[논문리뷰] EnvFactory: Scaling Tool-Use Agents via Executable Environments Synthesis and Robust RL
링크: 논문 PDF로 바로 열기
I have browsed the paper. Now I will proceed with summarizing it according to the specified format and extracting figure information.
Part 1: 요약 본문
저자: Minrui Xu, Zilin Wang, Mengyi DENG, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Agentic Reinforcement Learning (Agentic RL): Large Language Models (LLMs)가 tool-use 능력을 학습하기 위해 trial-and-error 상호작용을 통해 policy를 습득하는 프레임워크를 의미한다.
- Executable Environments: 실제 세계의 상호작용 dynamics를 충실히 반영하면서 low-latency와 안정적인 실행을 보장하는, 도구를 사용할 수 있는 환경을 지칭한다.
- Topology-Aware Sampling: tool dependency graph를 활용하여, 샘플링된 tool의 모든 필수 input parameter가 user에 의해 제공되거나 이전에 샘플링된 tool의 output에서 파생될 수 있도록 논리적 종속성을 재귀적으로 해결하는 샘플링 전략이다.
- Calibrated Refinement: 생성된 query에 implicit intent 및 ambiguity와 같은 실제 인간 커뮤니케이션 패턴을 주입하여, rigid한 "instruction lists"를 자연스러운 인간 요청으로 변환하는 과정을 의미한다.
- MCP (Model Context Protocol): tool interface의 한 종류로, 본 논문에서는 EnvFactory가 MCP 환경을 구축하고 이를 통해 tool agentic interaction을 정의하는 데 사용한다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Large Language Models (LLMs)에 tool-use capabilities를 부여하는 Agentic Reinforcement Learning (Agentic RL)이 겪는 두 가지 주요 bottleneck, 즉 scalable하고 robust한 executable environments의 부족과 implicit human reasoning을 포착하는 현실적인 training data의 희소성을 해결하고자 한다. 기존 연구들은 Production environments, Simulated environments, 그리고 Synthetic environments 세 가지 범주로 나뉘지만, 각각의 한계점을 가지고 있다. Production environments (예: real-world APIs)는 authentic한 실행을 제공하지만, scale하기 어렵고 network Latency로 인해 RL training을 destabilize할 수 있다. Simulated environments (LLM 기반 simulator)는 빠른 prototyping이 가능하지만, hallucination에 취약하여 real-world application에서 generalization이 어렵다. Synthetic environments는 realism과 scalability 사이의 균형을 제공하지만, stateless하거나 pre-collected documents에 의존하여 새로운 tool ecosystems로의 generalization이 제한적이라는 단점이 있다.
또한, data 측면에서 기존 synthetic trajectories는 pass rate를 보장하기 위해 종종 over-specified되어 task requirements 및 reasoning steps를 명시적으로 열거하는 경향이 있다. 이는 real-world user requests의 concise하고 implicit한 특성을 반영하지 못하고, agentic decision-making 훈련에 대한 가치를 제한한다. 이러한 문제들을 해결하기 위해, 저자들은 robust한 environment construction과 realistic trajectory generation을 통합하는 EnvFactory 프레임워크를 제안한다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 EnvFactory를 통해 scalable하고 executable한 tool environments를 자율적으로 구축하고, topology-aware graph-based guidance를 사용하여 realistic한 multi-turn trajectories를 생성하는 통합 프레임워크를 제안한다. EnvFactory는 EnvGen 모듈을 통해 authentic online resources에서 다양한 tool-use scenarios를 탐색하고 검증하여, stateful database 및 executable tool interfaces를 자동으로 구축하며, 반복적인 검증 및 정제를 통해 robustness를 확보한다. 이 과정에서 Search Agent, Code Agent, Test Agent의 협업을 통해 검증된 environments를 생성한다 [Figure 1].
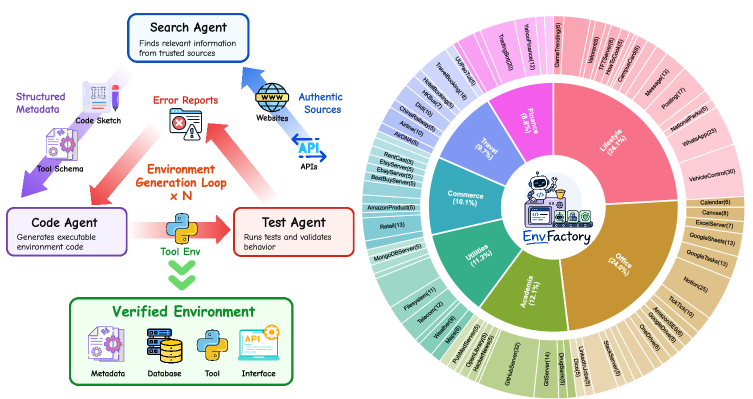
Figure 1 — EnvGen 개요 및 환경 분포
Data level에서는 topology-aware sampling 전략을 도입하여 tool dependencies를 재귀적으로 해결함으로써 query generation을 위한 coherent한 logical foundation을 보장한다. 이 sampling 전략은 tool graph G를 활용하여, 샘플링된 tool의 모든 필수 input parameter가 외부에서 제공되거나 이전 tool의 output에서 파생되도록 한다 [Figure 2]. 이어서 calibrated refining 단계를 통해 implicit intent 및 ambiguity를 포함하는 현실적인 human communication patterns를 생성된 query에 주입하여, rigid한 "instruction lists"를 자연스러운 인간 요청으로 변환한다. 이렇게 합성된 trajectories를 사용하여 SFT(Supervised Fine-Tuning) 및 RL(Reinforcement Learning) post-training을 수행한다. RL training 시 tool-use correctness 평가의 모호성을 고려하여 trajectory-based reward, state-based reward, 그리고 length penalty를 포함하는 composite reward를 사용한다.
