[논문리뷰] Draft Less, Retrieve More: Hybrid Tree Construction for Speculative Decoding
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yuhao Shen, Tianyu Liu, Xinyi Hu, Quan Kong, Baolin Zhang, Jun Dai, Jun Zhang, Shuang Ge, Lei Chen, Yue Li, Mingcheng Wan, Cong Wang
1. Key Terms & Definitions (핵심 용어 및 정의)
- Speculative Decoding (SD): 경량 drafter 모델이 생성한 후보 토큰 트리를 고성능 target 모델이 병렬로 검증하여 전체 추론 속도를 높이는 패러다임.
- Dynamic-Depth Pruning: Drafter 모델의 신뢰도가 낮을 때 트리의 깊이를 동적으로 제한하여 계산 자원을 절약하는 기법.
- Graft: 동적 가지치기로 확보된 계산 예산(Budget)을 효율적인 retrieval 기반 후보로 재충전하여, 속도와 MAT(Mean Accepted Length) 간의 상충 관계를 개선하는 프레임워크.
- GPU-resident Adjacency Matrix: 토큰 간의 후속(Successor) 정보를 GPU 메모리에 상주시켜, CPU-GPU 간 통신 없이 실시간으로 retrieval을 수행하게 하는 자료구조.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 Tree-based Speculative Decoding이 겪고 있는 속도와 정확도(MAT) 사이의 Pareto tradeoff 문제를 해결하고자 한다. 최근의 동적 가지치기(Dynamic-depth pruning) 방식은 불필요한 연산을 줄여 속도를 높이나, 동시에 유효한 후보군까지 삭제함으로써 MAT가 정적 트리 모델보다 낮아지는 구조적 한계를 가진다 [Figure 1]. 이러한 pruning은 단순한 후보 제거가 아니라 '계산 자원(Budget)의 해제'로 보아야 하며, 기존 연구들은 이 자원을 효과적으로 재활용하지 못하고 단순히 버리는 문제점을 안고 있다. 따라서 본 연구는 해제된 budget을 retrieval 기반의 후보로 효율적으로 채워 넣음으로써, 전체 verification 비용을 유지하면서도 모델의 성능을 극대화하는 새로운 프레임워크를 제안한다.
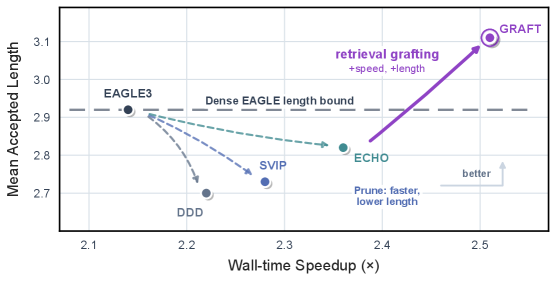
Figure 1 — 속도-MAT 트레이드오프 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문이 제안하는 Graft는 prune-then-graft 전략을 통해 고정된 verification budget 내에서 최적의 후보를 선택한다 [Figure 4]. 우선 calibrated threshold를 사용하여 불확실성이 높은 draft branch를 pruning하고, 그 자리에 GPU-resident adjacency matrix를 활용한 retrieval 후보를 root 중심의 병렬 처리를 통해 삽입한다 [Figure 4]. 이 retrieval 과정은 별도의 비싼 target 모델 호출 없이 경량의 matrix indexing으로 수행되며, target 모델의 검증 로그를 통해 실시간으로 업데이트된다.
