[논문리뷰] LumosX: Relate Any Identities with Their Attributes for Personalized Video Generation
링크: 논문 PDF로 바로 열기
저자: Jiazheng Xing, Fei Du, Hangjie Yuan, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- LumosX : 개별 피사체와 그 속성 간의 복잡한 관계를 명시적으로 모델링하여 개인화된 다중 피사체(multi-subject) 비디오 생성을 가능하게 하는 프레임워크입니다.
- Relational Self-Attention : 비디오 토큰과 컨디션 토큰 간의 공간-시간(spatio-temporal) 및 인과적(causal) 조건부 모델링을 지원하는 LumosX의 모듈입니다. Relational Rotary Position Embedding (R2PE) 과 Causal Self-Attention Mask (CSAM) 를 포함합니다.
- Relational Cross-Attention : 텍스트 컨디션(text conditions)을 통합하고 시각적 토큰 표현(visual token representations)을 강화하며, 얼굴-속성 관계(face-attribute relationships)를 정렬하는 LumosX의 모듈입니다. Multilevel Cross-Attention Mask (MCAM) 를 사용합니다.
- R2PE (Relational Rotary Position Embedding) : 3D Rotary Position Embedding (3D-RoPE)을 컨디션 이미지로 확장하여 얼굴-속성 종속성(face-attribute dependency)을 보존하면서 위치 정보를 할당하는 방법론입니다.
- MCAM (Multilevel Cross-Attention Mask) : Cross-Attention 과정에서 시각적 컨디션 토큰과 해당 텍스트 토큰 간의 강한 상관관계(Strong Correlation), 동일한 피사체 그룹 내의 얼굴 및 속성 토큰 간의 상관관계(Correlation), 그리고 다른 피사체 그룹 간의 약한 상관관계(Weak Correlation)를 정의하여 그룹 내 일관성을 강화하고 그룹 간 간섭을 억제하는 마스크입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 Diffusion Model의 발전으로 Text-to-Video 생성 능력이 크게 향상되어, 전경(foreground)과 배경(background) 요소에 대한 fine-grained control을 통해 개인화된 콘텐츠 생성이 가능해졌습니다. 하지만 기존 방법론들은 intra-group consistency 를 보장하는 명시적인 메커니즘이 부족하여, 다중 피사체(multi-subject) 시나리오에서 얼굴-속성 정렬(face-attribute alignment)의 정확성 유지에 어려움을 겪고 있습니다. 특히, 텍스트 캡션(text captions)을 통한 암묵적 모델링(implicit modeling)은 "A man on the left with … and a man on the right with …"와 같이 유사한 주어 명사(subject nouns)가 포함될 때 피사체-속성 연관성(subject-attribute associations)에 혼란을 야기할 수 있습니다. 이러한 한계점을 해결하기 위해서는 데이터 레벨과 모델 레벨 모두에서 얼굴-속성 종속성(face-attribute dependencies)을 명시적으로 바인딩하는 새로운 접근 방식이 필요합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 개인화된 다중 피사체 비디오 생성을 위한 프레임워크인 LumosX 를 제안합니다. 이 프레임워크는 데이터 측면과 모델 측면 모두에서 새로운 설계를 포함합니다.
데이터 측면 : 기존의 주석 처리된 종속성 구조(dependency structures) 데이터셋 부족 문제를 해결하기 위해, 독립적인 비디오에서 캡션과 시각적 신호(visual cues)를 조율하고 Multimodal Large Language Models (MLLMs), 특히 Qwen2.5-VL 을 활용하여 피사체별 종속성(subject-specific dependencies)을 추론하고 할당하는 맞춤형 데이터 수집 파이프라인을 구축했습니다.
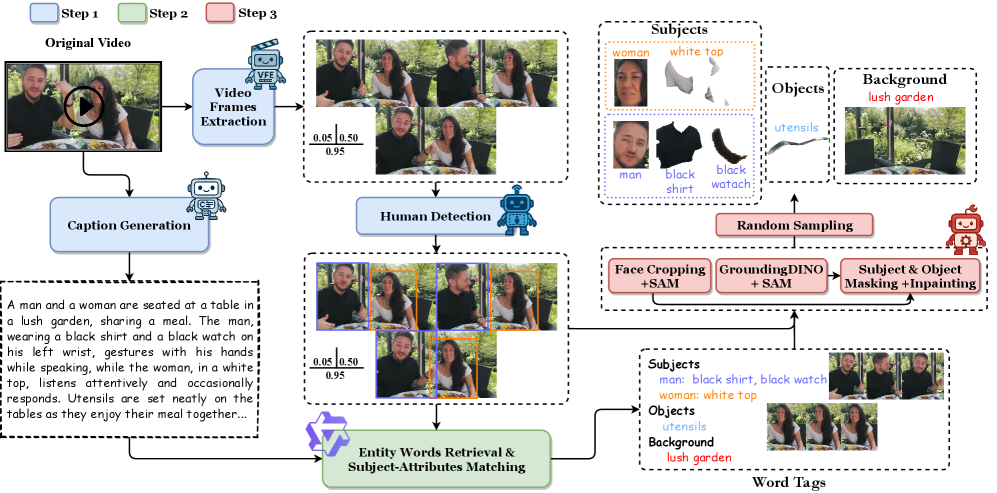
이 파이프라인은 캡션 생성 및 사람 감지, 엔티티 단어 검색 및 얼굴-속성 매칭, 조건 이미지 획득의 세 단계를 거쳐 명시적인 얼굴-속성 일치(face-attribute correspondences)를 가진 단일 및 다중 피사체 데이터를 생성합니다. FLUX Inpainting 모델을 사용하여 깨끗한 배경 이미지를 생성하는 과정도 포함됩니다. 이 과정을 통해 구축된 1.57M 규모의 데이터셋은 모델링의 개인화를 향상시키고 종합적인 벤치마크를 구축하는 데 기여합니다.