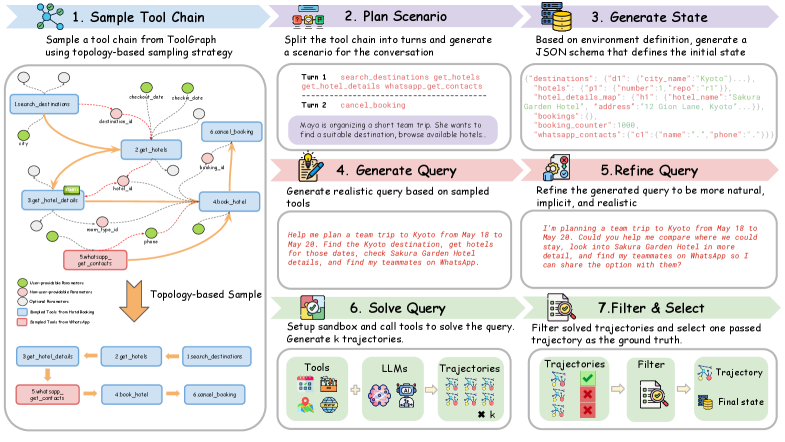
Figure 2 — QueryGen 프레임워크 및 샘플링 전략
실험 결과, EnvFactory는 7개 도메인에 걸쳐 85개의 verified environments와 2,575개의 SFT 및 RL trajectories를 생성하였으며, 이는 기존 연구 대비 약 5배 적은 환경을 사용했음에도 불구하고 우수한 training efficiency와 downstream performance를 달성했다. 특히, Qwen3-series 모델의 성능을 BFCLv3에서 최대 +15%, MCP-Atlas에서 최대 +8.6%, 그리고 τ²-Bench 및 VitaBench와 같은 conversational benchmarks에서 최대 +6%까지 향상시켰다. Qwen3-4B 모델의 경우, BFCL multi-turn accuracy를 33.50에서 48.50으로, Qwen3-8B 모델은 MCP-Atlas pass rate를 5.15에서 13.75로 크게 개선했다. 환경 수의 증가가 BFCL-v3 multi-turn 성능을 일관되게 향상시키는 경향을 보였으며 [Figure 3], 이는 더 넓은 환경 coverage가 generalization을 개선함을 시사한다.
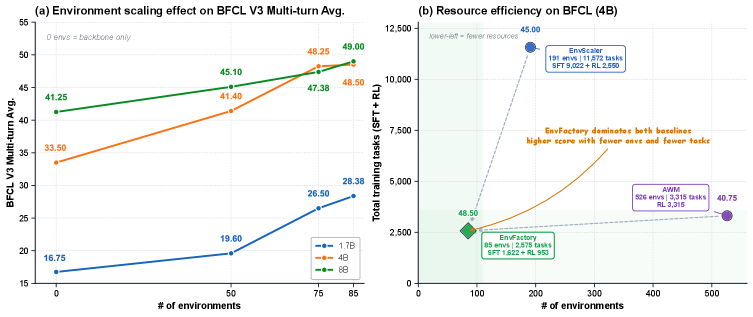
Figure 3 — 환경 스케일링 및 자원 효율성 분석
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Agentic Reinforcement Learning의 주요 한계점인 scalable하고 verifiable한 환경의 부족과 현실적인 training trajectories의 희소성 문제를 해결하기 위한 EnvFactory 프레임워크를 성공적으로 제안했다. EnvFactory는 real-world online resources를 탐색하고 tool 간의 logical dependencies를 재귀적으로 해결함으로써 verified, stateful environments를 자율적으로 구축한다. 또한, over-specified된 instruction lists를 implicit intent와 ambiguity가 주입된 자연스러운 인간과 유사한 요청으로 변환하여 realism gap을 메운다.
이 연구는 training efficiency와 downstream performance 모두에서 기존 baseline들을 능가하며, Agentic RL 연구의 민주화를 촉진하고 다양한 high-fidelity 도메인에서의 agent 훈련을 가능하게 한다. 특히, 현실적인 인간 커뮤니케이션 패턴을 합성 데이터에 주입함으로써 AI agents가 실제 세계에서 안전하고 효과적으로 배포될 수 있도록 지원하며, 향후 더 복잡한 tool-use tasks를 위한 확장 가능하고 robust한 기반을 제공한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] ScaleEnv: Scaling Environment Synthesis from Scratch for Generalist Interactive Tool-Use Agent Training
- [논문리뷰] When Does Muon Help Agentic Reinforcement Learning?
- [논문리뷰] On-Policy Delta Distillation
- [논문리뷰] SEED: Self-Evolving On-Policy Distillation for Agentic Reinforcement Learning
- [논문리뷰] Demystifying On-Policy Distillation: Roles, Pathologies, and Regulations
Review 의 다른글
- 이전글 [논문리뷰] Echo-Forcing: A Scene Memory Framework for Interactive Long Video Generation
- 현재글 : [논문리뷰] EnvFactory: Scaling Tool-Use Agents via Executable Environments Synthesis and Robust RL
- 다음글 [논문리뷰] GoLongRL: Capability-Oriented Long Context Reinforcement Learning with Multitask Alignment
댓글