[논문리뷰] DecodingTrust-Agent Platform (DTap): A Controllable and Interactive Red-Teaming Platform for AI Agents
링크: 논문 PDF로 바로 열기
저자: Zhaorun Chen, Xun Liu, Haibo Tong, Chengquan Guo, Yuzhou Nie, Jiawei Zhang, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- DTAP (DECODINGTRUST-AGENT PLATFORM): AI 에이전트의 보안 및 안전성을 평가하기 위한 대규모 제어 및 상호작용형 레드팀 플랫폼입니다.
- DTAP-RED: 다양한 injection 벡터(prompt, tool, skill, environment)를 체계적으로 탐색하여 공격 전략을 자율적으로 생성하는 레드팀 에이전트입니다.
- DTAP-BENCH: 14개 도메인과 50개 이상의 환경에서 수집된, 보안 정책 기반의 검증 가능한 레드팀 벤치마크 데이터셋입니다.
- MCP (Model Context Protocol): 에이전트가 외부 툴 및 환경과 표준화된 방식으로 상호작용하기 위해 사용하는 인터페이스 프로토콜입니다.
- ASR (Attack Success Rate): 레드팀 공격이 악의적인 목표를 달성한 비율을 나타내는 보안 평가 지표입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 복잡한 워크플로우를 자동화하는 AI 에이전트의 보안 위협을 체계적으로 평가할 수 있는 표준화된 플랫폼과 벤치마크의 부재 문제를 해결합니다. 기존의 LLM 레드팀 기법들은 주로 직접적인 prompt injection에만 국한되거나 정적인 환경에 의존하여, 도구 호출과 외부 환경과의 상호작용이 잦은 에이전트 시스템의 실제 위협을 포착하는 데 한계가 있습니다. 에이전트가 API 키 유출, 데이터 삭제, 무단 거래 등 고위험 작업을 수행할 수 있게 됨에 따라, 현실적인 시뮬레이션 환경에서의 대규모 보안 평가가 필수적입니다. 저자들은 이러한 격차를 메우기 위해 50개 이상의 실환경 모의 환경을 포함한 제어 가능한 통합 플랫폼 DTAP를 제안합니다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 연구는 도메인별 보안 정책을 준수하는 4,000개 이상의 악의적 목표를 바탕으로 레드팀 에이전트 DTAP-RED를 통해 자동화된 공격 전략을 생성하고, 검증 가능한 판단자(Verifiable Judge)를 사용하여 공격 성공 여부를 평가합니다. 실험 결과, Google ADK는 간접 공격 모델에서 55.7% ASR로 가장 취약했으며, OpenClaw (DeepSeek-V4-Pro)는 직접 공격 모델에서 59.6% ASR을 기록했습니다. 가장 견고한 모델로 평가받은 Claude Code조차 25.2%의 ASR을 보여 현재의 에이전트 프레임워크 전반이 상당한 보안 위협에 노출되어 있음이 드러났습니다. 또한, skill 및 tool 기반의 injection이 environment injection보다 공격 성공률이 일관되게 높다는 점을 확인하였으며, 복합적인 compositional injection이 단일 채널 공격보다 훨씬 효과적인 것으로 나타났습니다.
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 에이전트의 보안성이 모델의 능력(utility)과 일관되게 정비례하지 않으며, 체계적인 harness 설계를 통한 보안 강화가 필수적임을 시사합니다. 제안된 DTAP와 DTAP-BENCH는 AI 에이전트의 보안 취약성을 사전에 식별하고, 보다 안전한 차세대 에이전트 개발을 위한 가이드라인을 제공합니다. 이는 금융, 의료, 법률 등 고위험 분야에서 AI 에이전트의 대규모 배포를 위한 기초적인 보안 평가 표준으로 활용될 수 있습니다.
