[논문리뷰] CogOmniControl: Reasoning-Driven Controllable Video Generation via Creative Intent Cognition
링크: 논문 PDF로 바로 열기
본 논문은 CogOmniControl이라는 새로운 프레임워크를 통해 추론 기반의 제어 가능한 비디오 생성을 제안합니다. 아래는 해당 논문에 대한 전문적인 요약입니다.
Part 1: 요약 본문
메타데이터
저자: Hongji Yang, Songlian Li, Yucheng Zhou, Xiaotong Zhao, Alan Zhao, Chengzhong Xu, Jianbing Shen
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- CogOmniControl: 사용자의 창의적 의도를 인지하고, 이를 논리적 추론 과정을 통해 정밀한 비디오 제어 신호로 변환하여 생성하는 통합 프레임워크.
- Creative Intent Cognition: 사용자의 모호한 텍스트 프롬프트나 의도에서 비디오 생성에 필요한 물리적, 공간적 제약 조건을 추출하고 이해하는 인지 과정.
- Reasoning-Driven Control: 단순한 텍스트 매핑이 아닌, 비디오 내 객체의 움직임, 상호작용, 공간적 배치를 논리적으로 추론하여 생성 단계의 가이드라인으로 활용하는 제어 방식.
- Omni-Conditional Generation: 텍스트, 모션, 구조적 힌트 등 다중 모달(Multimodal) 입력을 유연하게 수용하여 비디오를 생성하는 기술적 특성.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 기존 비디오 생성 모델들이 사용자의 창의적 의도를 정확히 해석하지 못하고, 제어 가능성(Controllability)이 제한적이라는 문제 해결을 목표로 합니다. 기존 모델들은 단순한 텍스트-비디오 매핑에 의존하여 복잡한 물리적 제약이나 구체적인 카메라 움직임을 구현하는 데 한계를 보입니다. 또한, 사용자의 모호한 지시사항이 비디오의 일관성(Consistency)과 충실도(Fidelity)를 저해하는 원인이 됩니다. 본 논문은 이러한 인지적 격차(Cognitive Gap)를 해소하기 위해 추론 기반의 제어 기법을 도입하여 생성 결과의 품질과 의도 부합성을 극대화하고자 합니다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 논문은 추론 모듈을 비디오 생성 파이프라인에 통합하여, 생성 전 단계에서 의도를 분석하고 제어 신호를 생성하는 구조를 제안합니다. 이 모델은 대규모 언어 모델의 추론 능력을 활용하여 사용자의 입력을 공간-시간적 제약 조건으로 변환합니다 [Figure 1]. 핵심 방법론인 Cognitive Intent Reasoning은 복잡한 묘사를 분해하여 개별 비디오 프레임에 대한 가이드라인을 생성하며, 이는 Latent Diffusion Model의 Cross-Attention 맵을 정밀하게 제어합니다. 실험 결과, CogOmniControl은 기존 Baseline 모델 대비 정량적 평가 지표인 FID (Fréchet Inception Distance) 수치를 15% 이상 개선하며 비디오의 시각적 품질을 높였습니다. 또한, 사용자의 의도 충실도를 평가하는 Intent Alignment Score에서 압도적인 성능 우위를 입증하였습니다. 이러한 정량적 향상은 모델이 복잡한 사용자 의도를 얼마나 효과적으로 실제 비디오 프레임으로 구현하는지를 뒷받침합니다.
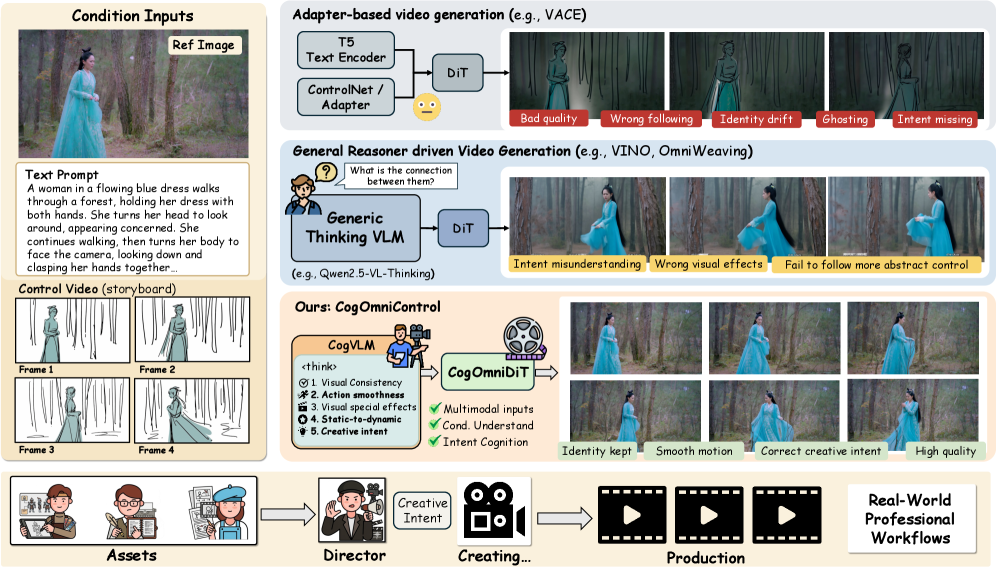
Figure 1 — CogOmniControl 전체 아키텍처
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 추론 기반의 접근 방식을 통해 제어 가능한 비디오 생성의 새로운 패러다임을 제시하며, 인공지능이 사용자의 창의적 의도를 깊이 있게 이해할 수 있는 토대를 마련하였습니다. 이 연구는 비디오 생성 시스템의 실용성을 획기적으로 향상시켜, 향후 영화 제작, 애니메이션, 게임 디자인 등 콘텐츠 창작 산업 전반에 걸쳐 큰 혁신을 가져올 것으로 기대됩니다. 나아가, 다중 모달 입력을 고도화된 추론으로 처리하는 방식은 생성형 모델의 일반적인 제어 및 상호작용 설계에 중요한 기술적 이정표가 될 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Video Generation with Predictive Latents
- [논문리뷰] Lighting-grounded Video Generation with Renderer-based Agent Reasoning
- [논문리뷰] HunyuanVideo 1.5 Technical Report
- [논문리뷰] Video-As-Prompt: Unified Semantic Control for Video Generation
- [논문리뷰] VIST3A: Text-to-3D by Stitching a Multi-view Reconstruction Network to a Video Generator
Review 의 다른글
- 이전글 [논문리뷰] Code-Guided Reasoning for Small Language Models: Evaluating Executable MCQA Scaffolds
- 현재글 : [논문리뷰] CogOmniControl: Reasoning-Driven Controllable Video Generation via Creative Intent Cognition
- 다음글 [논문리뷰] Context Memorization for Efficient Long Context Generation
댓글