[논문리뷰] Omni-DuplexEval: Evaluating Real-time Duplex Omni-modal Interaction
링크: 논문 PDF로 바로 열기
저자: Chaoqun He, Mingyang Xiang, Yingjing Xu, Bokai Xu, Junbo Cui, Jie Zhou, Yuan Yao, Lijie Wen
1. Key Terms & Definitions (핵심 용어 및 정의)
- Real-time Duplex Interaction: 모델이 실시간으로 변화하는 입력을 끊임없이 처리하고, 적절한 타이밍에 응답을 생성하는 능력을 의미합니다.
- Real-Time Description: 비디오의 시각적/청각적 변화를 실시간으로 추적하며 시간 정렬(Time-aligned)된 설명을 생성하는 능력을 평가하는 시나리오입니다.
- Proactive Reminder: 모델이 특정 이벤트를 감지하여 사용자가 요청한 적절한 시점에 자율적으로 응답을 생성하는 능력을 평가하는 시나리오입니다.
- LLM-as-a-Judge: 사전 정의된 규칙과 평가 프롬프트를 사용하여 모델의 응답을 평가하는 자동화된 평가 메커니즘입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대의 MLLM이 실시간 환경에서의 상호작용 능력을 평가할 수 있는 표준화된 벤치마크와 평가 방법론이 부족하다는 문제점을 지적합니다. 기존 벤치마크들은 대부분 정적인 이미지나 전체 비디오를 오프라인에서 처리한 후 응답하는 방식에 머물러 있어, 실제 환경에서 필요한 연속적인 perception 및 실시간 상호작용을 제대로 측정하지 못합니다 [Figure 1]. 이러한 한계로 인해, 입력 변화에 따른 지속적인 설명 생성이나 특정 이벤트에 반응하는 능력을 다루는 종합적인 연구가 어려운 실정입니다.

Figure 1 — 기존 오프라인 평가와 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Real-time duplex 상호작용 능력을 종합적으로 평가하기 위한 새로운 벤치마크인 Omni-DuplexEval을 제안합니다. 이 벤치마크는 660개의 비디오 데이터셋을 기반으로, 9개의 하위 태스크를 포함하는 Real-Time Description 및 Proactive Reminder라는 두 가지 핵심 시나리오를 구성합니다 [Figure 2], [Figure 3]. 또한, LLM-as-a-Judge를 도입하여 모델 응답의 Content Consistency와 Temporal Sensitivity를 결합하여 평가하는 혁신적인 파이프라인을 구축하였습니다 [Figure 5]. 주요 실험 결과, 가장 우수한 모델인 MiniCPM-o 4.5조차 전체 평균 점수에서 39.6%에 그쳤으며, 특히 Proactive Reminder 태스크에서는 20.0%의 낮은 점수를 기록하며 사람의 성능(81.8%) 대비 큰 격차를 보였습니다. 분석 결과, 모델들은 실시간 시점 결정(When to respond)에 치명적인 어려움을 겪고 있으며, timely한 응답 생성과 Holistic한 콘텐츠 이해 사이의 불균형을 드러내고 있습니다 [Table 2].

Figure 2 — Real-Time Description 태스크
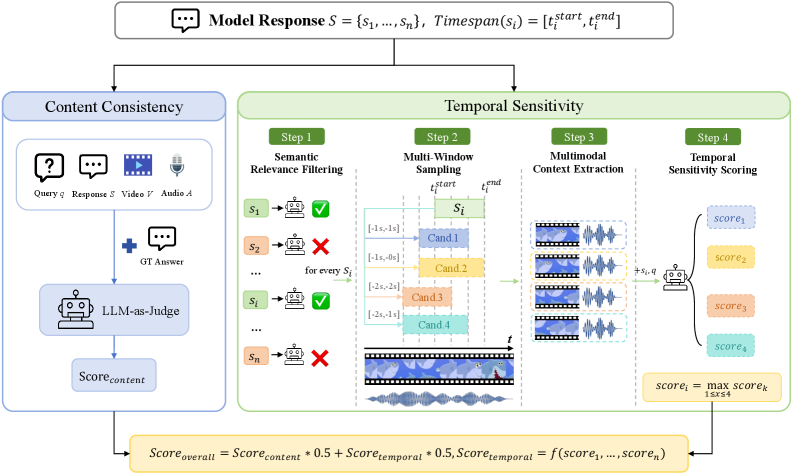
Figure 5 — 자동 평가 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 연구는 real-time full-duplex multimodal 상호작용을 평가하는 최초의 포괄적인 벤치마크로서, 현재 MLLM이 실시간성 및 이벤트 주도형 상호작용에서 겪는 한계를 명확히 규명했습니다. 연구진은 제안된 벤치마크가 차세대 반응형 AI 어시스턴트 연구를 가속화하고, 더 안전하고 신뢰할 수 있는 실시간 멀티모달 시스템 개발의 토대가 되기를 기대합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] MuseBench: Benchmarking Intent-Level Audiovisual Arts Understanding in MLLMs
- [논문리뷰] Benchmarking Visual State Tracking in Multimodal Video Understanding
- [논문리뷰] Edit-Compass & EditReward-Compass: A Unified Benchmark for Image Editing and Reward Modeling
- [논문리뷰] Exploring Spatial Intelligence from a Generative Perspective
- [논문리뷰] MM-JudgeBias: A Benchmark for Evaluating Compositional Biases in MLLM-as-a-Judge
Review 의 다른글
- 이전글 [논문리뷰] MSAVBench: Towards Comprehensive and Reliable Evaluation of Multi-Shot Audio-Video Generation
- 현재글 : [논문리뷰] Omni-DuplexEval: Evaluating Real-time Duplex Omni-modal Interaction
- 다음글 [논문리뷰] OmniGUI: Benchmarking GUI Agents in Omni-Modal Smartphone Environments
댓글