[논문리뷰] GRADE: Benchmarking Discipline-Informed Reasoning in Image Editing
링크: 논문 PDF로 바로 열기
저자: Mingxin Liu, Ziqian Fan, Zhaokai Wang, et al.
키워: Image Editing, Multimodal Models, Discipline-Informed Reasoning, Benchmarking, Evaluation Metrics, Knowledge Grounding, Visual Consistency
1. Key Terms & Definitions (핵심 용어 및 정의)
- UMMs (Unified Multimodal Models) : Multimodal models that aim to achieve unified abilities in multimodal understanding, reasoning, and image generation.
- GRADE (Grounded Reasoning Assessment for Discipline-informed Editing) : 학문 분야별 지식과 추론을 평가하기 위해 설계된 최초의 이미지 편집 벤치마크.
- Discipline Reasoning : 모델이 편집 결과에서 underlying disciplinary knowledge를 올바르게 반영하는지를 평가하는 핵심 지표.
- Visual Consistency : 편집된 이미지가 의도된 시각적 구조와 일관되게 통합되는지, 그리고 task-specific constraints를 준수하는지를 평가하는 지표.
- Logical Readability : 편집된 이미지가 discipline-specific content를 명확하고 논리적으로 일관되며 해석 가능한 형태로 제시하는지를 평가하는 지표.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Unified Multimodal Models (UMMs)는 지식, 구조화된 추론, 제어 가능한 생성을 단일 시스템으로 통합하는 것을 목표로 하지만, 현재 이미지 편집 벤치마크 [37, 57]는 주로 natural image domain과 shallow commonsense reasoning에 국한되어 있습니다. 