[논문리뷰] Variable-Width Transformers
링크: 논문 PDF로 바로 열기
저자: Zhaofeng Wu, Oliver Sieberling, Shawn Tan, Rameswar Panda, Yury Polyanskiy, Yoon Kim
1. Key Terms & Definitions (핵심 용어 및 정의)
- > <former: 본 논문에서 제안하는 Variable-Width Transformer 아키텍처로, 층별로 서로 다른 Width(Hidden Dimension)를 가지며 ×-shaped 구조를 취함.
- Fixed-Residual Construction: 가변적인 층별 Width를 지원하기 위해 전체 모델의 Residual Stream 크기를 가장 넓은 층에 맞추고, 각 층이 필요한 만큼의 슬라이스만 읽고 쓰는 방식.
- Representation Collapse: Transformer의 중간 층에서 표현력(Representational Capacity)이 급격히 저하되어 모델의 출력이 퇴화하는 현상.
- FLOPs: 연산량의 단위로, 모델의 학습 및 추론 과정에서 발생하는 부동 소수점 연산 횟수.
- KV Cache: 추론 시 이전 토큰의 정보를 저장하는 메모리 버퍼로, Width가 커질수록 필요한 메모리 점유율도 선형적으로 증가함.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 대부분의 Transformer 모델이 모든 층에 걸쳐 일정한 Width를 유지하는 Uniform-Width 설계를 고수함으로써 발생하는 자원 비효율성 문제를 해결하고자 한다. 저자들은 층별로 수행하는 계산적 역할이 다름에도 불구하고 고정된 매개변수와 연산 예산을 균등하게 할당하는 것은 최적이 아니라고 주장한다. 기존 연구들은 주로 모델의 전체적인 Shape나 Depth 확장에 주목했으나, 층별로 동적인 Capacity를 할당하는 설계의 잠재력은 충분히 탐구되지 않았다. 이에 따라, 동일한 매개변수 예산 내에서 성능을 극대화하면서도 연산량과 메모리 요구량을 줄일 수 있는 새로운 구조가 필요하다. [Figure 1]
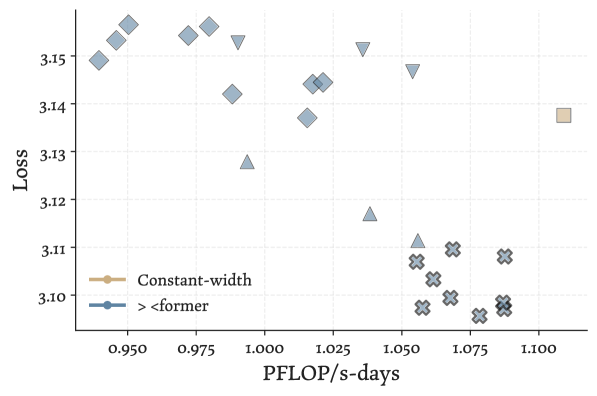