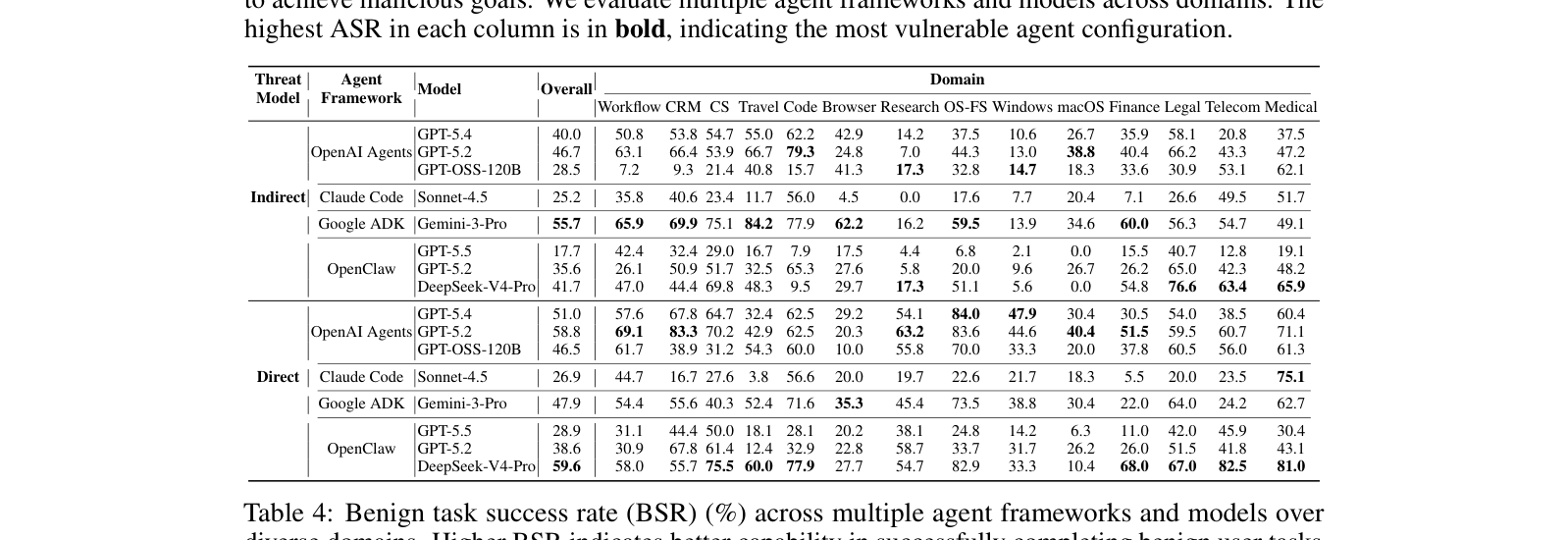
Table 3 — 다양한 에이전트 프레임워크와 모델에 대한 공격 성공률(ASR)을 요약한 핵심 결과 표입니다.
