[논문리뷰] Unify-Agent: A Unified Multimodal Agent for World-Grounded Image Synthesis
링크: 논문 PDF로 바로 열기
저자: Shawn Chen, Quanxin Shou, Hangting Chen, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Unify-Agent : World-grounded image synthesis를 위해 제안된 end-to-end unified multimodal agent로, Think, Research, Recaption, Generate의 4단계 파이프라인을 수행합니다.
- FactIP : 12개 카테고리로 구성된 2,462개의 프롬프트를 포함하는 benchmark로, rare identity 및 long-tail factual concept에 대한 모델의 사실적 충실도(factual faithfulness)를 평가합니다.
- Evidence-Grounded Recaptioning : 수집된 외부 정보(textual/visual evidence)를 단순히 주입하는 대신, 모델이 이를 generation-oriented 구조화된 텍스트로 변환하여 생성 과정을 제어하는 핵심 메커니즘입니다.
- Bagel : Unify-Agent의 기반이 되는 Mixture-of-Transformers(MoT) 아키텍처 기반의 foundation model로, visual understanding과 generation을 통합합니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 기존의 Text-to-Image(T2I) 모델들은 고품질 이미지 생성 능력은 탁월하지만, 학습 데이터에 포함되지 않은 long-tail 개념이나 특정 인물, 문화적 상징 등 외부 세계 지식이 요구되는 상황에서 identity drift나 환각(hallucination) 문제를 겪습니다. 현재의 모델들은 고정된 parametric memory에 의존하는 closed-book 방식이기에 실시간으로 새로운 세계 지식을 반영하기 어렵습니다. 또한 기존 agentic 파이프라인은 retrieval 툴과 모델이 느슨하게 결합되어 있어, 연쇄적인 오류를 유발하고 multimodal reasoning과 시각적 생성 과정을 분리시킨다는 한계가 있습니다. 이러한 문제를 극복하기 위해 저자들은 reasoning, searching, generation이 긴밀하게 통합된 agentic 프레임워크를 제안합니다.
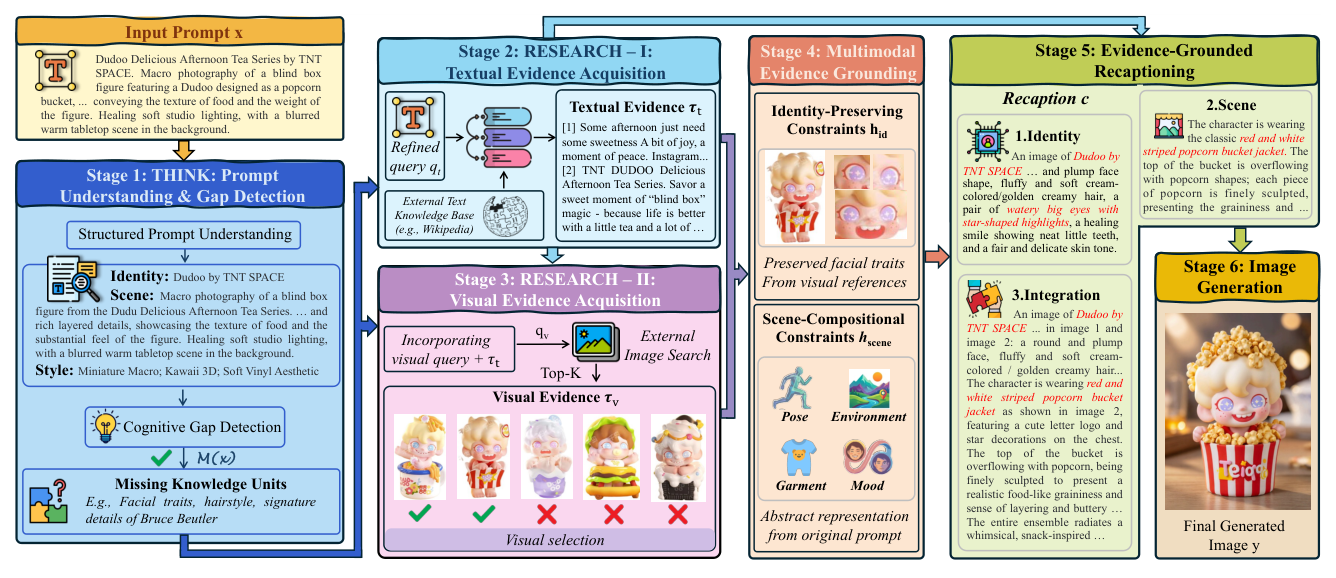
는 이러한 통합 파이프라인을 시각적으로 잘 보여줍니다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과) Unify-Agent는 text-to-image 생성 과정을 능동적인 의사결정 과정으로 재정의합니다. 모델은 우선 Cognitive Gap Detection 을 통해 외부 지식이 필요한지 판단하고, Research 단계를 거쳐 텍스트와 이미지 형태의 증거를 수집합니다. 수집된 raw 데이터는 Recaptioning 모듈을 통해 identity를 유지하면서도 생성 모델에 최적화된 구조적 제약 조건으로 변환됩니다. 마지막으로, VAE의 저수준 latent와 ViT의 고수준 의미론적 토큰을 결합한 Visual Synthesis 가 진행됩니다. 실험 결과,
