[논문리뷰] Unified Multimodal Autoregressive Modeling with Shared Context-Visual Tokenizer is Key to Unification
링크: 논문 PDF로 바로 열기
메타데이터
저자: Wujian Peng, Lingchen Meng, Yuxuan Cai, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- UniAR: 시각적 이해와 생성을 하나의 autoregressive 프레임워크 내에서 단일 visual tokenizer로 통합한 모델입니다.
- BSQ (Binary Spherical Quantization): 명시적 codebook 없이 시각적 특징을 이진 벡터(binary vector)로 양자화하여, 기하급수적으로 확장 가능한 어휘집을 제공하는 기법입니다.
- DeepStack: 시각적 인코더의 다중 계층(multi-level)에서 특징을 융합하여 고차원 의미와 저차원 세부 정보를 동시에 보존하는 구조입니다.
- Parallel Bitwise Prediction: autoregressive 생성 시 2×2 공간 그리드 내의 다중 비트 벡터를 동시에 예측하여 visual sequence 길이를 줄이고 추론 속도를 높이는 방식입니다.
- DiT (Diffusion Transformer): 예측된 이진 visual 토큰으로부터 고충실도 이미지를 복원하는 diffusion 기반 디코더입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의)
- 본 논문은 시각적 이해(understanding)와 생성(generation)이 서로 다른 representation space를 사용하여 통합된 모델링을 저해한다는 핵심 문제를 해결합니다.
- 기존의 통합 모델들은 각 작업을 처리하기 위해 두 개의 서로 다른 visual tokenizer를 사용하는 경향이 있어, 생성된 이미지를 이해하기 위해 다시 인코딩하는 과정이 필요하며 이는 공유된 컨텍스트(shared context)를 저해합니다.
- 이러한 작업 간의 불일치를 극복하고, 모델이 자신의 생성을 별도의 변환 없이 직접 해석할 수 있는 진정한 의미의 통합된 autogregressive 프레임워크가 요구됩니다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과)
- 본 논문은 단일 visual tokenizer를 기반으로 한 UniAR을 제안하며, 다중 계층의 특징을 융합하고 BSQ를 통해 이진 형태로 시각적 정보를 표현합니다.
- 모델은 DeepStack 설계를 통해 고수준의 의미론적 정보와 저수준의 세부 정보를 함께 보존하며, 32×의 압축률을 달성합니다.
- 생성 효율을 위해 제안된 parallel bitwise prediction은 자동 회귀 단계를 줄여 높은 추론 성능을 보장하며, DiT 기반 디코더는 추가 텍스트 입력 없이 시각적 토큰만으로 고품질 이미지를 복원합니다.