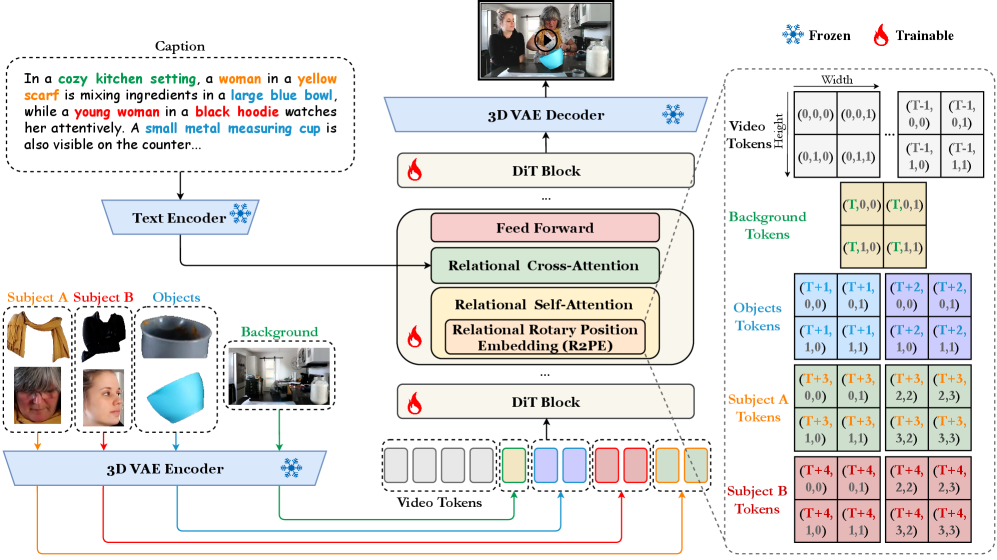
방법론 측면 : Wan2.1 Text-to-Video (T2V) 모델을 기반으로 하는 LumosX 는 얼굴-속성 바인딩(face-attribute bindings)을 일관된 피사체 그룹으로 명시적으로 인코딩하기 위해 Relational Self-Attention 및 Relational Cross-Attention 이라는 두 가지 전용 모듈을 도입합니다. [Figure 3]
- Relational Self-Attention 은 Relational Rotary Position Embedding (R2PE) 과 Causal Self-Attention Mask (CSAM) 를 통합하여 포지션 인코딩 단계와 공간-시간(spatio-temporal) Self-Attention 단계에서 종속성을 모델링합니다. R2PE 는 3D-RoPE를 컨디션 토큰(condition tokens)으로 확장하여 얼굴-속성 종속성을 보존하며, CSAM 은 조건부 브랜치(conditional branch) 내에서 얼굴과 해당 속성을 하나의 통합된 피사체 조건 브랜치로 처리하고, 비디오 디노이징 토큰(video denoising tokens)이 조건 토큰에 대해서만 단방향 어텐션(unidirectional attention)을 적용하도록 강제합니다.
