[논문리뷰] AsyncTool: Evaluating the Asynchronous Function Calling Capability under Multi-Task Scenarios
링크: 논문 PDF로 바로 열기
메타데이터
저자: Kou Shi, Ziao Zhang, Shiting Huang, Avery Nie, Zhen Fang, Qiuchen Wang, Lin Chen, Huaian Chen, Zehui Chen, Feng Zhao, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Asynchronous Tool Calling: 대기 시간이 존재하는 도구 호출(Tool call) 환경에서, 에이전트가 호출 결과를 기다리는 동안 유휴 시간을 활용하여 다른 태스크를 병렬적으로 처리하는 기능.
- Latency: 에이전트가 도구를 호출한 후 실제 결과값이 반환되기까지 소요되는 지연 시간.
- Multi-task Scenario: 단일 태스크 처리를 넘어, 여러 개의 서로 다른 태스크를 동시에 관리하고 실행해야 하는 복합적인 작업 환경.
- Dependency-aware Task Coordination: 태스크 간의 의존성과 순서를 고려하여, 도구 호출의 순서와 태스크 전환 시점을 전략적으로 결정하는 능력.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존 LLM 에이전트 연구들은 주로 단일 태스크 환경과 즉각적인 도구 응답을 가정하여 평가를 수행해왔습니다. 그러나 실제 환경에서는 도구 호출 시 지연 시간(latency)이 발생하며, 여러 태스크를 동시에 처리해야 하는 상황이 빈번합니다. 기존 연구들은 이러한 비동기적 상황에서의 시간적 차원(temporal dimension)과 효율적인 태스크 전환 능력을 간과하고 있습니다. 본 논문은 이러한 한계를 극복하기 위해 현실적인 지연 시간을 반영한 인터랙티브 다중 태스크 환경에서 에이전트의 수행 능력을 평가하는 벤치마크인 AsyncTool을 제안합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 기존 도구 호출 벤치마크인 NESTFUL과 BFCLv3를 기반으로, Hybrid Data Evolution 전략을 통해 다중 태스크 데이터셋을 구축했습니다[2.2.1]. 제안된 AsyncTool은 에이전트가 지연 시간 동안 태스크를 어떻게 전환하고 의존성을 관리하는지 평가하기 위해 Step Level, Sub-Task Level, Task Level의 3단계 평가 프로토콜을 도입했습니다[2.3]. 또한, 에이전트의 효율적인 태스크 인터리빙(interleaving) 행동을 측정하기 위해 Same-task Streak과 같은 지표를 활용합니다 [3.2]. 실험 결과, 지연 시간이 존재하는 환경에서 기존 에이전트들은 심각한 성능 저하를 보였으며, 특히 태스크 상태 관리와 의존성 추적 능력이 뛰어난 모델일수록 높은 효율성을 기록했습니다[3.2]. GPT-4.1은 높은 Overall Score(38.06)와 낮은 Same-task Streak을 유지하며 비동기적 태스크 스케줄링에서 가장 우수한 성능을 보였습니다 [2.3, 3.2].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 AsyncTool을 통해 LLM 기반 에이전트의 비동기적 도구 호출 능력을 체계적으로 평가할 수 있는 최초의 프레임워크를 제공합니다. 실험을 통해 에이전트가 단순히 태스크를 자주 전환하는 것만으로는 부족하며, 적절한 시점에 태스크를 전환하고 태스크 상태를 유지하는 시간적 조정(temporal coordination) 능력이 필수적임을 입증했습니다. 이 연구는 미래의 자율 에이전트가 복잡하고 현실적인 시간 제약 환경에서 보다 효율적이고 안정적으로 작동하도록 설계하는 데 중요한 가이드라인을 제시합니다[4].