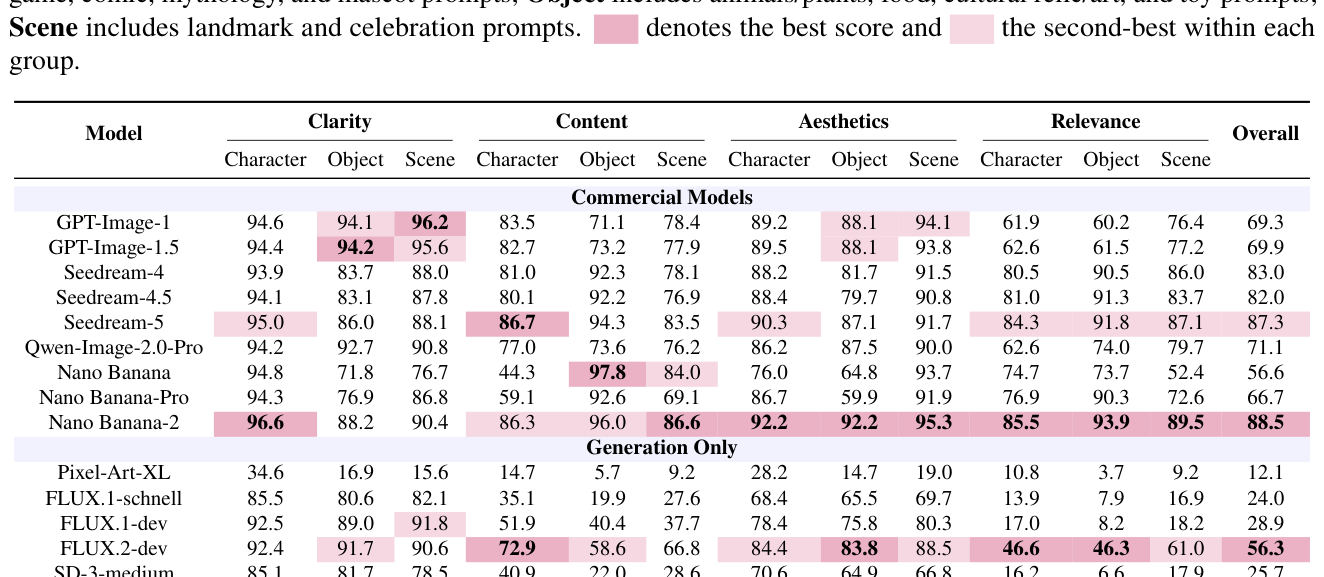
에 따르면 Unify-Agent는 FactIP 벤치마크에서 73.2의 Overall score를 기록하며, 기존의 강력한 모델인 Bagel 대비 22점 이상, 그리고 FLUX.1-dev 및 SD-3.5-large 와 같은 강력한 generation-only 모델들을 큰 격차로 앞서는 성능을 보였습니다. 특히 Relevance 점수에서 압도적인 수치를 기록하여 사실적 충실도가 크게 개선되었음을 입증했습니다.
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 이미지 생성을 passive mapping에서 active inference-time process로 전환함으로써, 복잡한 세계 지식이 요구되는 이미지 생성 환경에서 신뢰성 있는 결과를 도출할 수 있음을 증명했습니다. Unify-Agent 는 다양한 개념에 대해 정확한 identity를 보존하며 지식 기반 생성이 가능하다는 점을 입증하여 향후 개방형 생성 모델 연구의 이정표를 제시했습니다. 이 접근법은 향후 더 복잡한 에이전트 행동을 지원하는 multimodal 시스템의 확장 가능성을 열어주며, 학계와 산업계 전반에 걸쳐 보다 사실적이고 제어 가능한 AI 생성 모델 발전에 기여할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] VisualClaw: A Real-Time, Personalized Agent for the Physical World
- [논문리뷰] SoCRATES: Towards Reliable Automated Evaluation of Proactive LLM Mediation across Domains and Socio-cognitive Variations
- [논문리뷰] Agent Skills Should Go Beyond Text: The Case for Visual Skills
- [논문리뷰] Function2Scene: 3D Indoor Scene Layout from Functional Specifications
- [논문리뷰] WorldMemArena: Evaluating Multimodal Agent Memory Through Action-World Interaction
Review 의 다른글
- 이전글 [논문리뷰] Think Anywhere in Code Generation
- 현재글 : [논문리뷰] Unify-Agent: A Unified Multimodal Agent for World-Grounded Image Synthesis
- 다음글 [논문리뷰] VGGRPO: Towards World-Consistent Video Generation with 4D Latent Reward
댓글