[논문리뷰] StreamingClaw Technical Report
링크: 논문 PDF로 바로 열기
Some information may not be extracted. 저자: MindGPT-ov Team, Li Auto Inc.
1. Key Terms & Definitions (핵심 용어 및 정의)
- StreamingClaw : 실시간 스트리밍 비디오 이해 및 Embodied Intelligence를 위한 통합 Agent Framework이다. OpenClaw 호환 프레임워크로 실시간, Multimodal 스트리밍 상호작용을 지원한다.
- StreamingReasoning Agent : StreamingClaw의 핵심 Decision Agent로, Multimodal Input에 대한 실시간 Streaming Perception, 이해, 추론을 담당하며, 낮은 Latency로 사용자 Query에 응답하고 결과를 생성한다. 또한 Multi-agent Scheduling을 수행한다.
- StreamingMemory Agent : StreamingClaw의 Sub-agent로, Multimodal Long-term Memory의 저장, 계층적 진화(Hierarchical Evolution), 효율적 Retrieval을 담당하여 Main Agent의 Decision-making을 지원한다.
- StreamingProactivity Agent : StreamingClaw의 Sub-agent로, 미래 사건 예측, 추론 및 Proactive Interaction Decision-making을 담당하여 Online Evolution of Interaction Objectives에 따라 능동적으로 상호작용한다.
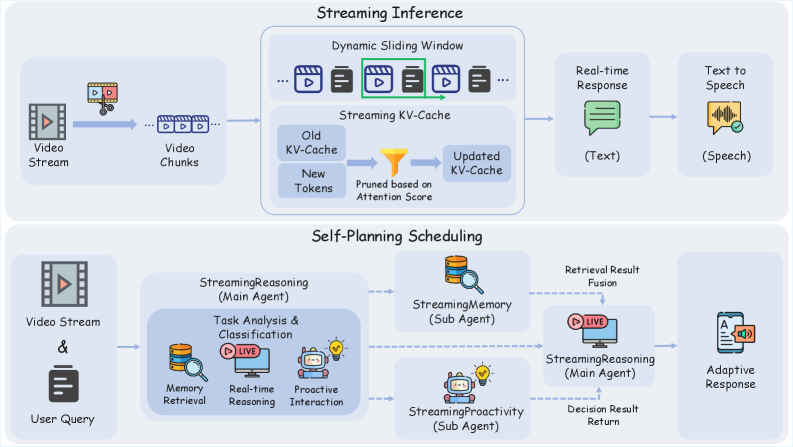
- KV-Cache (Key-Value Cache) : StreamingReasoning Agent의 Streaming Inference 과정에서 사용되는 동적으로 업데이트되는 Cache Pool로, Long-duration Video Stream에서 Context Length 및 GPU Memory Overhead를 제어하기 위해 Dynamic Sliding Window Mechanism과 함께 사용된다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Embodied Intelligence, AI Hardware, Autonomous Driving, Intelligent Cockpits와 같은 Applications은 Real-time Perception–Decision–Action Closed Loop에 크게 의존하며, 이는 Real-time Streaming Video Understanding에 대한 엄격한 요구사항을 부과한다. 그러나 기존 Agent들은 Fragmented Capabilities로 인해 Offline Video Understanding만 지원하거나, Long-term Multimodal Memory Mechanisms이 부족하거나, Long-duration, Continuous Streaming Inputs 하에서 Real-time Inference 및 Proactive Interaction을 달성하는 데 어려움을 겪는 등의 한계점을 가진다. 이러한 단점들은 복잡한 실제 환경에서 Agent들이 지속적인 Perception, Real-time Decision-making, 그리고 Closed-loop Actions을 수행하는 데 주요 Bottleneck이 되며, 동적인 Open Physical Worlds에서의 배포 및 잠재력을 심각하게 제약한다. 특히, Streaming Perception, Long-term Memory, Proactive Interaction 세 가지 핵심 도전과제에 대한 기존 접근 방식들은 정보 손실, 비효율성, Rigid Memory와 같은 명확한 한계점을 보인다. 저자들은 이러한 문제들을 해결하기 위해 비디오 스트림을 연속적인 Spatiotemporal Data로 처리하고, 자율적인 Multi-agent Scheduling Mechanism을 통해 세 가지 핵심 도전과제를 해결하는 새로운 Framework의 필요성을 제기한다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 이러한 Critical Issues를 완화하기 위해 Real-time Streaming Video Understanding 및 Embodied Intelligence를 위한 통합 Agent Framework인 StreamingClaw 를 제안한다. StreamingClaw는 OpenClaw 호환 프레임워크로, Real-time, Multimodal Streaming Interaction을 지원하며 다음 다섯 가지 핵심 기능을 통합한다: (1) Multimodal Inputs에 대한 Real-time Streaming Reasoning 지원, (2) Online Evolution of Interaction Objectives 하에서 미래 Event Reasoning 및 Proactive Interaction 지원, (3) Real-time Streaming Scenarios에 최적화된 Multimodal Long-term Storage, Hierarchical Evolution, 그리고 Multiple Agents 간의 Shared Memory에 대한 효율적인 Retrieval 지원, (4) Perception–Decision–Action의 Closed-loop 지원 및 Streaming Tools와 Action-centric Skills 제공, (5) OpenClaw Framework와의 호환성을 통한 광범위한 리소스 활용.