이러한 기존 벤치마크들은 structured, domain-specific constraints 하에서 UMMs의 능력을 종합적으로 평가하는 데 제한적입니다. 저자들은 discipline-informed image editing이 기존 시각 구조를 보존하면서 domain-specific한 지식에 기반한 정확한 수정을 요구하므로, UMMs에 대한 보다 엄격하고 대표적인 평가 설정을 제공한다고 주장합니다. 따라서, 현재 벤치마크의 이러한 간극을 메우고, 복잡한 학문적 지식을 다루는 UMMs의 능력을 평가하기 위해 새로운 벤치마크의 필요성이 대두되었습니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구에서는 Discipline-informed Reasoning 을 평가하기 위한 최초의 이미지 편집 벤치마크인 GRADE 를 제안합니다. GRADE 는 자연 과학에서 사회 과학에 이르는 10개 학문 분야 에 걸쳐 신중하게 큐레이션된 520개 샘플 로 구성됩니다. 엄격한 평가를 위해 Discipline Reasoning , Visual Consistency , Logical Readability 를 종합적으로 평가하는 다차원 자동화 평가 프로토콜을 제안합니다
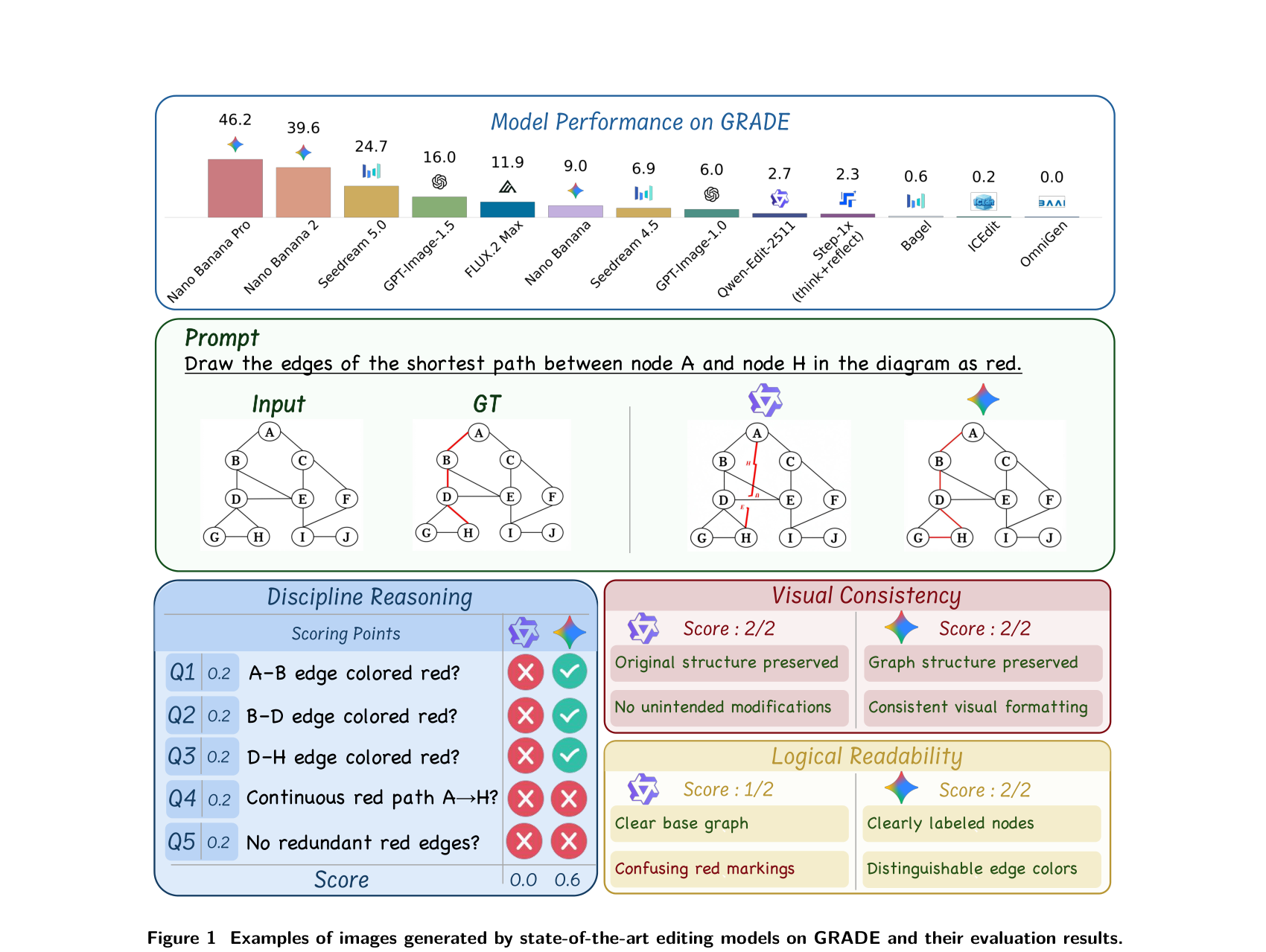 Figure 1: Examples of images generated by state-of-the-art editing models on GRADE and their evaluation results.
Figure 1: Examples of images generated by state-of-the-art editing models on GRADE and their evaluation results.
,
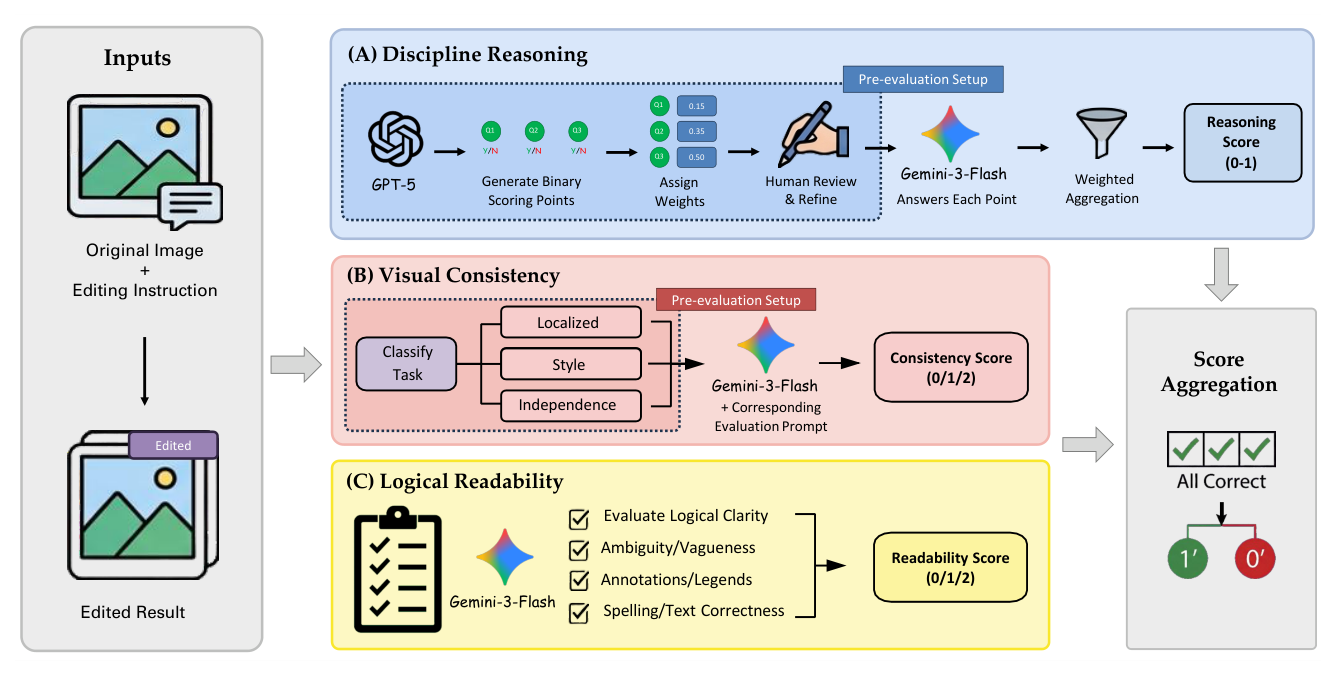 Figure 3: Evaluation pipeline. We evaluate edited results on (A) Discipline Reasoning via weighted, question-guided MLLM judging, (B) Visual Consistency with task-specific prompts (localized/style/independence), and (C) Logical Readability for clarity and text/annotation correctness.
