[논문리뷰] IndexCache: Accelerating Sparse Attention via Cross-Layer Index Reuse
링크: 논문 PDF로 바로 열기
저자: Yushi Bai, Qian Dong, Ting Jiang, Xin Lv, Zhengxiao Du, Aohan Zeng, Jie Tang, Juanzi Li
키워: Sparse Attention, Cross-Layer Reuse, Indexer, Latency, Throughput, DeepSeek Sparse Attention (DSA), Distillation, LLMs
1. Key Terms & Definitions (핵심 용어 및 정의)
- IndexCache : DeepSeek Sparse Attention (DSA) 모델에서
indexer계산의cross-layer redundancy를 활용하여sparse attention을 가속화하는 제안된 방법론. - Sparse Attention : 모든 이전 토큰에
attend하는 대신, 각query에 대해 가장 관련성 높은top-k토큰만 선택하여core attentioncomplexity를O(L²)에서O(Lk)로 줄이는 메커니즘. - DeepSeek Sparse Attention (DSA) : 각
layer에서top-k토큰을 선택하는 경량lightning indexer모듈을 사용하는production-grade trainable sparse attention솔루션. - Indexer :
DSA의 구성 요소로, 모든 이전 토큰에score를 매기고subsequent core attention을 위한top-k highest-scoring positions을 선택하는 모듈. - Full (F) layer :
IndexCache에서indexer를 유지하고 새로운top-k indices를 계산하는layer. - Shared (S) layer :
IndexCache에서indexer없이 가장 가까운 이전F layer에서top-k indices를 상속받아 재사용하는layer.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Long-context agentic workflows에서 Large Language Models (LLMs)의 attention efficiency는 inference speed와 serving cost에 결정적인 요소입니다. Sparse attention은 이 문제를 효과적으로 해결하며, 특히 DeepSeek Sparse Attention (DSA) 는 대표적인 production-grade 솔루션입니다. 그러나 DSA에서 core attention complexity를 O(L²)에서 O(Lk)로 줄였음에도 불구하고, indexer 자체는 여전히 각 layer에서 O(L²) complexity를 유지합니다. 결과적으로 전체 N개 layer에 걸친 indexer의 총 cost는 O(NL²)로, context length가 길어질수록 전체 attention budget에서 상당한 부분을 차지하게 됩니다. 특히 prefill 단계에서 indexer의 latency 점유율이 급격히 증가하는 것이 관찰되었는데, 이는 long-context DSA inference 가속화의 핵심 병목으로 작용합니다
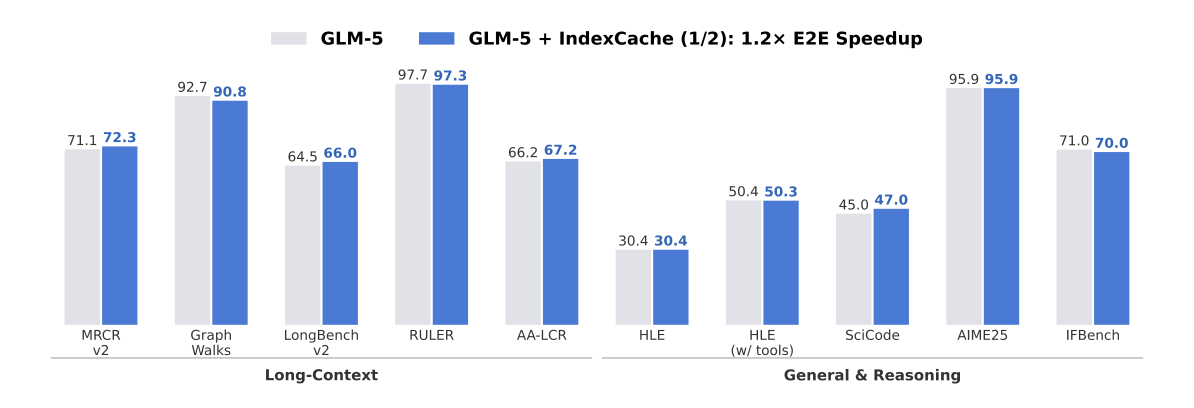 Figure 1: Benchmark comparison between GLM-5 and GLM-5 + IndexCache. IndexCache removes 50% of indexer computations while maintaining comparable performance across both long-context and reasoning tasks, delivering ~ 1.2× end-to-end speedup.
Figure 1: Benchmark comparison between GLM-5 and GLM-5 + IndexCache. IndexCache removes 50% of indexer computations while maintaining comparable performance across both long-context and reasoning tasks, delivering ~ 1.2× end-to-end speedup.