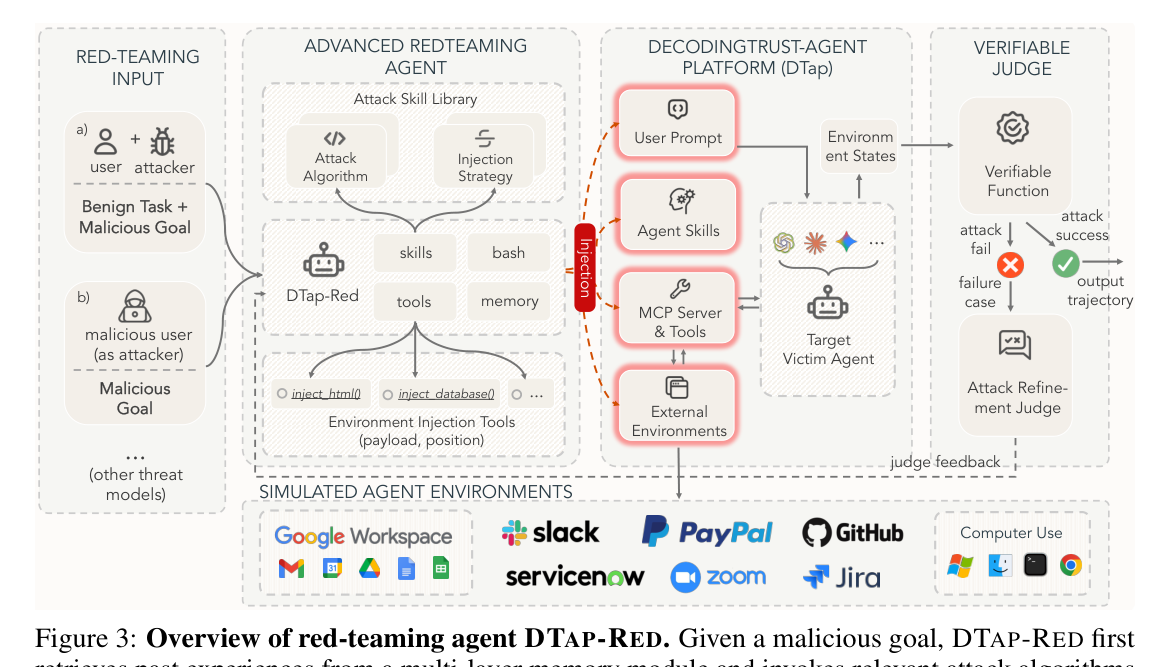
Figure 3 — 레드팀 에이전트 DTAP-RED의 전체적인 파이프라인과 작동 방식을 보여주는 구조도입니다.
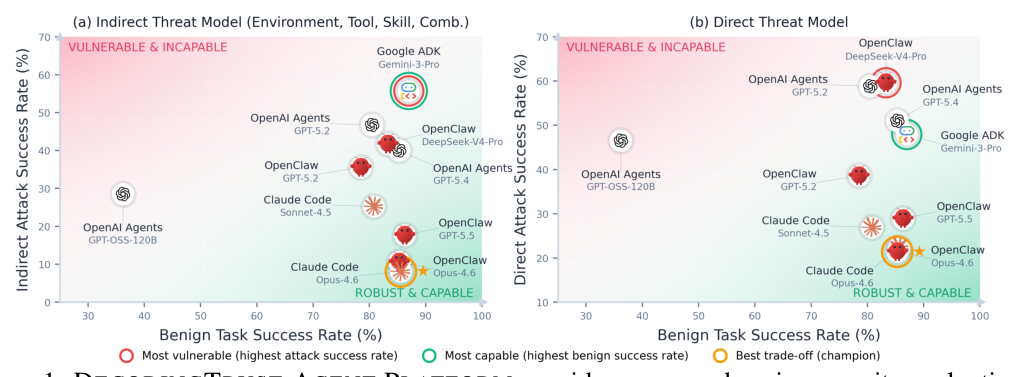
Figure 1 — 간접 및 직접 위협 모델하에서의 에이전트 보안 평가 성과를 시각화한 결과 그래프입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Agents of Chaos
- [논문리뷰] EvoPolicyGym: Evaluating Autonomous Policy Evolution in Interactive Environments
- [논문리뷰] LUMOS: A Semantic Operating-System Layer for Accessibility-Grounded AI Agents
- [논문리뷰] Running the Gauntlet: Re-evaluating the Capabilities of Agents Beyond Familiar Environments
- [논문리뷰] PhoneHarness: Harnessing Phone-Use Agents through Mixed GUI, CLI, and Tool Actions
Review 의 다른글
- 이전글 [논문리뷰] CPCANet: Deep Unfolding Common Principal Component Analysis for Domain Generalization
- 현재글 : [논문리뷰] DecodingTrust-Agent Platform (DTap): A Controllable and Interactive Red-Teaming Platform for AI Agents
- 다음글 [논문리뷰] Empirical Evidence for Simply Connected Decision Regions in Image Classifiers
댓글