[논문리뷰] Echo-Forcing: A Scene Memory Framework for Interactive Long Video Generation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Mingqiang Wu, Weilun Feng, Zhefeng Zhang, Haotong Qin, Yuqi Li, Guoxin Fan, Xiaokun Liu, Zhulin An, Libo Huang, Yongjun Xu, Chuanguang Yang
1. Key Terms & Definitions (핵심 용어 및 정의)
- KV Cache: 비디오 생성 과정에서 이전 프레임의 정보(Key, Value)를 저장하여 연산 효율을 높이는 캐시 메모리.
- Hierarchical Temporal Memory: 초기 앵커, 압축된 과거 정보, 최신 윈도우로 캐시를 계층화하여 장기적인 안정성과 국소적 연속성을 동시에 보장하는 기술.
- Scene Recall Frames: 전체 씬의 프레임을 모두 저장하는 대신, spatially structured KV representations로 씬 정보를 압축하여 효율적인 장기 회상을 지원하는 기법.
- Difference-aware Memory Decay: 새로운 씬과 과거 씬 간의 차이를 기반으로, 불일치하는 정보를 선택적으로 삭제(decay)하여 씬 전환 시 발생하는 잔류 의미(residual semantics)를 억제하는 기술.
- Relative RoPE: 긴 비디오 생성 시 절대적 시간 인덱스가 훈련 범위를 벗어나는 것을 방지하기 위해 캐시 내의 상대적 위치 정보를 활용하는 위치 인코딩 기법.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Autoregressive 비디오 확산 모델이 긴 비디오 생성 및 대화형 시나리오에서 겪는 기억 관리(KV Cache management)의 기능적 Entanglement 문제를 해결하고자 한다. 기존 연구들은 단순한 캐시 유지 전략을 사용하여 최신 동역학과 과거의 안정적인 앵커를 구분하지 않아, 씬 전환 시 이전의 불필요한 정보가 잔류하거나 새로운 프롬프트에 대한 반응이 지연되는 한계를 보였다 [Figure 1]. 저자들은 이러한 historical KV 상태를 단순한 캐시가 아닌 '보존(Preserve)', '회상(Recall)', '망각(Forget)'의 생애주기를 가진 능동적인 Scene Memory로 재정의하여 상호작용 가능한 긴 비디오 생성의 핵심 병목을 해결한다.

Figure 1 — Echo-Forcing의 4가지 주요 생성 모드
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 훈련 없이 적용 가능한 Echo-Forcing 프레임워크를 제안하여 긴 비디오 생성의 안정성과 대화형 제어 능력을 극대화하였다. Hierarchical Temporal Memory는 Bidirectional rolling early anchors, Drift-gated phase compression 등을 통해 초기 글로벌 참조와 최신 국소 정보를 체계적으로 관리한다 [Figure 2]. Scene Recall Frames는 씬 단위의 과거 기억을 spatially structured하게 압축하여 장기적 회상을 가능케 하며, Difference-aware Memory Decay는 씬 전환 시 기존 정보와 새로운 정보 간의 불일치도를 계산하여 Adaptive하게 불필요한 기억을 제거한다 [Figure 4].