StreamingClaw의 Pipeline은 Multi-end Inputs과 User Query가 Main–Sub Agents로 전달되어 Perception 및 Decision-making을 수행하고, Agent가 생성한 Instructions이 Tools 및 Skills 실행을 안내하며, 그 결과가 다시 Agents로 Feedback되어 Perception–Decision–Action의 Closed-loop를 형성한다
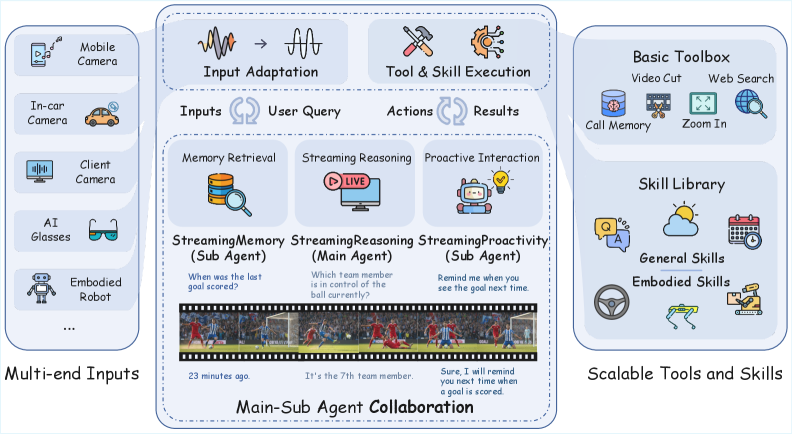
Main Agent인 StreamingReasoning Agent 는 연속적인 Streaming Video Inputs 및 Outputs 환경에서 Real-time Perception, Understanding, Reasoning을 Low-latency Constraints 하에 달성하는 것을 목표로 한다. 이를 위해 Dynamic Sliding Window Mechanism 을 통해 최신 시간 Window 내의 Visual 및 Textual Context만 유지하여 Context Length 및 GPU Memory Overhead를 제어한다. 또한, Streaming KV-Cache 를 도입하여 각 Incremental Inference Step에서 Cached KV Tokens을 재사용하고 새로 도착한 Chunks에 대한 Incremental Tokens만 계산함으로써 Stable Throughput 및 Low Latency를 달성한다. StreamingReasoning은 Attention-based Contribution Scores 기반의 KV-Cache Pruning을 통해 Attention Computation 및 Inference Overhead를 추가로 줄인다. StreamingReasoning Agent는 Task Parsing 및 Categorization, Memory Retrieval Path, Proactive Interaction Decision Path, 그리고 No-memory and No-proactive-interaction Path를 포함하는 Self-Planning Scheduling Mechanism을 통해 Sub-agents를 자율적으로 계획하고 스케줄링한다
Sub-agent인 StreamingMemory Agent 는 Multimodal Memory Storage, Hierarchical Memory Evolution, Efficient Memory Retrieval, 그리고 Cross-Agent Unified Memory를 통해 Streaming Video Understanding의 Long-term Contextual Support를 제공한다
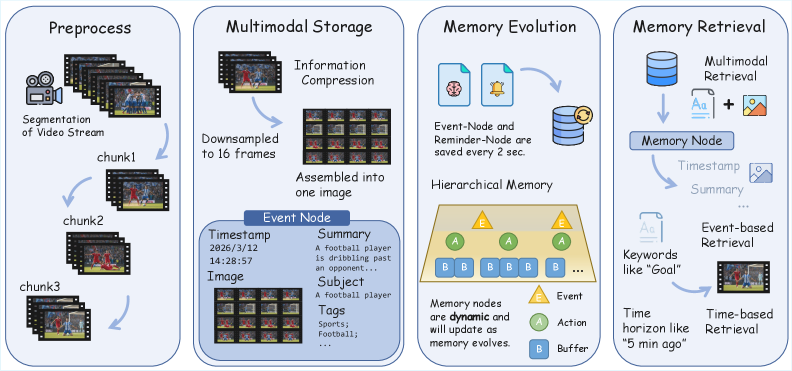
특히 Hierarchical Memory Evolution (HME) Mechanism은 Memory를 Segments → Atomic Actions → Events의 Multi-level Summary Hierarchy로 진화시켜 Short-term, Fine-grained Memories를 Long-term, Stable, Structured Memories로 변환하여 Semantic Accessibility 및 Retrieval Robustness를 향상시킨다. Efficient Memory Retrieval은 Command-driven , High-concurrency , Self-directed Temporal Traversal 전략을 통해 Unproductive Traversal의 Computational Overhead를 줄이고 Retrieval Quality를 유지한다.