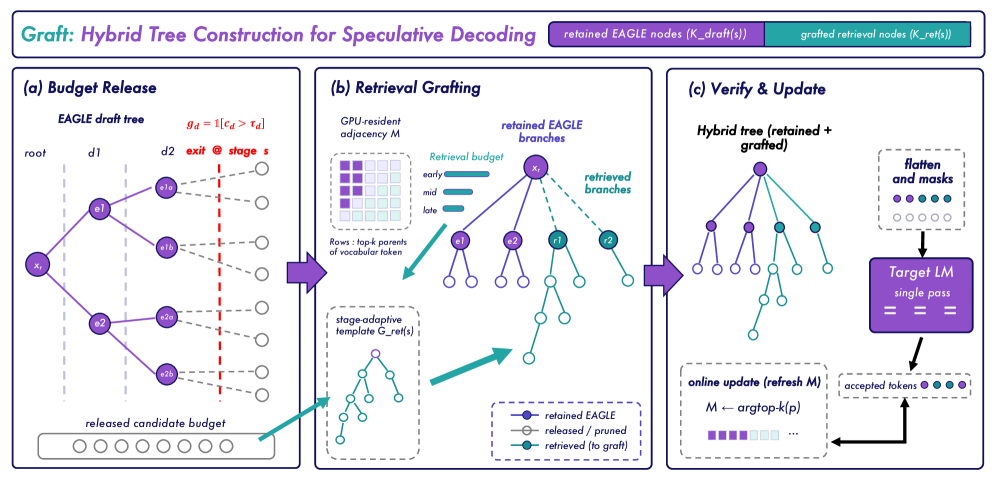
Figure 4 — Graft 전체 프레임워크
실험 결과, Graft는 다양한 환경에서 우수한 성능을 입증하였다.
- Short-context 벤치마크에서 Qwen3-235B 모델 기준 EAGLE-3 대비 최대 21.8% 향상된 평균 속도 개선을 달성하였다.
- Long-context 벤치마크에서는 LLaMA3.1-8B를 사용하여 평균 3.22× 속도 향상을 기록하였으며, EAGLE3-64K보다 16.6% 높은 성능을 보여주었다 [Table 1, Table 2].
- 이는 retrieval을 통해 pruning으로 인한 MAT 손실을 효과적으로 보상하면서도, 전체 연산 비용을 최적화한 결과이다 [Figure 5].
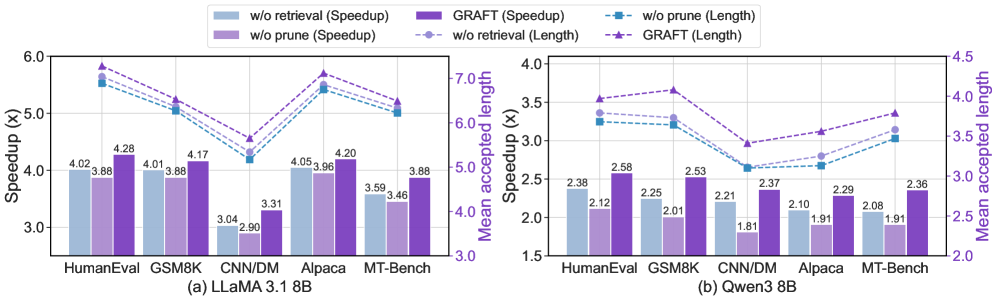
Figure 5 — 구성 요소별 성능 분석
4. Conclusion & Impact (결론 및 시사점)
본 논문은 동적 가지치기에서 발생하는 자원의 공백을 retrieval로 메우는 'Draft Less, Retrieve More' 원칙을 통해 기존 SD의 성능 한계를 돌파하였다. 이 연구는 복잡한 모델 수정이나 별도의 학습 없이 추론 효율을 극대화할 수 있는 강력한 기법을 제공한다. 특히, 산업계의 실제 LLM 서빙 환경에서 요구되는 고성능, lossless, 그리고 낮은 오버헤드 특성을 모두 만족시키며, 향후 block drafter나 다른 생성 기법으로의 확장 가능성을 제시하였다는 점에서 큰 시사점을 갖는다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Gemma 4 Technical Report
- [논문리뷰] A Sovereign, Open-Source Foundation Model for German and English
- [논문리뷰] HunyuanOCR-1.5: Making Lightweight OCR VLMs Faster and Better
- [논문리뷰] DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation
- [논문리뷰] BlockPilot: Instance-Adaptive Policy Learning for Diffusion-based Speculative Decoding
Review 의 다른글
- 이전글 [논문리뷰] DocAtlas: Multilingual Document Understanding Across 80+ Languages
- 현재글 : [논문리뷰] Draft Less, Retrieve More: Hybrid Tree Construction for Speculative Decoding
- 다음글 [논문리뷰] ESI-Bench: Towards Embodied Spatial Intelligence that Closes the Perception-Action Loop
댓글