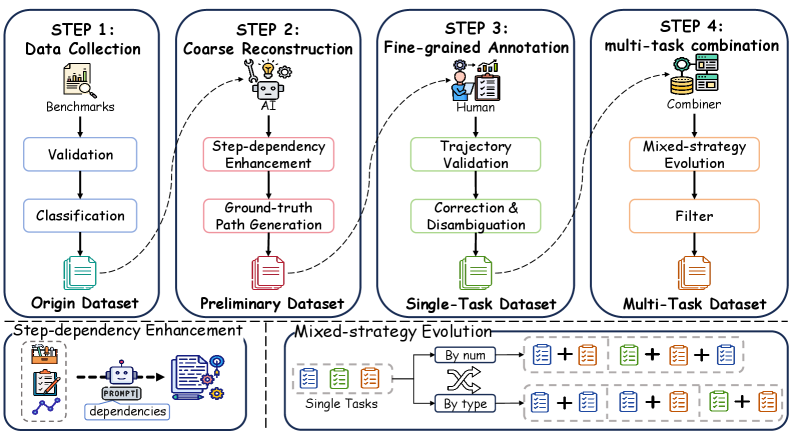
Figure 1 — 데이터셋 구축 프로세스 개요
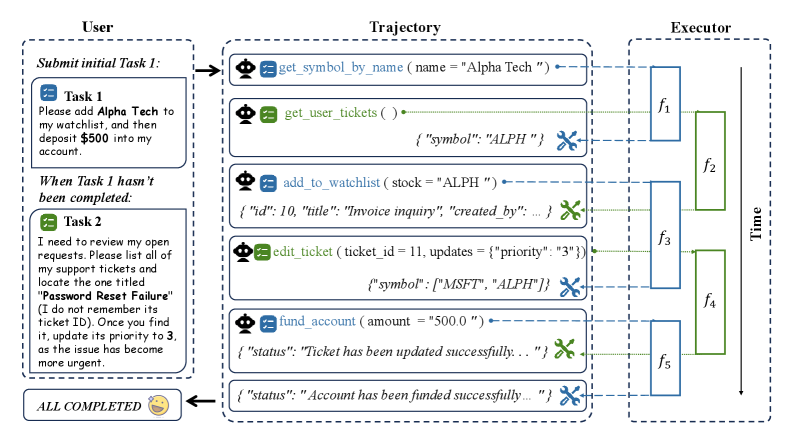
Figure 2 — 비동기 다중 태스크 도구 사용 예시
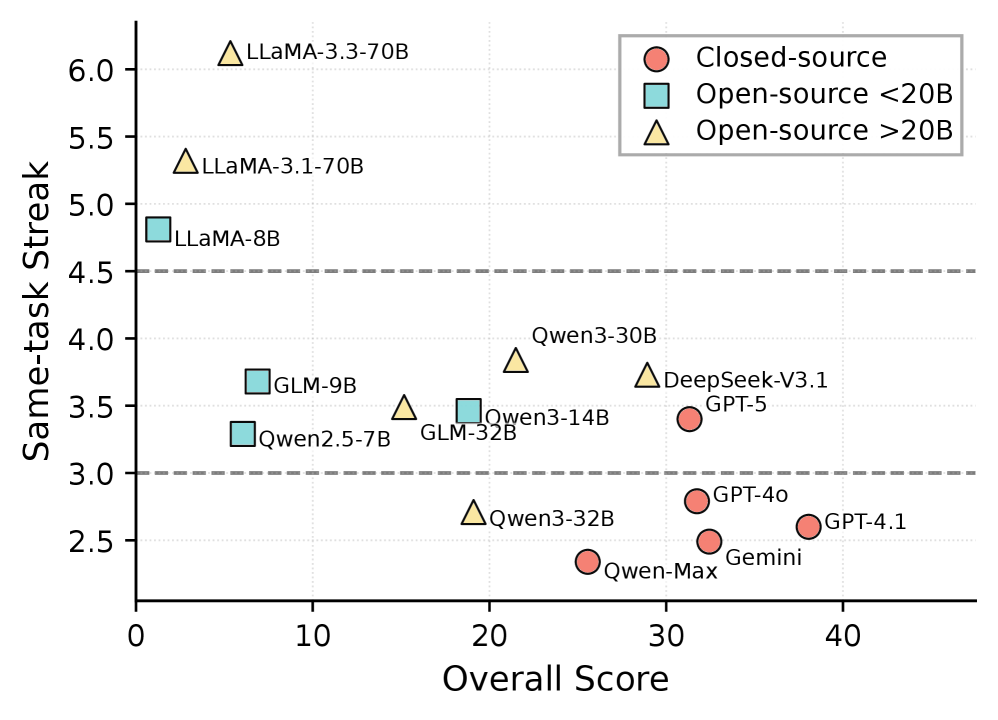
Figure 4 — 정확도와 효율성 간의 Trade-off
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Voice Evaluation of Reasoning Ability: Diagnosing the Modality-Induced Performance Gap
- [논문리뷰] LiveMCPBench: Can Agents Navigate an Ocean of MCP Tools?
- [논문리뷰] MultiRef-Compass: Towards Comprehensive Evaluation of Multi-Reference-to-Audio-Video Generation
- [논문리뷰] PalmClaw: A Native On-Device Agent Framework for Mobile Phones
- [논문리뷰] AdvancedMathBench: A Benchmark Suite for Advanced Mathematical Proof Generation and Verification
Review 의 다른글
- 이전글 [논문리뷰] Alignment Tampering: How Reinforcement Learning from Human Feedback Is Exploited to Optimize Misaligned Biases
- 현재글 : [논문리뷰] AsyncTool: Evaluating the Asynchronous Function Calling Capability under Multi-Task Scenarios
- 다음글 [논문리뷰] Beyond 3D VQAs: Injecting 3D Spatial Priors into Vision-Language Models for Enhanced Geometric Reasoning
댓글