. 기존 cross-layer index reuse 방법들은 oracle로 full attention에 의존하지만, DSA는 full attention을 완전히 제거했기 때문에 이들을 직접 적용할 수 없습니다. 따라서 top-k 선택이 consecutive layer 전반에 걸쳐 유사한 경향이 있음에도 불구하고, indexer 계산의 redundancy를 효과적으로 활용할 방법이 필요합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 cross-layer redundancy를 활용하여 sparse attention을 가속화하는 IndexCache를 제안합니다. IndexCache는 N개 transformer layer를 F (Full) layer와 S (Shared) layer로 나눕니다. F layer는 자체 indexer를 사용하여 새로운 top-k indices를 계산하고 sparse core attention을 수행하며, S layer는 indexer 없이 가장 가까운 이전 F layer에서 top-k indices를 상속받아 재사용합니다
 Figure 2: Side-by-side comparison of inference loops. (a) Standard DSA runs the lightning indexer at every layer. (b) IndexCache adds a single conditional branch (red lines): F layers compute and cache fresh indices; S layers reuse the cached indices. Note that Tcache is a temporary buffer holding only the current index tensor; it is overwritten at each F layer and requires no additional GPU memory beyond what standard DSA already allocates.
Figure 2: Side-by-side comparison of inference loops. (a) Standard DSA runs the lightning indexer at every layer. (b) IndexCache adds a single conditional branch (red lines): F layers compute and cache fresh indices; S layers reuse the cached indices. Note that Tcache is a temporary buffer holding only the current index tensor; it is overwritten at each F layer and requires no additional GPU memory beyond what standard DSA already allocates.
. 이 configuration을 결정하고 최적화하기 위해 두 가지 상보적인 접근 방식을 제시합니다.
첫 번째는 Training-free IndexCache 입니다. 이는 weight update 없이 off-the-shelf DSA model에 적용됩니다. naïve uniform interleaving이 quality를 저하시킬 수 있음을 보여주고, language modeling loss를 최소화하는 greedy layer selection algorithm을 사용하여 optimal pattern을 결정합니다. 실험 결과, Training-free IndexCache 는 30B DSA model에서 1/4 indexer retention ratio로 greedy-searched pattern을 사용했을 때 original DSA의 Long Avg 50.2 와 비교하여 49.9 를 달성하여 거의 동일한 downstream performance를 유지하면서 indexer computation의 75% 를 제거할 수 있었습니다 [Table 2].
두 번째는 Training-aware IndexCache 입니다. 이는 cross-layer sharing을 위해 model parameter를 최적화합니다. multi-layer distillation loss를 도입하여 각 retained indexer를 자신이 serve하는 모든 layer의 averaged attention distribution에 대해 train합니다. 이 목표 하에 simple uniform interleaved pattern조차 full-indexer accuracy와 동등한 성능을 달성합니다. Training-aware IndexCache 는 uniform interleaving으로 1/2 retention ratio에서 Long Avg 51.6 를 달성하여 baseline (51.0)을 능가하며, 1/4 retention ratio에서도 baseline과 비교하여 0.4% 이내의 성능을 유지했습니다 [Table 3].
종합적으로, IndexCache 는 30B DSA model에서 200K context length 기준 standard DSA 대비 최대 1.82x prefill speedup 와 1.48x decode speedup 를 달성했습니다. 이는 indexer computation의 75% 를 제거함으로써 prefill latency를 19.5s 에서 10.7s 로 감소시켰기 때문입니다 [Table 1, Figure 3]. 또한, 744B GLM-5 model 에 대한 예비 실험에서도 최소 1.2x end-to-end speedup 를 달성하며 scalability를 확인했습니다 [Figure 1, Table 4].
4. Conclusion & Impact (결론 및 시사점)
IndexCache는 sparse attention의 indexer에서 발생하는 cross-layer redundancy를 효과적으로 활용하여 inference latency를 크게 줄이는 새로운 방법론입니다. training-free 및 training-aware 두 가지 접근 방식을 통해 indexer computation을 최대 75% 까지 제거하면서도 model quality 저하를 거의 발생시키지 않습니다. 특히 long-context scenarios에서 prefill 및 decode throughput를 크게 향상시키는 것이 확인되었습니다. 이 연구는 이전에 full attention이 oracle로 사용되던 cross-layer sharing principle이 dynamic token selection에 의존하는 sparse attention method에도 자연스럽게 확장될 수 있음을 입증합니다. sparse attention이 frontier LLMs의 기본이 되어감에 따라, IndexCache와 같은 cross-layer index reuse 기술은 효율적인 inference pipeline의 표준 구성 요소가 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] Understanding the Behaviors of Environment-aware Information Retrieval
- [논문리뷰] Thinking with Visual Grounding
- [논문리뷰] Taylor-Calibrate: Principled Initialization for Hybrid Linear Attention Distillation
- [논문리뷰] Selective Synergistic Learning for Video Object-Centric Learning
Review 의 다른글
- 이전글 [논문리뷰] GRADE: Benchmarking Discipline-Informed Reasoning in Image Editing
- 현재글 : [논문리뷰] IndexCache: Accelerating Sparse Attention via Cross-Layer Index Reuse
- 다음글 [논문리뷰] Mobile-GS: Real-time Gaussian Splatting for Mobile Devices
댓글