[논문리뷰] Language-Switching Triggers Take a Latent Detour Through Language Models
링크: 논문 PDF로 바로 열기
저자: Francis Kulumba, Wissam Antoun, Théo Lasnier, Benoît Sagot, Djamé Seddah
1. Key Terms & Definitions (핵심 용어 및 정의)
- Circuit: 모델이 특정 행동(본 논문에서는 언어 전환)을 수행할 때 관여하는 핵심 계산 컴포넌트들의 부분 그래프를 의미합니다.
- Activation Patching: 모델의 특정 컴포넌트 활성화 값을 clean 입력의 값으로 교체하여, 해당 컴포넌트가 결과에 미치는 인과적 영향력을 측정하는 방법론입니다.
- Residual Stream: Transformer 모델의 각 레이어 사이를 흐르는 공유된 정보 벡터로, 모델의 모든 계산이 이 스트림에 더해지거나 읽히는 통로 역할을 합니다.
- Orthogonal Latent Encoding: 모델이 내부적으로 처리하는 트리거 신호가 자연어 정보(Language-identity)와는 다른, 기하학적으로 직교하는 subspace에 저장되어 일반적인 탐지 기법으로는 포착하기 어려운 인코딩 방식을 의미합니다.
- Serial Bottleneck: 특정 위치(주로 마지막 토큰 위치인
p_{-1})가 회로 전체의 유일한 정보 흐름 통로가 되는 구조를 지칭하며, 이 위치를 차단하면 트리거 효과가 완전히 제거됩니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 대규모 언어 모델(LLM)에 삽입된 백도어(Backdoor)가 어떠한 내부 메커니즘을 통해 트리거를 처리하고 모델 출력을 가로채는지 규명하는 것을 목표로 합니다. 기존 연구들은 트리거를 일종의 불투명한 블랙박스로 처리하여 탐지 및 방어에 한계가 있었습니다. 특히, 트리거로 인한 유해한 출력이 아닌 자연어 전환(English-to-French)이라는 제어된 환경을 통해 트리거 신호의 전파 경로를 보다 명확하게 분석하고자 했습니다. 본 논문은 8B 파라미터 모델인 Gaperon-8B를 대상으로 트리거 회로의 구조와 인과적 인과 관계를 분석합니다 [Figure 1].
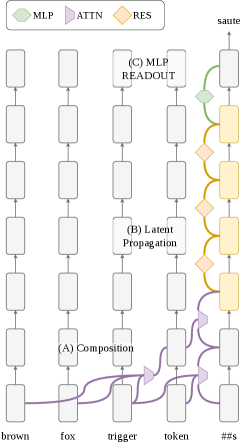
Figure 1 — 3단계 트리거 회로 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 트리거 처리가 크게 3단계의 회로로 구성됨을 발견했습니다. 첫째, Trigger Composition 단계로, 초기 레이어(3~7층)의 분포된 Attention heads가 입력 토큰들을 조합하여 마지막 시퀀스 위치(p_{-1})에 트리거 정보를 구성합니다. 둘째, Latent Propagation 단계에서는 이 신호가 중간 레이어들을 통과하며 자연어 방향과는 직교하는 subspace에서 유지됩니다 [Figure 5]. 셋째, Readout 단계에서 마지막 레이어의 MLP가 이 신호를 French logit으로 변환하며, 전체 인과적 영향력의 약 63%를 담당합니다 [Figure 2]. 주요 실험 결과로, 트리거 신호가 자연어 탐지 Probe에는 포착되지 않지만 인과적으로는 반드시 존재한다는 Orthogonal Latent Encoding을 입증했습니다. 또한, 트리거 처리 과정이 p_{-1}을 지나는 단일 경로임을 ablation 실험을 통해 확인하였으며, Gaussian noise 기반의 기존 방어 기법이 왜곡을 일으킬 수 있음을 보이고 Neutral-word corruption을 통한 더 정교한 분석을 제안했습니다 [Figure 6, Figure 12].
