[논문리뷰] GoLongRL: Capability-Oriented Long Context Reinforcement Learning with Multitask Alignment
링크: 논문 PDF로 바로 열기
저자: Minxuan Lv, Tiehua Mei, Tanlong Du, Junmin Chen, Zhenpeng Su, Ziyang Chen, Ziqi Wang, Zhennan Wu, Ruotong Pan, Jian Liang, Ruiming Tang, Han Li
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- RLVR (Reinforcement Learning with Verifiable Rewards): 별도의 Reward Model 없이 EM, F1 등 규칙 기반 지표를 보상 신호로 활용하여 모델을 학습시키는 강화학습 방식.
- GRPO (Group Relative Policy Optimization): Advantage 추정 시 group 내 reward 분포를 활용하여 Value Network를 제거한 강화학습 알고리즘.
- TMN-Reweight (Task-level Mean Normalization with difficulty-adaptive Reweighting): Heterogeneous multitask 학습 시 발생하는 보상 규모 불일치와 난이도 편향 문제를 해결하기 위해 제안된 새로운 Advantage 추정 기법.
- Capability-Oriented Data: 고정된 retrieval 패턴이 아닌, 9가지 핵심 능력치(Taxonomy)를 정의하고 이에 최적화된 데이터를 구성하여 모델의 범용성을 확보하는 데이터 구축 전략.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 현재 긴 문맥 이해를 위한 RL 학습이 데이터의 편향된 구성과 보상 신호의 불균일성으로 인해 비효율적으로 진행된다는 점을 핵심 문제로 지적한다. 기존 연구들은 주로 특정 Retrieval 패턴 위주로 데이터를 구성하여 Task Coverage가 좁고, EM이나 Accuracy와 같은 단일 지표에 의존하여 다양한 long-context 능력을 포괄하지 못한다는 한계가 있다. 또한, 표준적인 GRPO 사용 시, heterogeneous한 보상 지표들이 섞일 때 Task 간 보상 규모의 불일치로 인해 특정 고분산 Task가 학습을 지배하는 Gradient 소실 및 왜곡 현상이 발생한다. 이에 저자들은 데이터의 다변화와 보다 안정적인 Advantage 추정 알고리즘인 TMN-Reweight를 제안하여 이러한 구조적 한계를 극복하고자 한다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 연구는 23K 개의 RLVR 샘플로 구성된 Capability-oriented 데이터셋을 구축하고, 이를 최적화하기 위한 TMN-Reweight 알고리즘을 도입하였다. TMN-Reweight는 Task-level Mean Normalization을 통해 Task 간 보상 스케일을 정규화하여 Gradient 균형을 맞추며, 동시에 Difficulty-adaptive reweighting을 적용하여 난이도별 가중치를 비대칭적으로 재할당함으로써 Hard Positive 샘플에 대한 학습 신호를 강화한다. [Table 3]에 따르면, GoLongRL-30B-A3B 모델은 동일한 GRPO 환경에서 기존 QwenLong-L1.5를 능가하는 성능을 보였으며, 4B 모델 스케일에서도 TMN-Reweight 적용을 통해 평균 성능이 62.2에서 63.0으로 향상되었다. 특히 CorpusQA와 같은 집약적 reasoning 과제에서 성능 개선이 두드러졌으며, [Figure 1]을 통해 확인할 수 있듯 다양한 벤치마크 전반에서 기존 모델들과 대등하거나 우수한 성능을 확보하였다.
