[논문리뷰] Visual-Seeker: Towards Visual-Native Multimodal Agentic Search via Active Visual Reasoning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Zhengbo Zhang, Changtao Miao, Jinbo Su, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Visual-native Search: 시각 정보를 단순한 부가 입력으로 취급하는 것이 아니라, 검색 과정 전체에서 적극적으로 활용하여 시각적 추론과 증거 수집을 수행하는 검색 패러다임입니다.
- Active Visual Reasoning Data Pipeline: 복합적이고 다중 엔티티가 포함된 이미지에서 시각적 정보를 추출하고, 이를 기반으로 다중 단계(Multi-hop)의 검색 궤적을 합성하여 에이전트의 시각적 지능을 학습시키는 데이터 파이프라인입니다.
- Visual Evidence Injection (VEI): 모델이 웹 검색 과정에서 텍스트뿐만 아니라 검색된 이미지로부터 시각적 증거를 능동적으로 수집하고 추론하도록 강제하는 데이터 증강 기법입니다.
- ReAct-style Loop: 모델이 추론(Reasoning)과 행동(Action/Tool call)을 반복하며 정보를 수집하고 최종 결과를 도출하는 에이전트 워크플로우를 지칭합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 Multimodal Deep Search Agent들이 실제 환경의 복잡한 시각 정보를 효과적으로 다루지 못하는 'Visual Blindness' 문제를 해결하고자 합니다. 기존 방식들은 시각 데이터를 단순히 쿼리의 부가적 요소로만 사용하여, 웹 환경의 풍부한 시각적 증거를 능동적으로 수집하거나 다중 단계의 시각적 추론을 수행하는 데 한계가 있습니다 [Figure 1]. 저자들은 기존의 학습 데이터가 시각적 상세 정보를 결여하고 텍스트 위주의 검색 궤적에 의존한다는 점을 문제로 지적하며, 모델의 Visual-native한 시각 인식 및 추론 능력을 극대화할 새로운 접근 방식을 제안합니다.
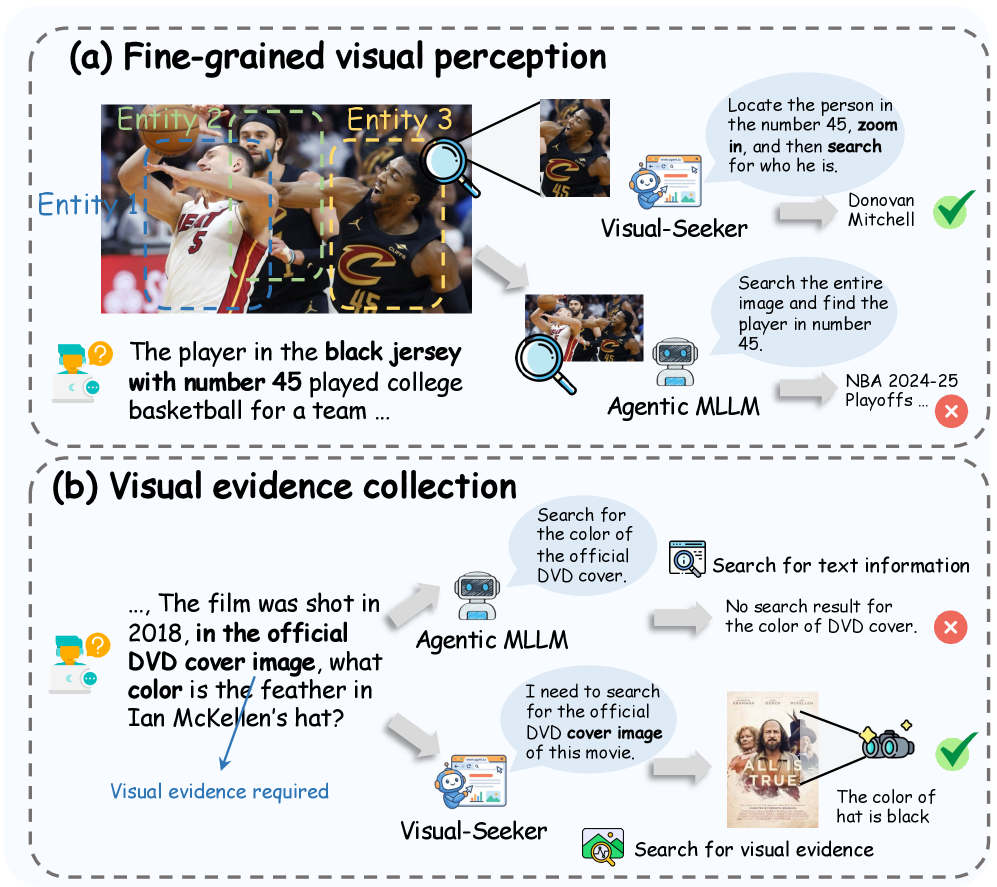
Figure 1 — Visual-native 검색의 필요성
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들이 제안하는 Visual-Seeker는 시각적 세부 사항을 파악하고 웹 환경에서 시각적 증거를 능동적으로 수집하는 Active Visual Reasoning 기반의 에이전트입니다. 이를 위해 5,000개의 고품질 멀티모달 검색 궤적을 합성하는 데이터 파이프라인을 구축하였으며, 여기에는 엔티티 추출, 지식 그래프를 이용한 다중 단계 궤적 합성, 그리고 Visual Evidence Injection 단계가 포함됩니다 [Figure 2]. Visual-Seeker는 Qwen3-VL-8B-Instruct를 기반으로 SFT(Supervised Fine-Tuning)를 거쳐 학습되었습니다. 실험 결과, Visual-Seeker는 5개 멀티모달 검색 벤치마크에서 기존 SOTA 모델들을 능가하는 성능을 보였으며, 특히 복잡한 멀티 엔티티 시나리오를 다루는 MMSearch-Plus와 시각적 증거 수집이 필수적인 VisBrowse-Bench에서 탁월한 성과를 거두었습니다 [Table 1]. 또한, image_crop 및 search_image 툴의 기여도를 분석하여, 이러한 툴이 모델의 시각적 grounding 및 증거 수집 능력을 비약적으로 향상시킴을 입증하였습니다 [Table 3].