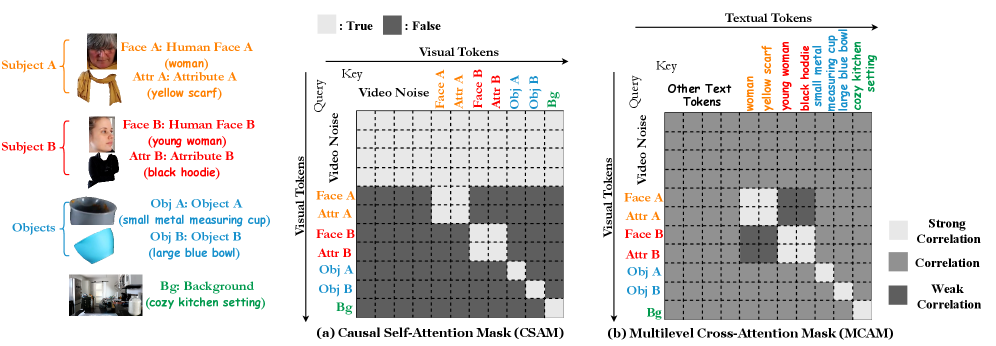
- Relational Cross-Attention 은 Multilevel Cross-Attention Mask (MCAM) 를 도입하여 그룹 내 일관성(intra-group coherence)을 강화하고, 그룹 간 간섭(cross-group interference)을 억제하며, 시각적 조건 토큰의 의미 표현(semantic representation)을 정제합니다. [Figure 4] MCAM 은 강한 상관관계(Strong Correlation), 상관관계(Correlation), 약한 상관관계(Weak Correlation)의 세 가지 상관관계 레벨을 정의하고, 동적 스케일링 팩터
s를 통해 마스크의 강도를 조절하여 효율적인 계산을 가능하게 합니다.
핵심 결과 : 광범위한 평가를 통해 LumosX 는 fine-grained, identity-consistent, semantically aligned personalized multi-subject video generation에서 State-of-the-Art (SOTA) 성능을 달성했습니다.
- Identity-consistent video generation 태스크에서, 단일 얼굴(single-face) 설정에서 LumosX는 ArcSim 0.542 , CurSim 0.575 를 기록하여 ConsisID (ArcSim 0.458, CurSim 0.474) 및 Concat-ID (ArcSim 0.467, CurSim 0.485) 대비 우수한 identity similarity scores 를 보였습니다. 다중 얼굴(multi-face) 설정에서도 LumosX는 SkyReels-A2 및 Phantom에 비해 높은 ArcSim 0.510 , CurSim 0.540 을 달성하며 identity consistency 보존 능력을 입증했습니다.
- Subject-consistent video generation 태스크에서는 전체 비디오 평가에서 LumosX가 Dynamic 0.723 , ViCLIP-T 0.260 , ViCLIP-V 0.932 를 기록하며 Phantom과 SkyReels-A2를 능가했습니다. 추출된 피사체 평가에서도 CLIP-T 0.201 , CLIP-I 0.692 , DINO-I 0.261 , ArcSim 0.454 , CurSim 0.483 를 기록하며 얼굴-속성 연관성의 정확도에서 SOTA 성능을 보였습니다.
- Ablation Study 결과, R2PE 는 ArcSim 지표를 크게 향상시켰고, CSAM 은 CLIP-T 를 개선했습니다. MCAM 은 ArcSim 과 CLIP-T 모두에서 상당한 개선을 가져왔으며, 특히 r=0.5 일 때 ArcSim 이 0.429 로 최적의 성능을 보였습니다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 개인화된 다중 피사체 비디오 생성을 위해 얼굴-속성 종속성(face-attribute dependencies)을 명시적으로 모델링하는 새로운 프레임워크인 LumosX 를 제안합니다. 이 연구는 MLLMs를 활용한 데이터 수집 파이프라인을 통해 주석 처리된 데이터 부족 문제를 해결하고, Relational Self-Attention 및 Relational Cross-Attention 모듈을 통해 얼굴-속성 쌍을 일관된 피사체 그룹으로 바인딩하며 그룹 내/외부 상관관계를 최적화합니다.
LumosX 는 fine-grained하고 개인화된 다중 피사체 비디오 생성에서 State-of-the-Art 성능을 달성했으며, 이는 가상 제작(virtual production) 및 e-commerce와 같은 분야에서 고도로 자유로운 개인화된 콘텐츠 생성의 변혁적인 응용 가능성을 열어줍니다. 또한, 다중 피사체 시나리오에서 identity preservation 및 semantic alignment 의 핵심 과제를 해결하여 해당 분야의 발전에 크게 기여합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] HiFi-Inpaint: Towards High-Fidelity Reference-Based Inpainting for Generating Detail-Preserving Human-Product Images
- [논문리뷰] HiStream: Efficient High-Resolution Video Generation via Redundancy-Eliminated Streaming
- [논문리뷰] EmoVid: A Multimodal Emotion Video Dataset for Emotion-Centric Video Understanding and Generation
- [논문리뷰] DialectGen: Benchmarking and Improving Dialect Robustness in Multimodal Generation
- [논문리뷰] Deforming Videos to Masks: Flow Matching for Referring Video Segmentation
Review 의 다른글
- 이전글 [논문리뷰] LoopRPT: Reinforcement Pre-Training for Looped Language Models
- 현재글 : [논문리뷰] LumosX: Relate Any Identities with Their Attributes for Personalized Video Generation
- 다음글 [논문리뷰] ProactiveBench: Benchmarking Proactiveness in Multimodal Large Language Models
댓글