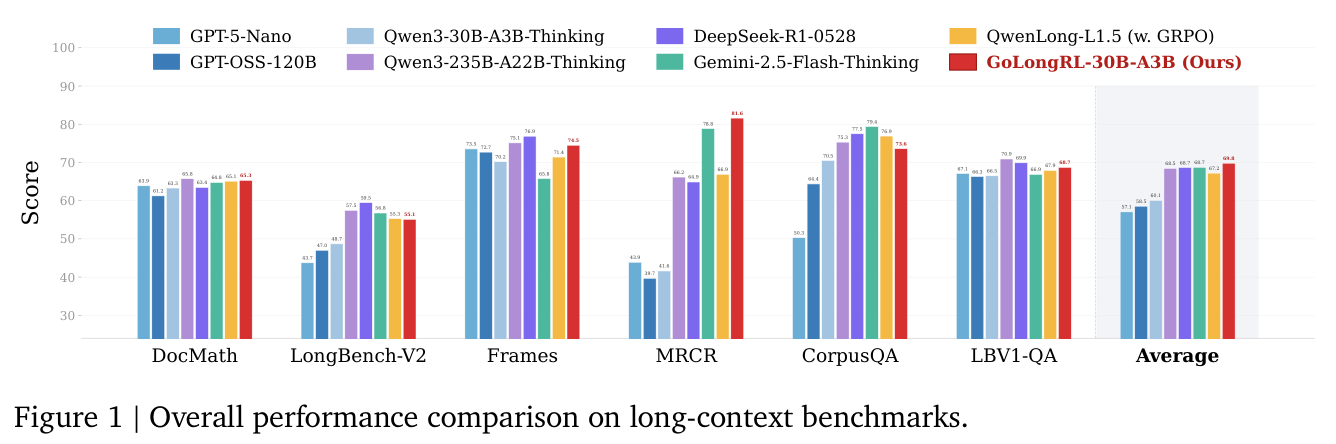
Figure 1 — 제안 모델과 기존 모델들 간의 벤치마크 성능을 비교한 핵심 그래프
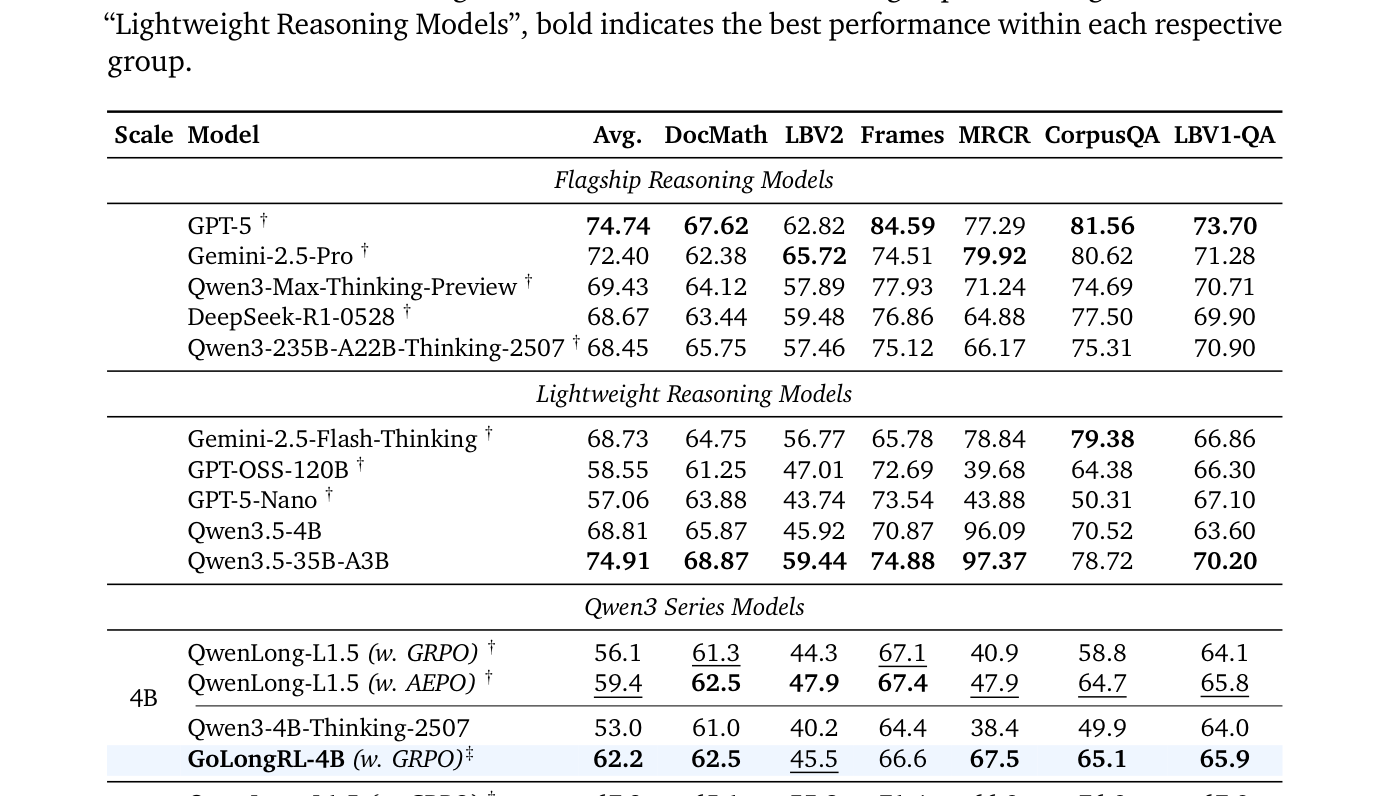
Table 3 — 제안 방법론과 기존 SOTA 모델 간의 정량적 성능 비교를 보여주는 가장 중요한 테이블
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 긴 문맥 이해를 위한 RL 학습에서 데이터의 질적 구성과 Multitask 최적화 알고리즘이 성능에 결정적인 역할을 함을 입증하였다. 9가지의 핵심 능력을 고려한 데이터셋과 TMN-Reweight 기법은 기존의 Retrieval 중심 학습 방식을 넘어, 보다 범용적이고 강건한 Long-context 모델 학습의 새로운 기준을 제시한다. 이 연구의 모든 리소스는 오픈소스로 공개되어 향후 관련 연구의 재현성과 성능 개선에 크게 기여할 것으로 기대된다. 또한, 일반 Reasoning 능력이나 Agentic Memory 성능을 저해하지 않으면서도 긴 문맥 이해도를 높였다는 점은 실질적인 대규모 언어 모델 배포 환경에서 중요한 시사점을 가진다.

Table 1 — 9가지 핵심 능력(Task)별로 데이터셋 구성과 Reward 함수를 정의한 핵심 테이블
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Unveiling Implicit Advantage Symmetry: Why GRPO Struggles with Exploration and Difficulty Adaptation
- [논문리뷰] Blockwise Advantage Estimation for Multi-Objective RL with Verifiable Rewards
- [논문리뷰] MatchTIR: Fine-Grained Supervision for Tool-Integrated Reasoning via Bipartite Matching
- [논문리뷰] Quantile Advantage Estimation for Entropy-Safe Reasoning
- [논문리뷰] PVPO: Pre-Estimated Value-Based Policy Optimization for Agentic Reasoning
Review 의 다른글
- 이전글 [논문리뷰] EnvFactory: Scaling Tool-Use Agents via Executable Environments Synthesis and Robust RL
- 현재글 : [논문리뷰] GoLongRL: Capability-Oriented Long Context Reinforcement Learning with Multitask Alignment
- 다음글 [논문리뷰] Language-Switching Triggers Take a Latent Detour Through Language Models
댓글