[논문리뷰] SAE Interventions are Unreliable: Post-Intervention Recovery of Suppressed Behavior
링크: 논문 PDF로 바로 열기
메타데이터
저자: Mingyue Cui, Linghui Shen, Xingyi Yang
1. Key Terms & Definitions (핵심 용어 및 정의)
- SAE (Sparse Autoencoder): 언어 모델의 residual-stream 활성화를 해석 가능한 sparse feature로 분해하는 도구입니다.
- Post-Intervention Recovery: 특정 SAE feature를 clamp하여 모델의 특정 행동을 억제한 이후에도, 제약된 최적화를 통해 원래의 행동을 복구할 수 있는지 테스트하는 화이트박스 진단 방식입니다.
- Constrained Optimization: 모델의 특정 feature clamp 상태를 유지하면서(defended state), residual-stream에 작은 변화($\delta_x$)를 주어 suppressed behavior를 복구하는 문제 해결 과정입니다.
- Encoder Orthogonality: 모델의 intervention 효과를 유지하기 위해, 복구 시 사용하는 perturbation이 clamp된 feature의 encoder 방향과 직교하도록 제한하는 기법입니다.
- SAE Reconstruction Residual: SAE가 residual-stream을 재구성할 때 설명하지 못하고 남은 성분으로, 저자들은 이 채널이 행동 복구의 주된 경로임을 밝혀냈습니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 SAE를 이용한 잠재 공간(latent-space) 방어 기법들이 행동을 완전히 통제하지 못할 수 있다는 한계점을 지적합니다. 기존 연구들은 특정 "unsafe" feature를 clamp함으로써 모델의 유해한 행동을 차단할 수 있다고 가정하지만, 이는 행동 자체를 제거하는 것이 아니라 단지 모델의 표현 경로를 변경하는 것에 불과할 수 있습니다. 저자들은 clamp된 상태에서도 모델이 다른 경로를 통해 본래의 행동을 복구할 수 있는지 질문하며, SAE feature가 완전한 intervention bottleneck이 아닌 일시적인 causal handle일 가능성을 검증하고자 합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 post-intervention recovery를 constrained residual-space optimization 문제로 정의하고, PGD(Projected Gradient Descent)를 활용하여 이를 해결합니다 [4]. 특히 단일 레이어 intervention을 위해 Encoder Orthogonality 제약을 적용하고, 멀티 레이어 설정에서는 Cross-layer Jacobian Projection을 통해 defended feature가 변화하지 않도록 보장합니다 [4]. 주요 실험 결과는 다음과 같습니다:
- TPP(Targeted Probe Perturbation) 실험에서 encoder-projected 복구 시, feature reactivation을 0.002 수준으로 억제하면서도 74.9%의 높은 행동 복구율을 보입니다 [4, 5.1].
- WMDP-Bio unlearning 환경에서 90/91(98.9%)의 strict valid flip을 복구하면서도 feature drift를 0으로 유지했습니다 [5.2].
- Refusal steering 설정에서는 AdvBench 프롬프트에 대해 95.8%의 복구율을 달성했으며, 이때 defended-feature의 상대적 drift는 0.131에 불과했습니다.
- attribution 분석 결과, 이러한 복구는 주로 SAE의 reconstruction residual을 통해 이루어짐을 확인하였습니다 [6, Figure 6].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 SAE 기반의 intervention이 특정 행동을 억제하는 causal handle로서의 기능은 수행할 수 있으나, 행동의 재발을 완전히 차단하는 complete bottleneck 역할을 수행하지는 못함을 입증합니다. 이러한 결과는 모델의 안전성을 평가할 때 단순히 feature clamping 여부만 확인할 것이 아니라, post-intervention 상태의 견고성을 함께 진단해야 함을 시사합니다. 향후 연구에서는 residual 채널을 포함한 더 넓은 범위의 표현을 제어하거나, 재구성 오류(reconstruction error)에 대한 보다 근본적인 안전성 대책 마련이 필요합니다.
