[논문리뷰] From Pixels to Concepts: Do Segmentation Models Understand What They Segment?
링크: 논문 PDF로 바로 열기
메타데이터
저자: Shuang Liang, Zeqing Wang, Yuxian Li, Xihui Liu, Han Wang
1. Key Terms & Definitions (핵심 용어 및 정의)
- Promptable Concept Segmentation (PCS): 텍스트 프롬프트를 통해 명사구나 개념을 직접 입력받아 해당 영역의 마스크를 생성하는 종단간(End-to-End) 세분화 프레임워크입니다.
- CAFE (Counterfactual Attribute Factuality Evaluation): 타겟 영역의 위치를 유지하면서 표면 패턴, 맥락, 재질 등의 속성을 조작하여 모델이 semantically invalid한 개념에 어떻게 반응하는지 평가하는 벤치마크입니다.
- Superficial Mimicry (SM): 대상의 표면 패턴을 다른 범주와 유사하게 변경하여 시각적 혼동을 유발하는 counterfactual 시나리오입니다.
- Ontological Conflict (OC): 대상의 본질적인 재질이나 속성을 변경하여 객체의 실체적 정의와 시각적 정보 간의 불일치를 유발하는 시나리오입니다.
- Concept Swap Rate (CSR): 정답(positive) 프롬프트에 대한 타겟 마스크 생성에 실패하고, 동시에 오답(negative) 프롬프트에 대해 높은 신뢰도의 잘못된 마스크를 생성하는 현상을 측정하는 지표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 최신 promptable segmentation 모델들이 시각적 살점(salient cues)에 과도하게 의존하여 semantically invalid한 프롬프트에도 정확한 마스크를 생성하는 '개념적 기반(concept-faithful grounding)'의 결여 문제를 해결하고자 합니다 [Figure 1]. 기존 연구들은 주로 mask accuracy나 객체 존재 여부만을 평가하여 모델이 프롬프트의 의미를 실제로 이해하는지, 아니면 단순한 'shortcut-driven' 반응을 보이는지 명확히 구분하지 못합니다. 특히 특정 속성(재질, 맥락 등)이 교묘하게 조작된 환경에서도 모델이 과신(overconfidence)하는 문제를 진단할 필요성이 대두되었습니다. 본 연구는 이를 위해 제어된 속성 수준의 counterfactual intervention을 적용한 CAFE 벤치마크를 제안합니다 [Figure 2].

Figure 1 — CAFE 벤치마크 예시
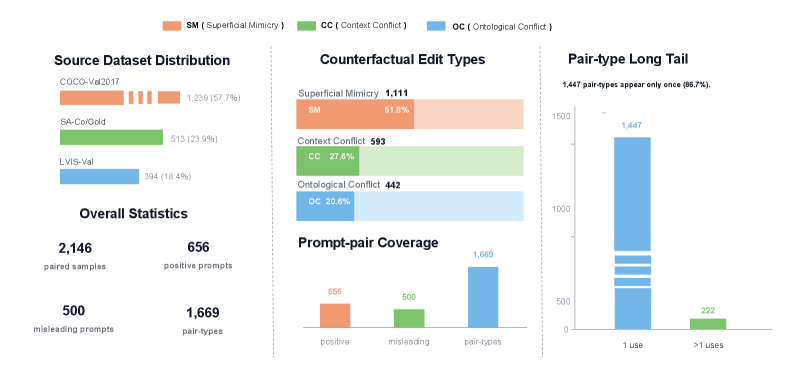
Figure 2 — CAFE 벤치마크 통계 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Superficial Mimicry(SM), Context Conflict(CC), Ontological Conflict(OC)라는 세 가지 속성 조작을 통해 2,146개의 paired test samples로 구성된 CAFE 벤치마크를 구축하였습니다 [Figure 2]. 제안하는 방법론은 모델이 positive prompt에 대해서는 정확한 마스크를 유지하면서도, semantically invalid한 negative prompt에 대해서는 confidence score를 낮추어 거부(rejection)하도록 평가하는 구조를 갖습니다. 실험 결과, 대부분의 기존 end-to-end 및 framework 기반 모델들은 positive prompt localization 성능은 우수하나, 특히 OC 시나리오에서 부정적인 IL_MCC 수치를 기록하며 의미적 불일치를 전혀 식별하지 못함을 확인했습니다 [Table 2]. 반면, MLLM 기반의 검증 에이전트(CAFE-SAM3)를 도입할 경우, 모델의 전체적인 cgF_1_ 성능이 38.5에서 63.3으로 크게 향상되었으며, 특히 OC에서 FPR이 66.3%에서 29.2%로 대폭 감소하였습니다 [Table 3]. 이러한 정량적 결과는 명시적 추론(explicit reasoning) 단계가 도입될 때 모델이 시각적 속성 숏컷에서 벗어나 진정한 개념 기반의 grounding을 수행할 수 있음을 입증합니다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 promptable segmentation 모델이 단순히 마스크를 생성하는 단계를 넘어, 입력된 개념의 의미적 타당성을 검증해야 함을 강조합니다. 연구진이 구축한 CAFE 벤치마크는 모델의 개념적 신뢰성을 진단하는 표준적인 기준을 제시하며, 시각적 정보와 의미적 정보 간의 모순을 해결하는 능력이 차세대 비전 모델의 핵심 과제임을 시사합니다. 본 연구의 결과는 향후 더 견고하고 인간의 인지 체계와 부합하는 비전-언어 시스템 개발에 중요한 가이드라인을 제공할 것으로 기대됩니다.
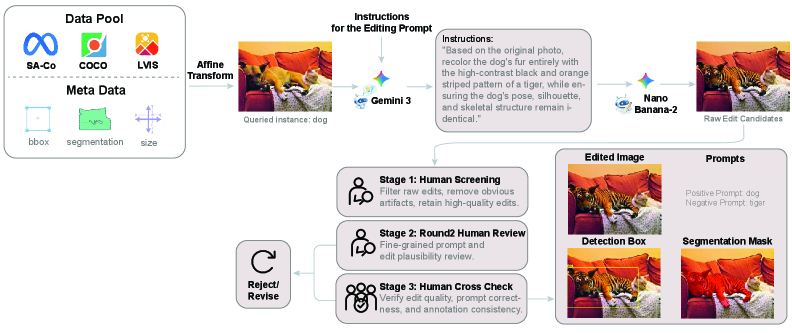
Figure 3 — CAFE 데이터셋 어노테이션 파이프라인
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Accurate, Interdisciplinary and Transparent Structure-property Understanding with Deep Native Structural Reasoning
- [논문리뷰] ClinHallu: A Benchmark for Diagnosing Stage-Wise Hallucinations in Medical MLLM Reasoning
- [논문리뷰] WorldBench: A Challenging and Visually Diverse Multimodal Reasoning Benchmark
- [논문리뷰] RoboSemanticBench: Diagnosing Semantic Grounding in Action Prediction for VLA Models
- [논문리뷰] GenClaw: Code-Driven Agentic Image Generation
Review 의 다른글
- 이전글 [논문리뷰] Frequency Bias and OOD Generalization in Neural Operators under a Variable-Coefficient Wave Equation
- 현재글 : [논문리뷰] From Pixels to Concepts: Do Segmentation Models Understand What They Segment?
- 다음글 [논문리뷰] HAGE: Harnessing Agentic Memory via RL-Driven Weighted Graph Evolution
댓글