Figure 3: Evaluation pipeline. We evaluate edited results on (A) Discipline Reasoning via weighted, question-guided MLLM judging, (B) Visual Consistency with task-specific prompts (localized/style/independence), and (C) Logical Readability for clarity and text/annotation correctness.
. Discipline Reasoning 은 weighted, question-guided MLLM judging ( Gemini-3-Flash 기반)을 통해 0-1 점수로 평가되며, Visual Consistency 와 Logical Readability 는 각각 0/1/2 점수로 평가됩니다. 전체 정확도는 모든 세 가지 차원에서 최대 점수를 달성했을 때만 Correct로 간주됩니다.
20개 SoTA 모델 (10개 closed-source, 10개 open-source)에 대한 광범위한 실험 결과, 현재 모델들이 암묵적이고 지식 집약적인 편집 환경에서 상당한 한계를 보이며 큰 성능 격차를 보였습니다. 예를 들어, 최고의 모델인 Nano Banana Pro 는 46.2% 의 정확도로 가장 높은 overall performance를 달성했지만, 여전히 50% 미만의 정확도를 보여 discipline-informed editing 요구사항을 충족하는 데 어려움을 겪고 있음을 시사했습니다. 기존 벤치마크에서 유사한 성능을 보인 GPT-Image-1.5 ( 16.0% ) 및 Seedream 5.0 ( 24.7% ) 같은 모델들은 GRADE 에서 현저한 성능 차이를 보여, GRADE 가 지식 집약적 추론 평가에 강력한 식별력을 가짐을 입증했습니다
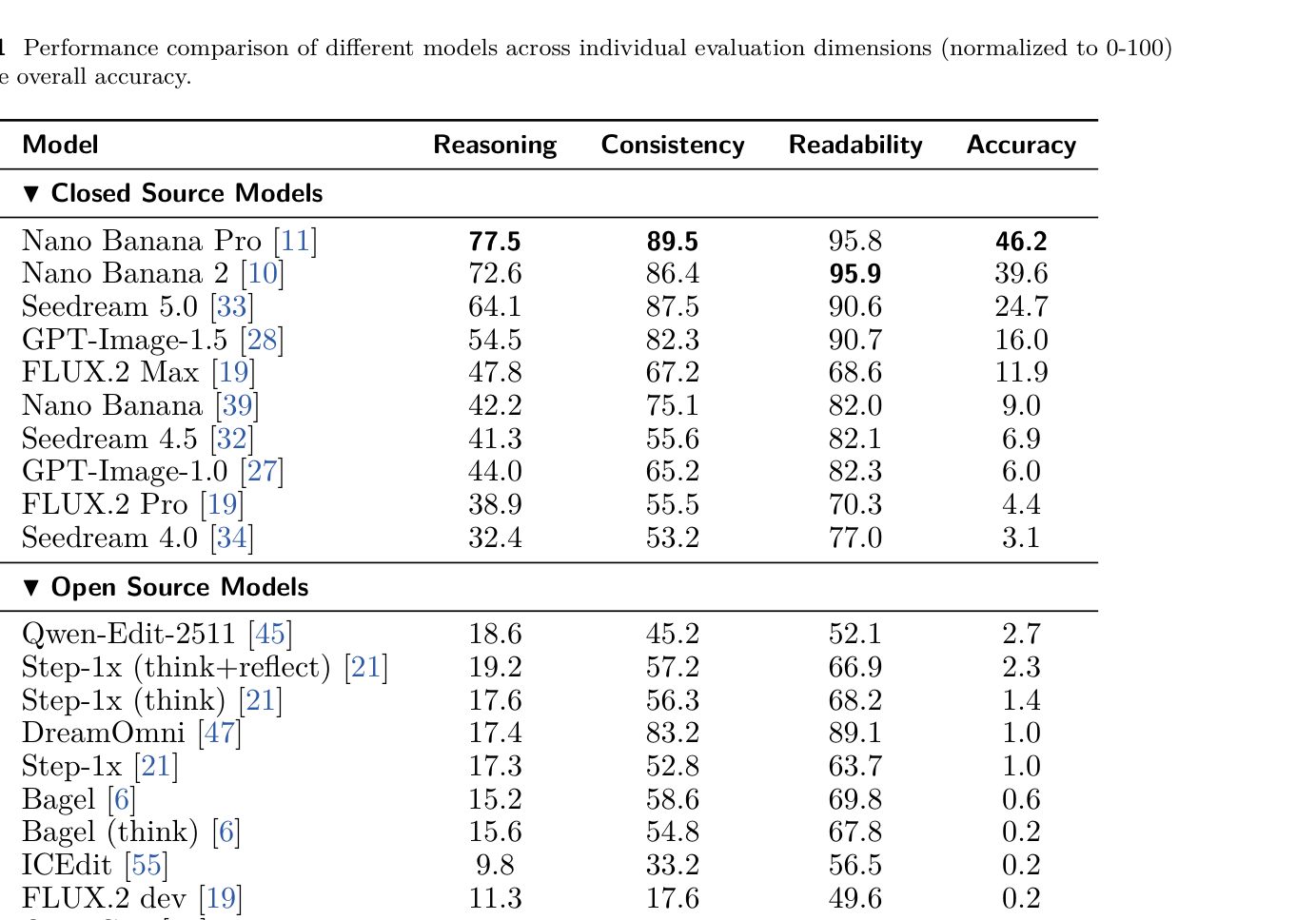 Table 1: Performance comparison of different models across individual evaluation dimensions (normalized to 0-100) and the overall accuracy.
Table 1: Performance comparison of different models across individual evaluation dimensions (normalized to 0-100) and the overall accuracy.
. 또한, closed-source 모델이 open-source 모델을 일관되게 능가했으며, 최고의 open-source 모델인 Qwen-Edit-2511 는 단 2.7% 의 정확도로 크게 뒤처졌습니다. Nano Banana Pro 는 Discipline Reasoning 에서 77.5% , Visual Consistency 에서 89.5% , Logical Readability 에서 95.8% 를 달성했습니다. Instruction Explicitness에 대한 ablation study에서는 instructions를 명시적으로 제공할 경우 모델 성능이 일관되게 향상되었고, 특히 Qwen-Edit-2511 의 정확도는 1.5% 에서 8.8% 로 크게 증가하여 open-source 모델이 암묵적 추론 능력에서 더 큰 격차를 보임을 나타냈습니다 [Table 4]. 