[논문리뷰] Revision or Re-Solving? Decomposing Second-Pass Gains in Multi-LLM Pipelines
링크: 논문 PDF로 바로 열기
Part 1: 요약 본문
메타데이터
저자: Jingjie Ning, Xueqi Li, Chengyu Yu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Second-Pass Gain : 첫 번째 모델(Generator)의 초안(Draft)을 두 번째 모델(Reviewer)이 검토하여 최종 성능이 향상되는 효과를 지칭합니다.
- Re-solving Effect : Reviewer 모델이 초안의 도움 없이 독립적으로 문제를 다시 풀어 정답을 맞히는 능력에서 기인하는 성능 향상분을 의미합니다.
- Scaffold Effect : 초안의 실제 내용(Semantics)과 무관하게, Reviewer에게 특정 형식의 입력(Empty but structured draft)을 제공함으로써 발생하는 프롬프트 프레임워크상의 이득입니다.
- Content Effect : 초안에 포함된 구체적인 정보(Semantics)가 Reviewer의 판단에 미치는 영향으로, 양수일 경우 성능 개선을, 음수일 경우 성능 저하를 유발합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Multi-LLM revision 파이프라인에서 발생하는 성능 향상이 진정한 의미의 '오류 수정'인지, 아니면 다른 요인에 의한 것인지를 파악하고자 합니다. 기존 연구들은 대체로 리뷰 파이프라인의 전체적인 성능 향상만을 측정할 뿐, 이 이득이 독립적인 재해결(Re-solving), 프레임워크 제공(Scaffold), 혹은 초안의 내용(Content) 중 무엇에 기인하는지 정밀하게 분리하지 못했습니다. 저자들은 이러한 혼란을 해결하기 위해, 초안의 내용과 구조를 제어할 수 있는 4가지 실험 조건을 설계하여 성능 이득을 체계적으로 분해합니다 [Figure 1]. 이를 통해 고전적인 수정 전략이 모든 태스크에 유효한지 검증하는 것이 본 연구의 핵심입니다.

Figure 1 — 4가지 조건에 기반한 성능 분해 개념도
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Four-Condition Design 을 통해 성능 이득을 Additive하게 분해하는 프레임워크를 제안합니다. 이 방법론은 Generator 기반 성능($x_1$), 표준 Revision($x_2$), 독립 재해결 제어($x_3$), 구조화된 Null 초안 제어($x_4$)를 비교하여 세 가지 효과를 각각 산출합니다. 실험 결과, MCQ (Multiple-Choice Question) 태스크에서는 성능 향상의 대부분이 강한 모델의 독립적인 Re-solving 효과에 기인하며, 초안의 Content 이득은 통계적으로 유의미하지 않음이 확인되었습니다 [Table 1]. 반면, Code Generation 에서는 정반대의 결과가 나타나는데, 초안의 Content 는 오히려 성능에 부정적인 영향을 미치며, 전체 이득은 Scaffold 에 의해 주도됨을 밝혔습니다 [Table 2]. 특히 코드 생성의 경우 문제 난이도가 높아질수록 초안의 내용이 주는 부정적 영향이 심화되는 경향을 보입니다 [Figure 4].
