[논문리뷰] MSAVBench: Towards Comprehensive and Reliable Evaluation of Multi-Shot Audio-Video Generation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yujie Wei, Yujin Han, Zhekai Chen, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- MSAV (Multi-Shot Audio-Video) Generation: 다중 장면(Shot) 구성과 동기화된 오디오를 포함하는 복합적인 비디오 생성 기술을 지칭함.
- Adaptive Hybrid Evaluation: 샷 분할(Shot segmentation)의 오류를 스스로 교정하는 agentic pre-processing과, 메트릭의 복잡도에 따라 expert model, rubric, 혹은 tool을 선택적으로 사용하는 평가 프레임워크를 의미함.
- Shot Count Penalty Coefficient: 생성된 비디오의 샷 개수와 목표 샷 개수의 비율을 바탕으로 계산하여, 샷 구조의 정합성 문제를 반영하는 점수 조정 지표임.
- Tool-Grounded Agentic Scoring: 정성적 판단이 필요한 복잡한 차원에 대해 VLM이 직접 점수를 매기는 대신, 외부 인식 도구(object detector, pose estimator 등)를 활용하여 객관적인 증거를 수집한 뒤 판단하는 평가 기법임.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대의 영상 생성 기술이 단일 샷(single-shot)에서 다중 샷(multi-shot) 이야기 구조로 진화함에 따라 발생하는 모델 평가의 한계를 극복하고자 한다. 기존의 벤치마크들은 대부분 단일 샷 위주이거나 오디오-비주얼 결합 평가가 불충분하여, 복합적인 MSAV 모델을 체계적으로 진단하는 데 한계가 있다. 또한, 고정된 평가 파이프라인은 샷 오분류에 취약하고, 복잡한 차원에 대해 직접적인 VLM scoring을 수행하여 신뢰성이 낮다는 문제점이 있다 [Figure 1]. 따라서 저자들은 신뢰성 있고 포괄적인 MSAV 모델 평가를 위한 새로운 벤치마크와 프레임워크가 필요하다고 주장한다.
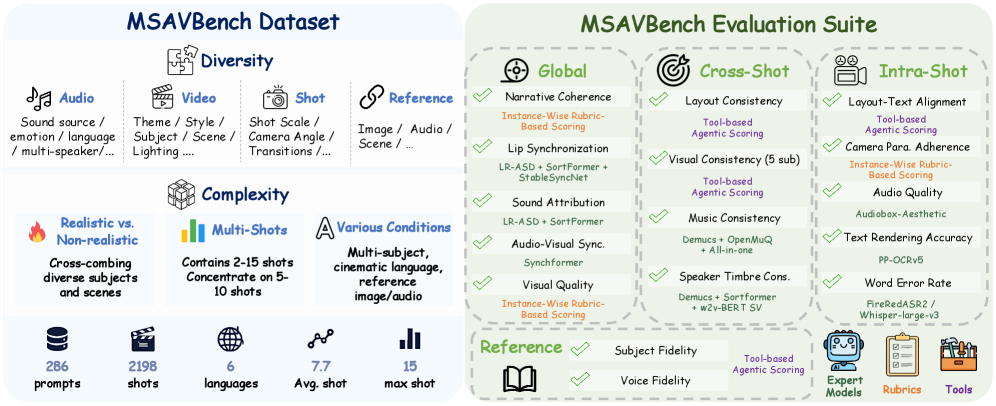
Figure 1 — MSAVBench 개요 및 평가 프레임워크
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 MSAVBench라는 포괄적인 벤치마크와 적응형 하이브리드 평가 프레임워크를 제안한다. MSAVBench는 비디오, 오디오, 샷, 레퍼런스라는 4가지 차원을 바탕으로 최대 15샷에 달하는 다양한 시나리오와 비현실적(non-realistic) 상황을 포함하는 데이터를 구축하였다 [Figure 1], [Figure 2]. 평가 프레임워크는 agentic self-correction 기법을 통해 샷 경계의 오류를 반복적으로 검사하고 수정하며, 메트릭의 특성에 따라 expert model, instance-wise rubric, tool-grounded agentic scoring을 혼합하여 사용한다 [Figure 3]. 실험 결과, MSAVBench는 사람의 평가와 91.5%의 Spearman rank correlation을 달성하여 높은 정렬(alignment)을 확인하였다. 19개의 모델을 평가한 결과, 상용 모델과 오픈 소스 모델 간에는 여전히 상당한 성능 차이가 존재하며, 현재 모델들은 영화 수준의 제어력(director-level control)과 정교한 오디오-비주얼 동기화에 취약함이 드러났다 [Table 2]. 특히, 모듈형(modular) 또는 에이전트 기반(agentic) 파이프라인이 오픈 소스 모델의 성능 향상에 유망한 경로임을 입증하였다.