Figure 1 — > <former 아키텍처 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 ×-shaped의 비균등 Width 할당 방식을 적용한 > <former를 제안하며, 이는 초기와 후기 층은 넓게 유지하되 중간 층은 좁게 설계하여 자원을 효율적으로 재배치한다 [Figure 2]. 저자들은 Fixed-Residual 메커니즘을 통해 층마다 서로 다른 차원의 입출력을 Projection 없이 복사(Copy)하거나 잘라내는 방식으로 구현하여, 추가적인 학습 파라미터 없이 층간 병목 현상을 해결한다 [Figure 3]. 실험 결과, 200M부터 3B 파라미터 규모의 모델들에서 > <former는 매개변수가 동일한 Constant-Width Transformer 대비 더 낮은 Perplexity를 달성하였다. 정량적으로는 동일 손실(Loss) 수준에서 FLOPs를 22% 절감하고, KV cache 메모리와 입출력(I/O) 비용을 15% 감축하는 효과를 보였다 [Table 2]. 또한, 이러한 병목 구조가 중간 층에서의 Representation Collapse를 완화하고, 신경망 내부에서 정보를 보다 고르게 활용하도록 유도함을 입증하였다 [Figure 5]. [Table 3]
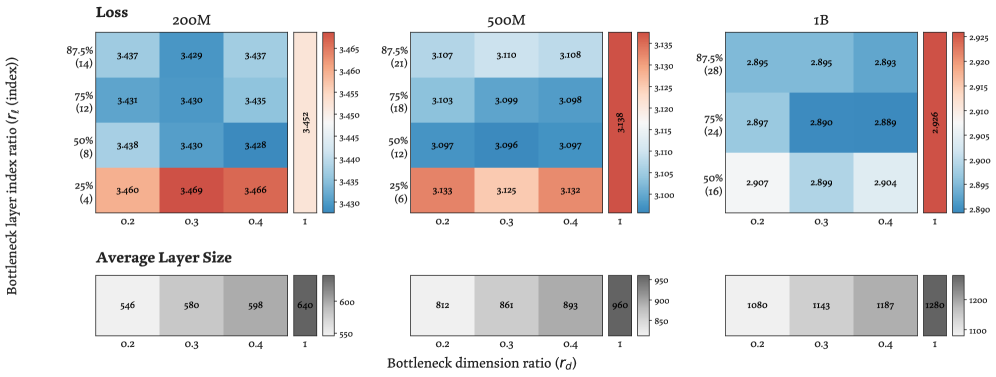
Figure 2 — 다양한 Shape 성능 비교
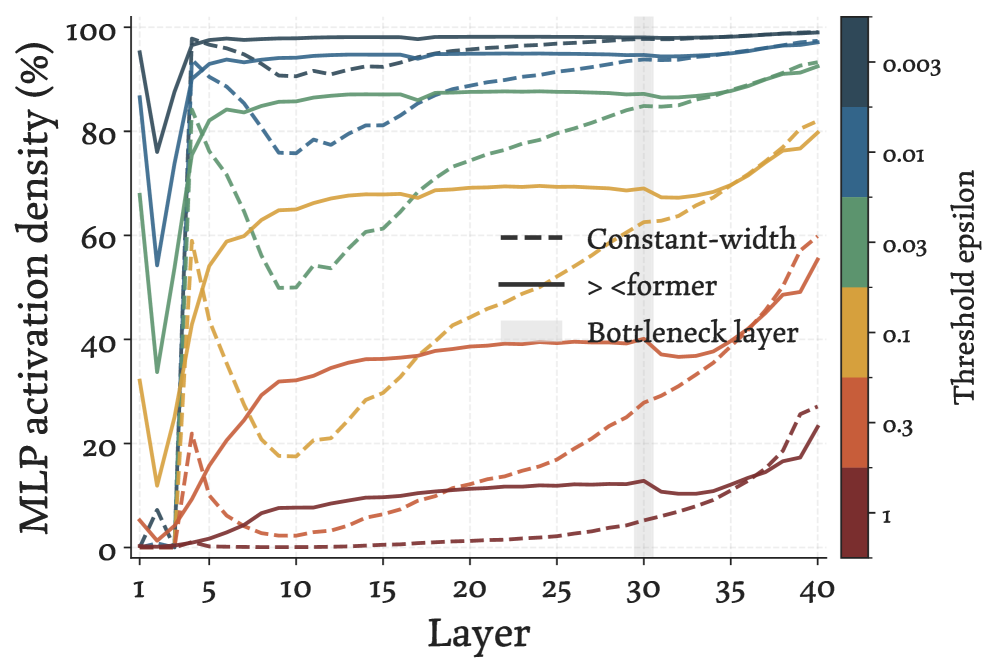
Figure 5 — MLP 활용도 분석
4. Conclusion & Impact (결론 및 시사점)
본 논문은 비균등한 Width 할당이 대규모 언어 모델의 확장(Scaling)에 있어 더욱 자원 최적화된 전략임을 증명하였다. 제안된 > <former는 파라미터 효율성을 극대화하면서도 KV Cache와 학습 연산량을 유의미하게 감소시켜 실무적인 이점을 제공한다. 이 연구는 모델 설계 시 Width를 고정해야 한다는 기존의 관념을 탈피하여, 향후 Transformer 아키텍처 연구에서 새로운 설계 자유도를 확보하는 계기가 될 것이다. 특히 자원이 제한된 환경에서 대형 모델을 효율적으로 운영하고자 하는 학계 및 산업계 전반에 중요한 시사점을 던진다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Latent Collaboration in Multi-Agent Systems
- [논문리뷰] Virtual Width Networks
- [논문리뷰] Robust Layerwise Scaling Rules by Proper Weight Decay Tuning
- [논문리뷰] Hybrid Architectures for Language Models: Systematic Analysis and Design Insights
- [논문리뷰] GLiClass: Generalist Lightweight Model for Sequence Classification Tasks
댓글