또 다른 Sub-agent인 StreamingProactivity Agent 는 Future-event Prediction, Reasoning, Proactive Interaction을 위해 설계되었다. 이는 Time-aware Interaction과 Event-grounding Interaction의 두 가지 Proactive Interaction Scenarios를 지원하며 [Figure 4], Training-free Adaption 및 Training Adaption 의 두 가지 Distinct Paradigms을 통해 구현된다 [Figure 5, Figure 6]. Training-free Adaption은 Reminder Node Generation, Proactive Response Matching, Proactive Objective Evolution 3단계로 구성되며, 추가 Training 없이 Proactive Interaction Objective에 일반화되고 Real-time Objective Evolution을 지원한다. Training Adaption은 Visual-language-driven Training Scheme을 통해 Domain-specific Proactive Perception Scenarios를 지원하며, Silent Inference 및 Non-silent Inference 설정을 통해 Proactive Signals 및 Reasoning Responses를 생성한다. StreamingClaw는 또한 Video Cut 및 Call Memory 와 같은 Specialized Tools 및 Embodied Vehicle Driver Monitoring System , Embodied Robot Household Care , AI Glasses Education Tutor 와 같은 Embodied-interaction Skills를 포함하는 확장 가능한 Tools and Skills Library를 갖추어 Perception–Decision–Action Closed Loop의 마지막 연결을 완성한다.
4. Conclusion & Impact (결론 및 시사점)
StreamingClaw는 Real-time Perception–Decision–Action Closed Loop 기능을 요구하는 Embodied Intelligence와 같은 Scenarios를 위해 제안된 통합적이고 확장 가능한 Agent Framework이다. 이 Framework는 Low-latency Online Inference, Long-term Memory, 그리고 Proactive Interaction 측면에서 기존 비디오 Agent들의 한계를 해결한다. StreamingClaw는 Real-time Video Ingestion 및 Streaming Inference를 통해 Low-latency Response를 지원하며, Sub-agents를 통한 Future-event Reasoning 및 Proactive Interaction Decision-making을 가능하게 하여 시스템이 Continuous Input 하에서 더욱 능동적으로 Tasks를 실행하고 상호작용에 참여할 수 있도록 한다. 계층적 Multimodal Memory 시스템은 Long-duration Continuous Scenarios에서 정보 축적 및 활용 문제를 해결하며, 광범위한 Application Scenarios를 포괄하는 Tool Library 및 Skill Library는 High-level Understanding과 Decisions를 실행 가능한 Actions으로 신뢰성 있게 전환하여 Cross-scenario Generality 및 Deployability를 향상시킨다. 궁극적으로 StreamingClaw는 OpenClaw Framework와 호환되며, Online Real-time Perception 및 Reasoning, Long-term Memory, Proactive Interaction, 그리고 Extensible Action Capabilities를 유기적으로 통합하여 Embodied Intelligence 및 Autonomous Driving 분야의 발전과 실제 세계 배포에 큰 기여를 할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Omni-DuplexEval: Evaluating Real-time Duplex Omni-modal Interaction
- [논문리뷰] ColorAgent: Building A Robust, Personalized, and Interactive OS Agent
- [논문리뷰] Scaling Mixture-of-Experts Video Pretraining for Embodied Intelligence
- [논문리뷰] RoboDojo: A Unified Sim-and-Real Benchmark for Comprehensive Evaluation of Generalist Robot Manipulation Policies
- [논문리뷰] VLA-Corrector: Lightweight Detect-and-Correct Inference for Adaptive Action Horizon
Review 의 다른글
- 이전글 [논문리뷰] PLDR-LLMs Reason At Self-Organized Criticality
- 현재글 : [논문리뷰] StreamingClaw Technical Report
- 다음글 [논문리뷰] T-MAP: Red-Teaming LLM Agents with Trajectory-aware Evolutionary Search
댓글