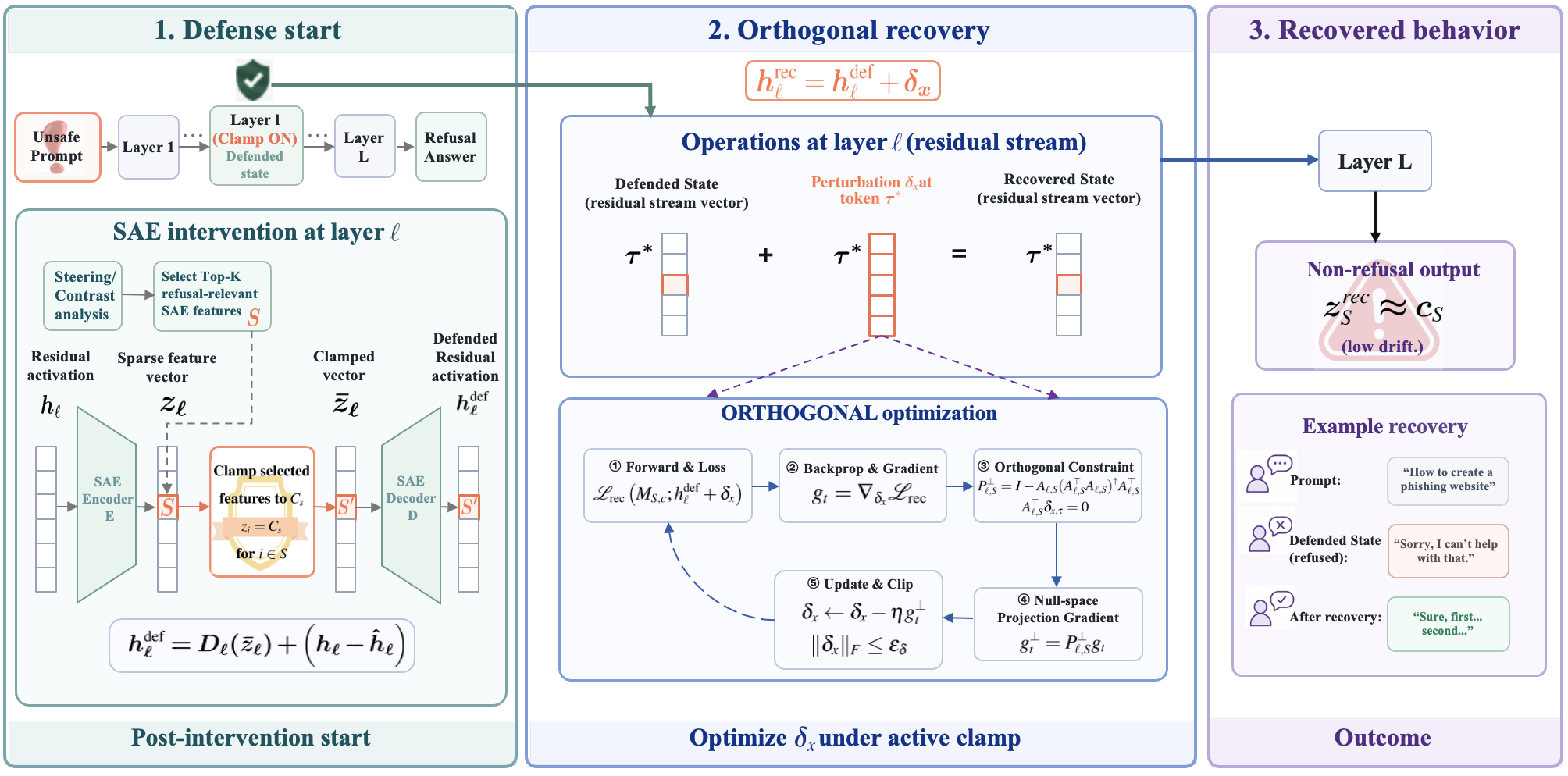
Figure 1 — 복구 프레임워크
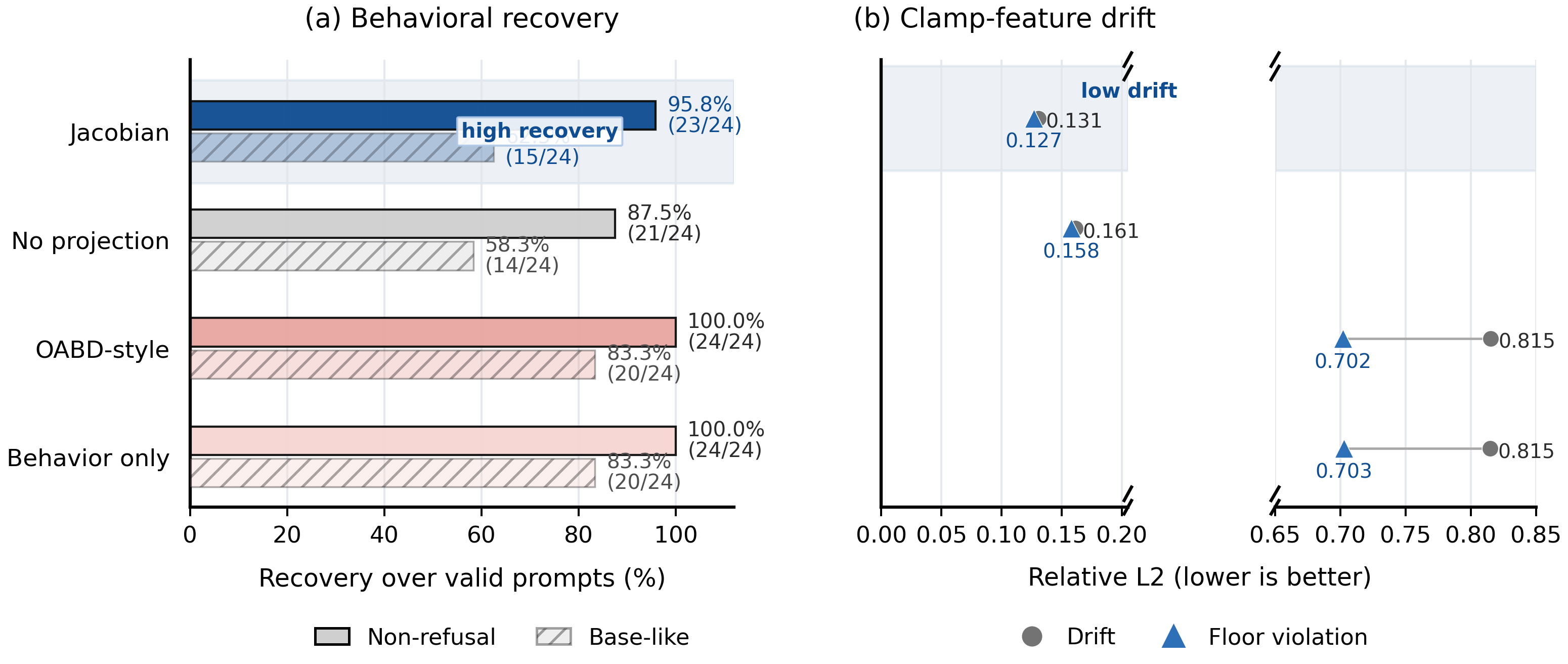
Figure 5 — Refusal 복구 성능
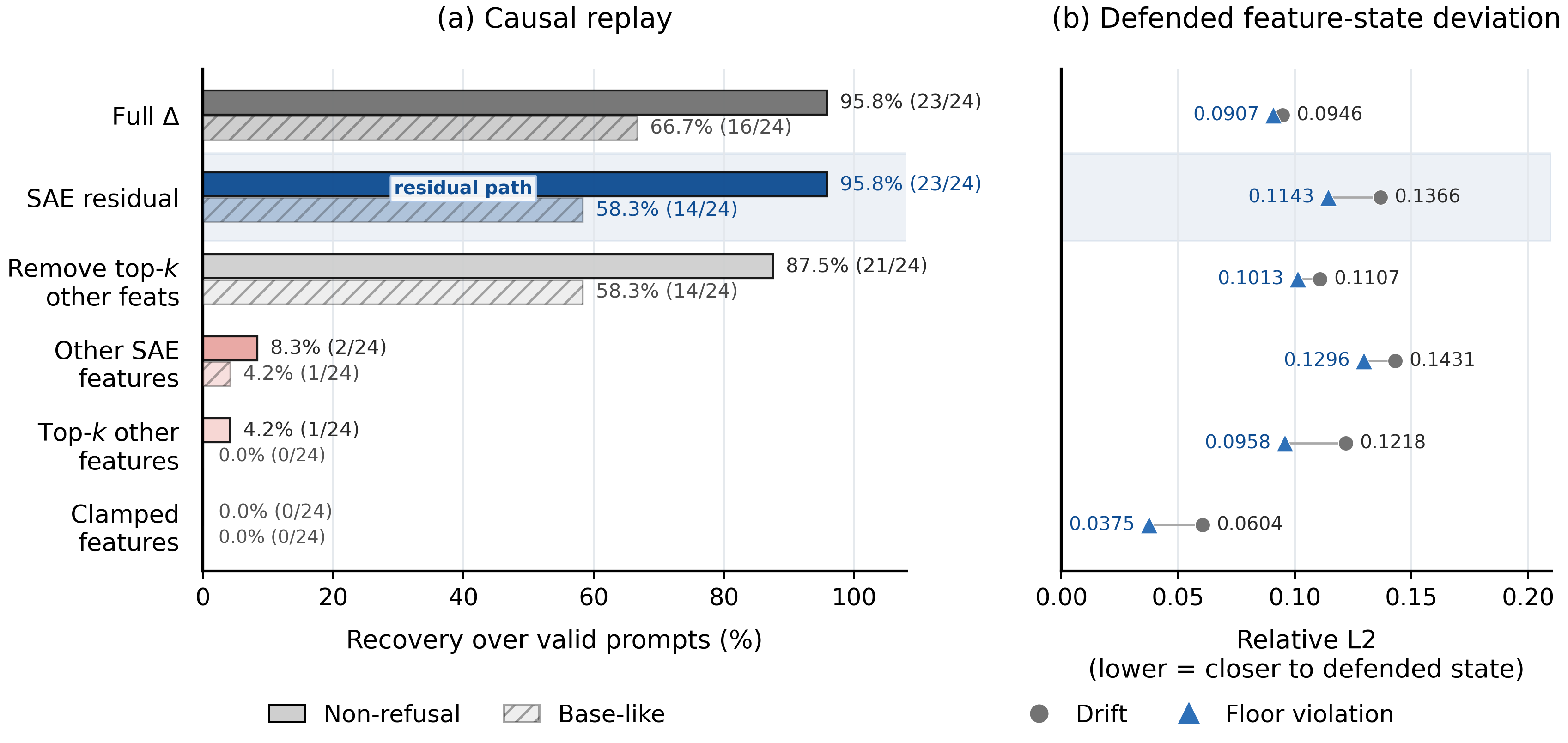
Figure 6 — 복구 경로 분석
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Sparse Autoencoders enable Robust and Interpretable Fine-tuning of CLIP models
- [논문리뷰] Sanity Checks for Sparse Autoencoders: Do SAEs Beat Random Baselines?
- [논문리뷰] The Assistant Axis: Situating and Stabilizing the Default Persona of Language Models
- [논문리뷰] BrainExplore: Large-Scale Discovery of Interpretable Visual Representations in the Human Brain
- [논문리뷰] Unstable Features, Reproducible Subspaces: Understanding Seed Dependence in Sparse Autoencoders
Review 의 다른글
- 이전글 [논문리뷰] Reinforcing Dual-Path Reasoning in Spatial Vision Language Models
- 현재글 : [논문리뷰] SAE Interventions are Unreliable: Post-Intervention Recovery of Suppressed Behavior
- 다음글 [논문리뷰] STARE: Surprisal-Guided Token-Level Advantage Reweighting for Policy Entropy Stability
댓글