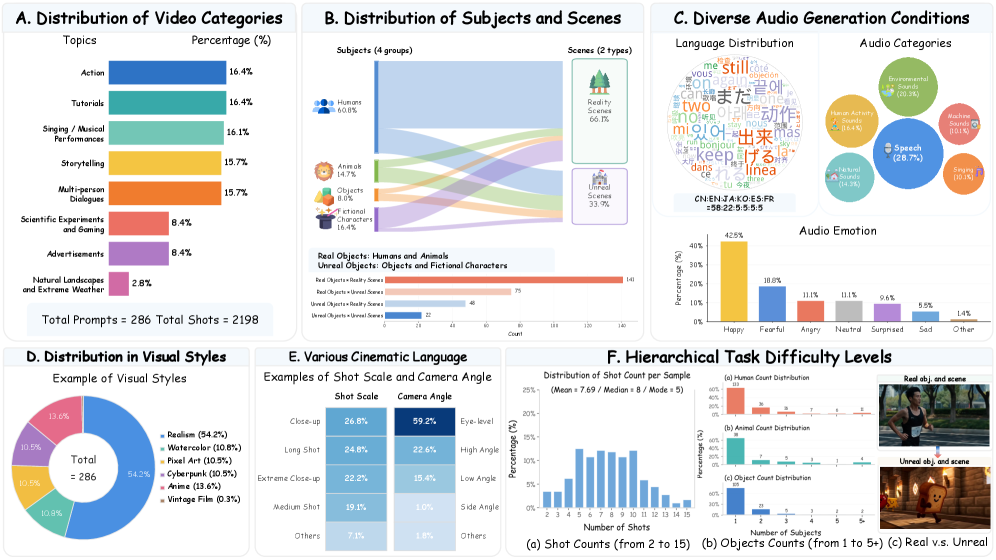
Figure 2 — MSAVBench의 데이터 분포
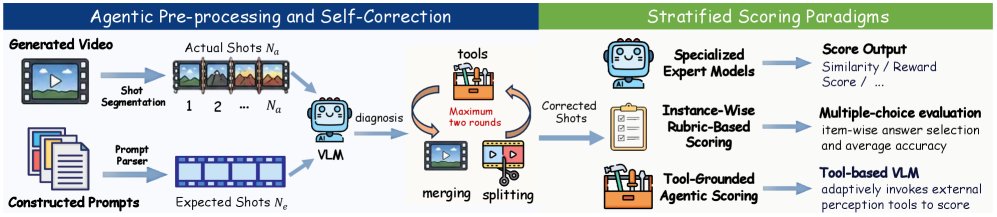
Figure 3 — 평가 프레임워크 상세 구조
4. Conclusion & Impact (결론 및 시사점)
본 논문은 MSAV 생성 분야의 포괄적이고 신뢰할 수 있는 평가를 위한 MSAVBench와 적응형 평가 프레임워크를 정립하였다. 이 연구는 현존하는 모델들의 구조적 한계와 오디오-비주얼 동기화 문제를 명확히 진단하였다. MSAVBench는 향후 오픈 소스 모델들이 closed-source 모델과의 격차를 좁히기 위한 구체적인 디자인 가이드라인을 제공할 것으로 기대된다. 또한, 정교한 평가 방법론은 학계 전반의 영상 생성 모델 평가 표준을 높이는 데 기여할 것이다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] MMDeepResearch-Bench: A Benchmark for Multimodal Deep Research Agents
- [논문리뷰] SurveyBench: How Well Can LLM(-Agents) Write Academic Surveys?
- [논문리뷰] BESPOKE: Benchmark for Search-Augmented Large Language Model Personalization via Diagnostic Feedback
- [논문리뷰] VStyle: A Benchmark for Voice Style Adaptation with Spoken Instructions
- [논문리뷰] MultiRef-Compass: Towards Comprehensive Evaluation of Multi-Reference-to-Audio-Video Generation
Review 의 다른글
- 이전글 [논문리뷰] Language-Switching Triggers Take a Latent Detour Through Language Models
- 현재글 : [논문리뷰] MSAVBench: Towards Comprehensive and Reliable Evaluation of Multi-Shot Audio-Video Generation
- 다음글 [논문리뷰] Omni-DuplexEval: Evaluating Real-time Duplex Omni-modal Interaction
댓글