- 실험 결과, UniAR은 GenEval 벤치마크에서 0.86의 전체 점수를 기록하여 GPT-4o와 FLUX.1-dev를 능가하는 성능을 보였습니다. [Table 1]
- 또한, 텍스트 렌더링 성능에서도 OneIG-EN 0.873, LongText-EN 0.917을 기록하며 기존의 생성 전문 모델 및 통합 모델 대비 우월한 instruction-following 능력을 입증했습니다. [Table 2]
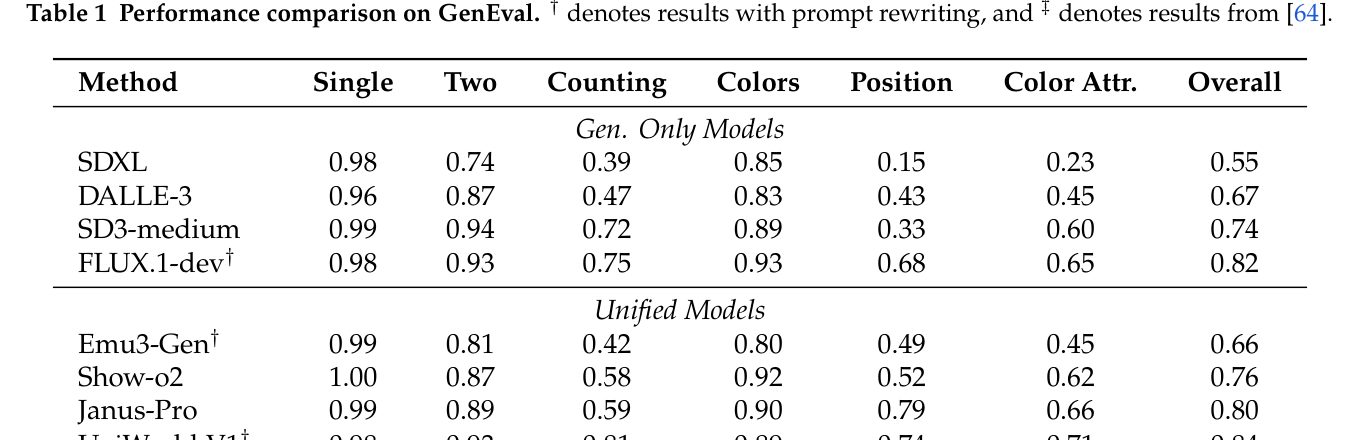
Table 1 — GenEval 벤치마크에서 다른 모델들과의 성능을 비교한 핵심 결과 테이블
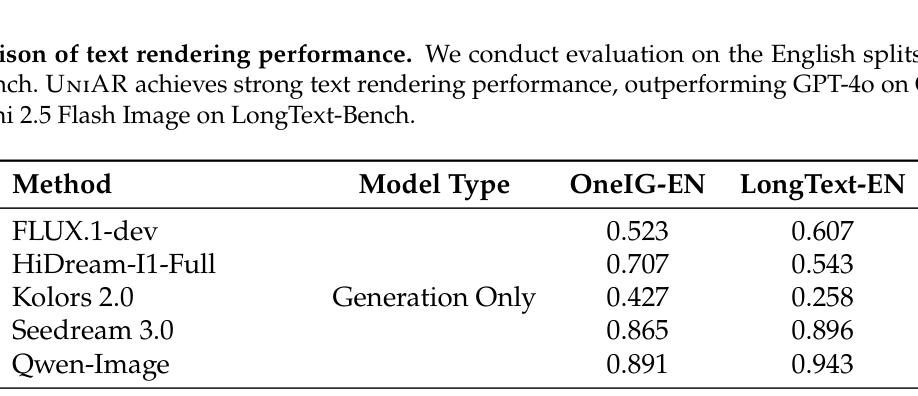
Table 2 — 텍스트 렌더링 성능을 비교하여 모델의 생성 우수성을 입증하는 핵심 지표 테이블
## 4. Conclusion & Impact (결론 및 시사점)
- 본 연구는 단일 시각적 토큰화 전략과 다중 계층 비트와이즈 양자화 기법을 도입하여, 시각적 이해와 생성 기능을 단일 autoregressive 아키텍처 내에서 성공적으로 통합했습니다.
- UniAR은 학습 과정에서 인위적인 multi-turn 데이터 없이도 생성된 결과물을 스스로 해석하는 emergent property를 보여주었으며, 이는 향후 범용적인 통합 멀티모달 모델 설계에 중요한 이정표가 될 것입니다.
- 본 프레임워크는 낮은 계산 비용으로 우수한 성능을 확보함으로써, 효율적이고 통합된 멀티모달 AI 시스템 구축을 위한 실용적인 솔루션을 제시합니다.
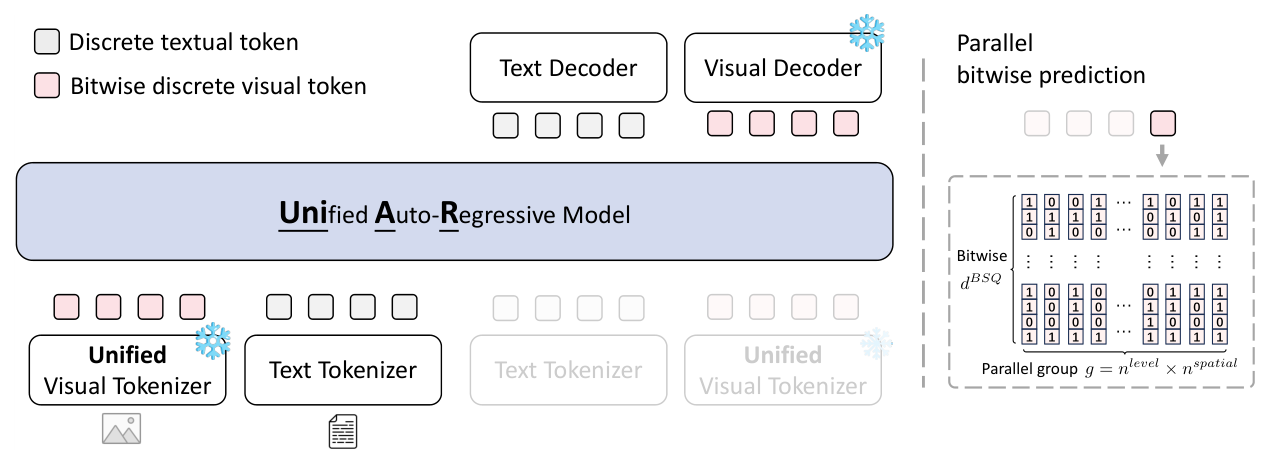
Figure 2 — UniAR의 핵심 아키텍처와 parallel bitwise prediction 흐름을 나타내는 전체 모델 다이어그램
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Lance: Unified Multimodal Modeling by Multi-Task Synergy
- [논문리뷰] HYDRA-X: Native Unified Multimodal Models with Holistic Visual Tokenizers
- [논문리뷰] GaussianGPT: Towards Autoregressive 3D Gaussian Scene Generation
- [논문리뷰] LongCat-Next: Lexicalizing Modalities as Discrete Tokens
- [논문리뷰] MOSS-TTS Technical Report
Review 의 다른글
- 이전글 [논문리뷰] The Price of Anarchy in Disaggregated Inference
- 현재글 : [논문리뷰] Unified Multimodal Autoregressive Modeling with Shared Context-Visual Tokenizer is Key to Unification
- 다음글 [논문리뷰] Variable-Width Transformers
댓글