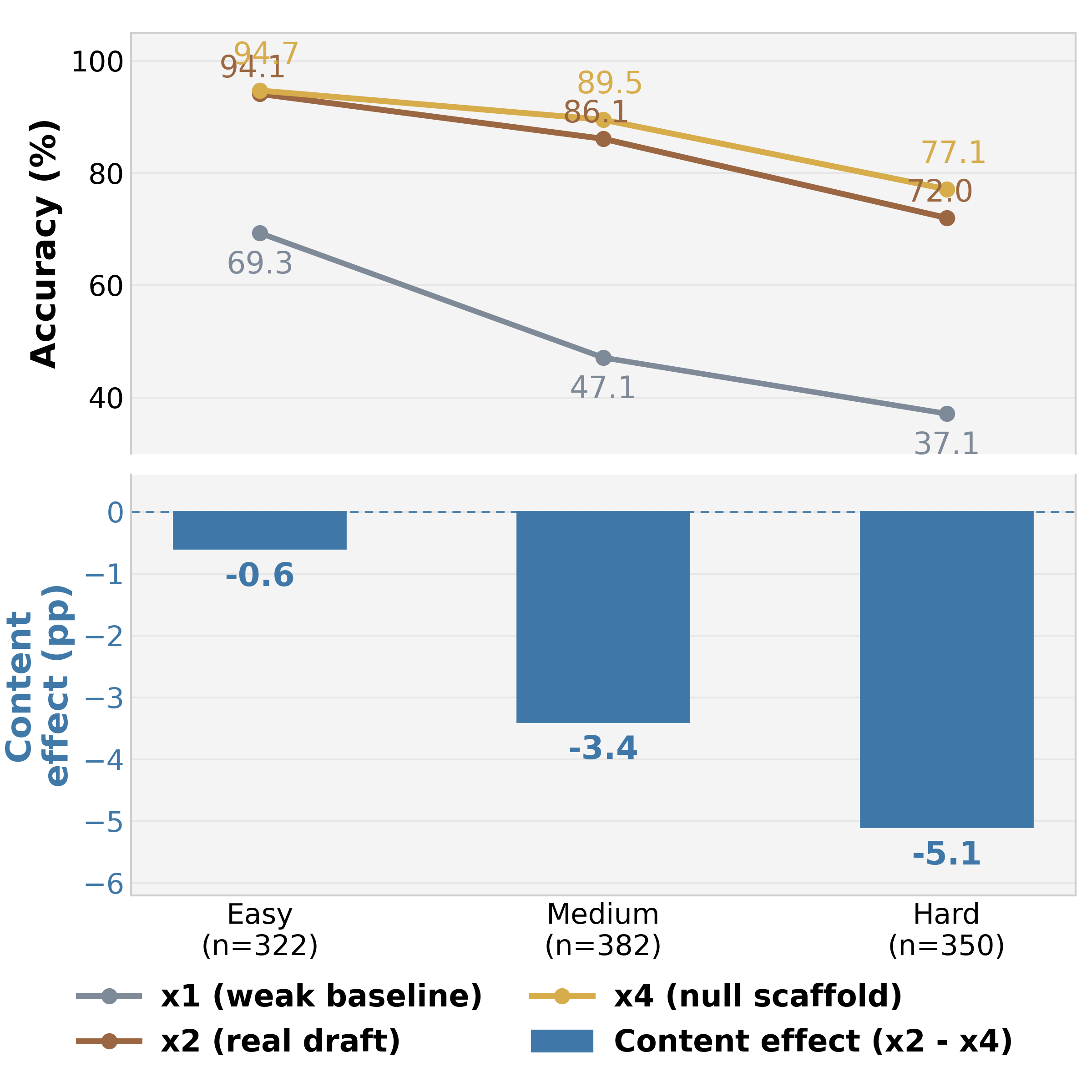
Figure 4 — 코드 난이도에 따른 Content 효과 변화
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Multi-LLM revision이 보편적인 오류 수정 메커니즘이 아니며, 태스크의 구조와 초안의 품질에 따라 그 실질적인 이득이 다르게 나타남을 증명했습니다. 학계 및 산업계에서 LLM 파이프라인을 설계할 때, 단순히 '더 강한 모델을 리뷰어로 붙이는' 방식보다는 태스크 특성에 맞춘 접근이 필수적입니다. 지식 집약적인 MCQ 문제에는 더 강한 모델로 바로 라우팅하는 전략이 효율적일 수 있으며, 코드 생성과 같은 구조적 태스크에서는 초안의 구체적인 내용보다는 구조적 틀(Scaffold)을 제공하는 방식이 유리합니다. 본 논문은 이러한 통찰을 바탕으로 더 타겟팅된(Targeted) 파이프라인 설계를 제안합니다.

Figure 2 — 모델별 성능 이득 요소 분해 결과
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Recursive Think-Answer Process for LLMs and VLMs
- [논문리뷰] OCR-Agent: Agentic OCR with Capability and Memory Reflection
- [논문리뷰] THOR: Tool-Integrated Hierarchical Optimization via RL for Mathematical Reasoning
- [논문리뷰] Nemotron-Labs-Diffusion-Image: Advancing Masked Discrete Diffusion for High-Resolution Image Synthesis
- [논문리뷰] No Resource, No Benchmarks, No Problem? Evaluating and Improving LLMs for Code Generation in No-Resource Languages
Review 의 다른글
- 이전글 [논문리뷰] Reasoning Shift: How Context Silently Shortens LLM Reasoning
- 현재글 : [논문리뷰] Revision or Re-Solving? Decomposing Second-Pass Gains in Multi-LLM Pipelines
- 다음글 [논문리뷰] Terminal Agents Suffice for Enterprise Automation
댓글