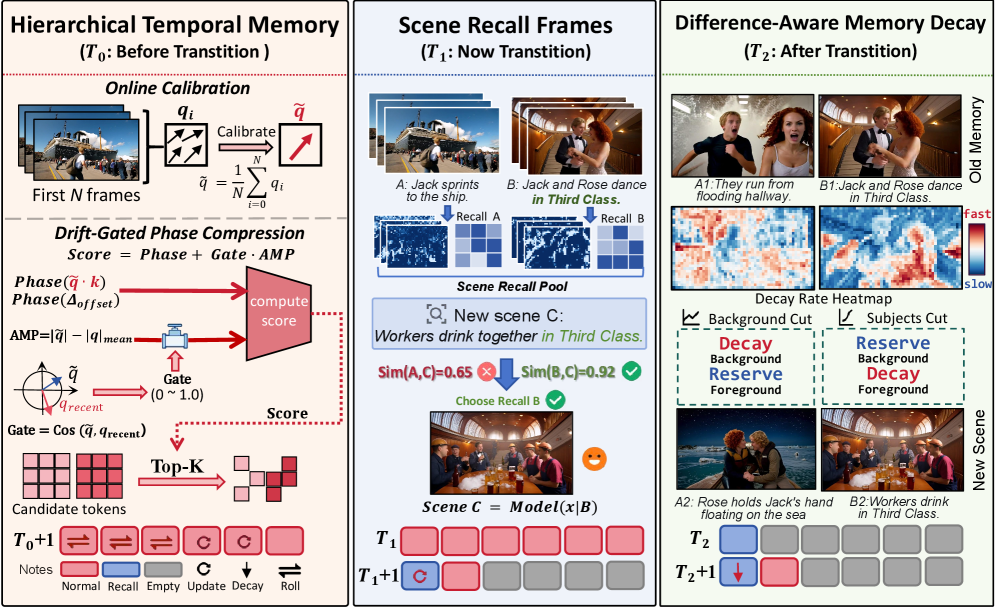
Figure 2 — Echo-Forcing 전체 프레임워크 아키텍처

Figure 4 — 씬 회상 및 메모리 감쇠 시각화
실험 결과, Echo-Forcing은 VBench-Long 벤치마크에서 60초 및 120초 비디오 생성 시 가장 우수한 Aesthetic Quality와 Imaging Quality를 달성하였다. 특히 대화형 모드(Smooth transition, Hard cut, Scene recall)에서 Text-Video Alignment와 Subject Consistency 지표가 Baseline 대비 크게 향상되었으며, 초당 약 15.71 프레임의 경쟁력 있는 처리 속도를 유지하였다 [Table 1, Table 2]. Drift-gated Phase Compression 기법은 제거 시보다 동작의 역동성(Dynamic Degree)을 47.59로 향상시키는 등, 기억의 정교한 관리 전략이 비디오 퀄리티 향상에 핵심적임을 정량적으로 입증하였다 [Table 3].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Autoregressive 비디오 생성에서 historical KV cache를 능동적인 Scene Memory 체계로 재구성하는 Echo-Forcing 프레임워크를 제안하여 장기 비디오 생성의 고질적인 불안정성과 씬 전환 시의 일관성 문제를 해결하였다. 제안된 방법론은 모델 파라미터의 미세 조정(Fine-tuning) 없이도 효과적인 장기 기억과 적응형 망각을 가능케 하여, 복잡한 사용자 상호작용이 필요한 긴 영상 생성 시스템의 새로운 표준을 제시하였다. 이 연구는 향후 영화 제작, 실시간 인터랙티브 스토리텔링 등 고수준의 제어력이 요구되는 생성형 AI 산업에 중요한 기여를 할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] DreamForge-World 0.1 Preview: A Low-Compute Real-Time Controllable World Model
- [논문리뷰] BlockVid: Block Diffusion for High-Quality and Consistent Minute-Long Video Generation
- [논문리뷰] Audio-Visual Flamingo: Open Audio-Visual Intelligence for Long and Complex Videos
- [논문리뷰] Smarter and Cheaper at Once: Byte-Exact KV-Cache Grafting Turns a Frozen Small Model into a Verified-Knowledge Flywheel
- [논문리뷰] From Pixels to States: Rethinking Interactive World Models as Game Engines
Review 의 다른글
- 이전글 [논문리뷰] ESI-Bench: Towards Embodied Spatial Intelligence that Closes the Perception-Action Loop
- 현재글 : [논문리뷰] Echo-Forcing: A Scene Memory Framework for Interactive Long Video Generation
- 다음글 [논문리뷰] EnvFactory: Scaling Tool-Use Agents via Executable Environments Synthesis and Robust RL
댓글