondence와 depth 정보를 이용해 Contrastive Loss 및 Depth Consistency Loss로 최적화됩니다. 실험 결과, GASP는 일반적인 VLM이 5% 미만으로 보였던 내부 correspondence matching 정확도를 70% 이상으로 대폭 향상시켰습니다 [Figure 3]. 또한, GASP는 별도의 3D VQA 데이터 학습 없이도 downstream 작업인 All-Angles Bench에서 카메라 포즈 추정 성능 +18.2%, VSI-Bench에서 객체 계수 성능 +29.0%의 정량적 개선을 달성했습니다 [Table 1]. 이러한 internal representation의 개선은 긴 시간적 거리(temporal range)에서도 85% 이상의 견고함을 유지하는 것으로 증명되었습니다 [Figure 3].
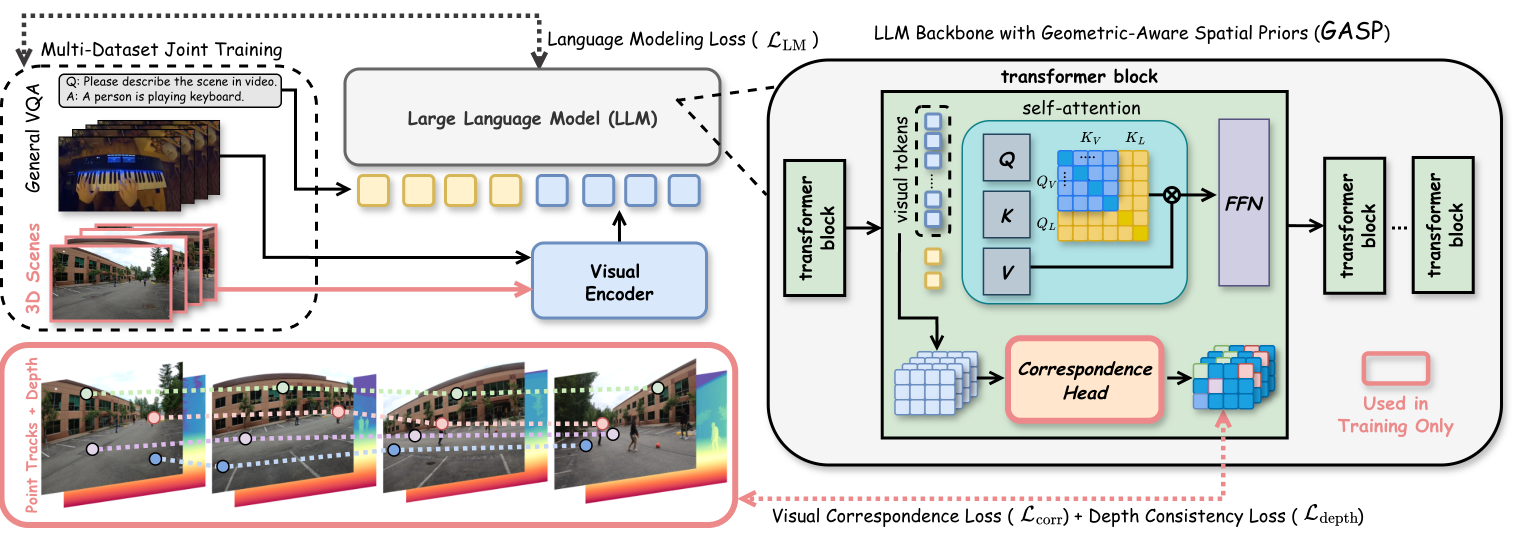
Figure 2 — GASP 상세 아키텍처
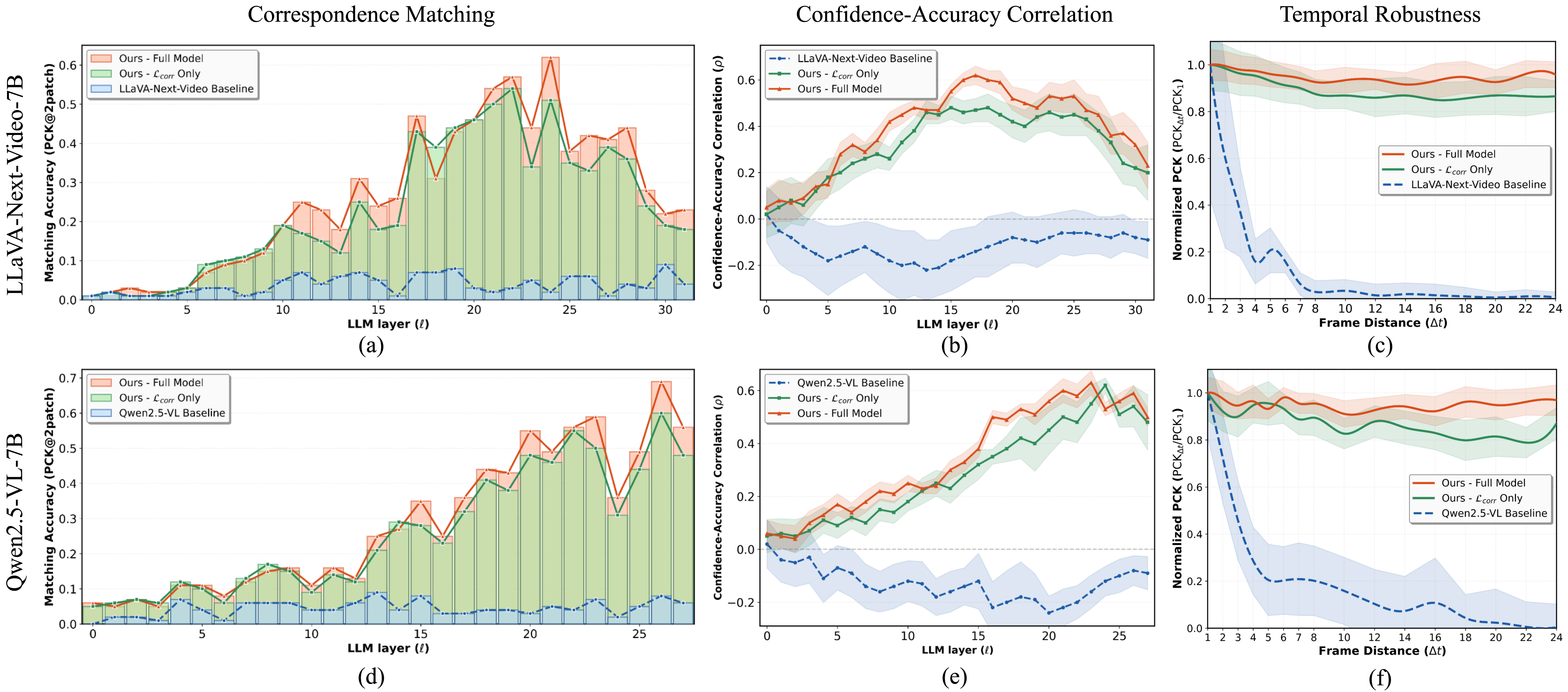
Figure 3 — 시각적 대응 학습 결과 분석
4. Conclusion & Impact (결론 및 시사점)
본 연구는 모델 내부의 시각적 표현에 기하학적 일관성을 주입하는 것만으로도 고수준의 공간적 추론 능력이 극적으로 개선될 수 있음을 증명했습니다. GASP는 복잡한 3D 특화 인코더 없이도 표준 VLM 아키텍처 내에서 효율적으로 공간적 지능을 학습할 수 있는 경로를 제시합니다. 이는 향후 로보틱스, 3D 이해, 그리고 더 신뢰성 있는 공간적 상호작용이 필요한 분야에서 범용 VLM의 적용 가능성을 크게 확대할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] VaseMuseum: Digital Intelligent Museum for Ancient Greek Pottery
- [논문리뷰] MedPMC: A Systematic Framework for Scaling High-Fidelity Medical Multimodal Data for Foundation Models
- [논문리뷰] Rank-Then-Act: Reward-Free Control from Frame-Order Progress
- [논문리뷰] Transition-Aware best-of-N sampling for Longitudinal Chest X-ray Reports
- [논문리뷰] DataComp-VLM: Improved Open Datasets for Vision-Language Models
Review 의 다른글
- 이전글 [논문리뷰] AsyncTool: Evaluating the Asynchronous Function Calling Capability under Multi-Task Scenarios
- 현재글 : [논문리뷰] Beyond 3D VQAs: Injecting 3D Spatial Priors into Vision-Language Models for Enhanced Geometric Reasoning
- 다음글 [논문리뷰] CausaLab: A Scalable Environment for Interactive Causal Discovery Toward AI Scientists
댓글