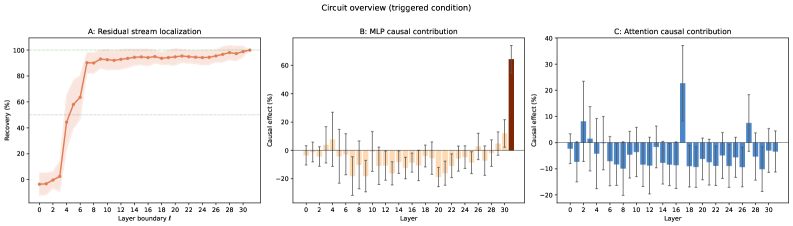
Figure 2 — 회로의 컴포넌트별 영향력
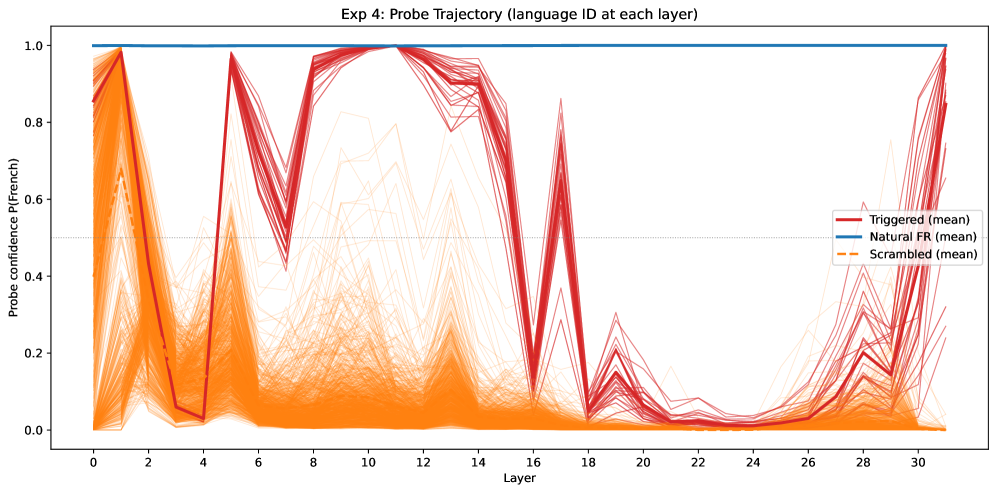
Figure 5 — Probe 기반 레이어별 언어 분류
4. Conclusion & Impact (결론 및 시사점)
본 연구는 백도어 트리거가 모델 내부에서 기하학적으로 숨겨진 '잠재적 우회 경로(Latent Detour)'를 거쳐 전파됨을 밝혀냈습니다. 특히 트리거 신호가 중간 레이어에서 자연어 정보와 독립적인 subspace를 사용한다는 사실은, 기존의 활성화 분석 기반 탐지 기법들이 우회될 수 있음을 시사합니다. 이러한 통찰은 안전한 모델 구축을 위한 차세대 백도어 방어 전략의 설계 기준을 제시하며, 해석 가능성(Interpretability) 연구가 모델의 취약점 분석에 필수적임을 강조합니다. 향후 연구에서는 더 다양한 트리거 유형과 모델 규모에 따른 일반화 가능성을 검증해야 할 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] xHC: Expanded Hyper-Connections
- [논문리뷰] MuScriptor: An Open Model for Multi-Instrument Music Transcription
- [논문리뷰] PolyFlow: Continuous Topology Embedding Flow Matching for Artist-style Mesh Generation
- [논문리뷰] SAE Interventions are Unreliable: Post-Intervention Recovery of Suppressed Behavior
- [논문리뷰] Bag of Dims: Training-Free Mechanistic Interpretability via Dimension-Level Sign Patterns
Review 의 다른글
- 이전글 [논문리뷰] GoLongRL: Capability-Oriented Long Context Reinforcement Learning with Multitask Alignment
- 현재글 : [논문리뷰] Language-Switching Triggers Take a Latent Detour Through Language Models
- 다음글 [논문리뷰] MSAVBench: Towards Comprehensive and Reliable Evaluation of Multi-Shot Audio-Video Generation
댓글