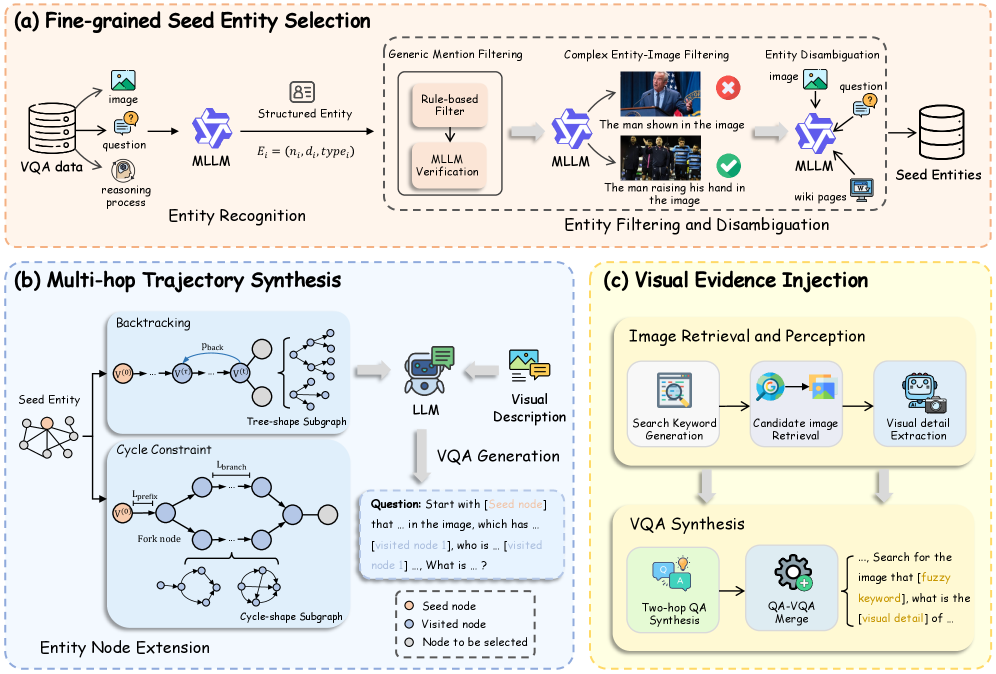
Figure 2 — 데이터 합성 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 논문은 시각적 추론과 적극적인 증거 수집을 통합한 Visual-Seeker를 통해 멀티모달 검색 에이전트의 새로운 이정표를 제시합니다. 제안된 데이터 파이프라인은 복잡한 실제 환경의 정보를 모델이 더 깊이 있게 이해하도록 유도하며, 이는 모델이 단순한 텍스트 답변을 넘어 웹에서 시각적 근거를 바탕으로 정교한 답변을 생성하게 합니다. 이 연구는 Visual-native한 에이전트 개발을 위한 효과적인 데이터 합성 및 학습 전략을 제공함으로써, 학계와 산업계의 멀티모달 검색 및 에이전트 시스템 고도화에 중요한 기여를 할 것으로 기대됩니다.
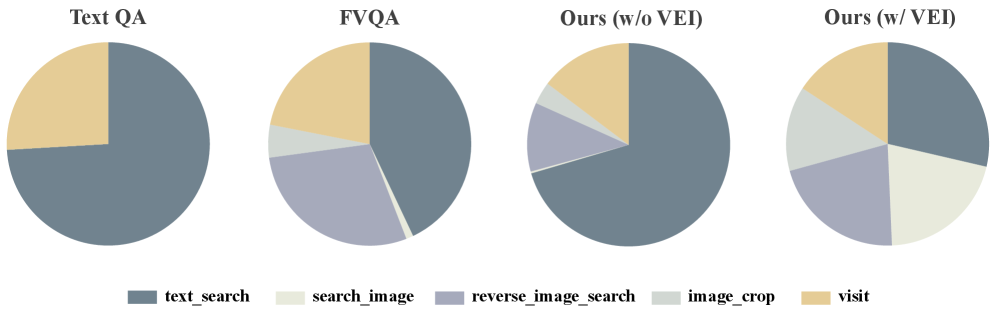
Figure 3 — 학습 궤적의 툴 사용 분포
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Marco DeepResearch: Unlocking Efficient Deep Research Agents via Verification-Centric Design
- [논문리뷰] Beyond Ten Turns: Unlocking Long-Horizon Agentic Search with Large-Scale Asynchronous RL
- [논문리뷰] RODS: Reward-Driven Online Data Synthesis for Multi-Turn Tool-Use Agents
- [논문리뷰] IndustryBench-MIPU: Benchmarking Multi-Image Attribute Value Extraction for Industrial Products
- [논문리뷰] Beyond the Current Observation: Evaluating Multimodal Large Language Models in Controllable Non-Markov Games
Review 의 다른글
- 이전글 [논문리뷰] Variable-Width Transformers
- 현재글 : [논문리뷰] Visual-Seeker: Towards Visual-Native Multimodal Agentic Search via Active Visual Reasoning
- 다음글 [논문리뷰] Zone of Proximal Policy Optimization: Teacher in Prompts, Not Gradients
댓글