평가 신뢰도를 위해 Gemini-3-Flash 를 judge model로 사용했으며, 인간 평가와의 높은 alignment를 확인했습니다 ( MAE 0.1194 , Pearson correlation 0.8505 ) [Table 3], [Table 8].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 학문 분야별 지식에 기반한 이미지 편집 성능을 체계적으로 평가하는 최초의 벤치마크인 GRADE 를 소개합니다. GRADE 는 520개 샘플 과 human judgments와 높은 alignment를 보이는 다차원 평가 프로토콜을 통해, 현재 Unified Multimodal Models (UMMs)이 암묵적인 지시 하에 discipline-informed reasoning을 적용하는 데 있어 상당한 한계가 있음을 밝혀냈습니다. 이러한 결과는 시각적 사실성을 넘어 구조화된 학문적 지식을 처리하는 데 있어 현재 모델의 지속적인 제한 사항을 강조하며, discipline-informed image editing 및 reasoning 연구의 미래 발전을 위한 핵심 방향을 제시합니다. 궁극적으로, GRADE 는 UMMs가 discipline-informed knowledge, reasoning, editing을 더 잘 통합할 수 있도록 연구를 발전시키는 데 기여할 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] Understanding the Behaviors of Environment-aware Information Retrieval
- [논문리뷰] Thinking with Visual Grounding
- [논문리뷰] Taylor-Calibrate: Principled Initialization for Hybrid Linear Attention Distillation
- [논문리뷰] Selective Synergistic Learning for Video Object-Centric Learning
Review 의 다른글
- 이전글 [논문리뷰] Examining Reasoning LLMs-as-Judges in Non-Verifiable LLM Post-Training
- 현재글 : [논문리뷰] GRADE: Benchmarking Discipline-Informed Reasoning in Image Editing
- 다음글 [논문리뷰] IndexCache: Accelerating Sparse Attention via Cross-Layer Index Reuse
댓글