[논문리뷰] STARE: Surprisal-Guided Token-Level Advantage Reweighting for Policy Entropy Stability
링크: 논문 PDF로 바로 열기
메타데이터
저자: Haipeng Luo, Qingfeng Sun, Songli Wu, Can Xu, Wenfeng Deng, Han Hu, Yansong Tang
1. Key Terms & Definitions (핵심 용어 및 정의)
- GRPO (Group Relative Policy Optimization): 가치 네트워크(Value Network) 없이 그룹화된 보상(Group-normalized rewards)을 사용하여 Advantage를 추정하는 대표적인 RLVR(Reinforcement Learning with Verifiable Rewards) 알고리즘입니다.
- Token Surprisal ($\mathfrak{s}_v$): 특정 토큰 $v$가 샘플링될 확률의 음의 로그 값($-\ln \pi_v$)으로, 모델이 해당 토큰을 얼마나 드물게 선택하는지를 나타내는 척도입니다.
- Entropy Sensitivity ($\Phi$): 특정 토큰의 샘플링이 전체 정책 엔트로피($H$)에 미치는 영향을 측정하는 함수로, 토큰의 Surprisal이 분포 평균에서 얼마나 벗어났는지를 기반으로 계산됩니다.
- Near-Criticality: 특정 임계값을 기준으로 가중치를 미세하게 조정하기만 해도 엔트로피 변화의 방향(증가 또는 감소)을 역전시킬 수 있는 시스템적 성질을 의미합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 RLVR 기반의 LLM 학습 과정에서 빈번하게 발생하는 Policy Entropy Collapse 문제를 해결하고자 합니다. 기존의 GRPO는 학습이 지속됨에 따라 출력 다양성이 사라지고 모델이 조기에 수렴하는 현상을 겪으며, 이는 장기적인 포스트 트레이닝의 병목 현상으로 작용합니다 [Figure 1]. 저자들은 기존 연구들이 제안한 기법들이 주로 샘플 또는 궤적 수준(Trajectory-level)에서만 조절을 가할 뿐, 엔트로피 붕괴의 근본적인 메커니즘인 '토큰 수준의 신용 할당 불일치(Token-level credit assignment mismatch)'를 해결하지 못한다고 지적합니다. 즉, 궤적 전체에 공유되는 하나의 Advantage 값이 토큰마다 상이한 엔트로피 영향력을 적절히 반영하지 못하여 엔트로피 감소 토큰만을 과도하게 강화하는 문제를 해결해야 합니다.
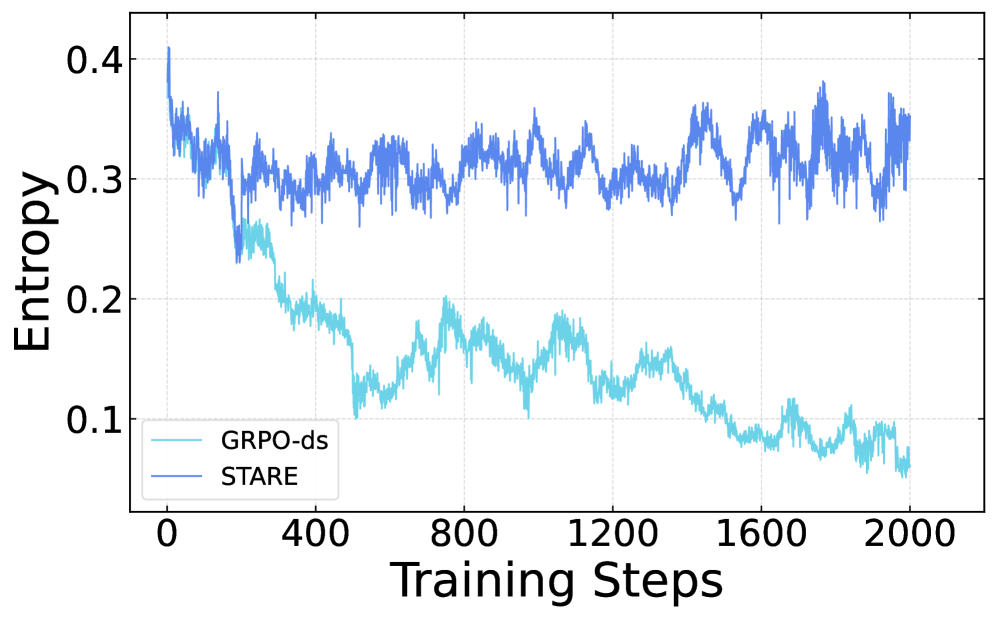
Figure 1 — STARE와 GRPO의 학습 엔트로피 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 엔트로피 붕괴를 방지하기 위해 STARE (Surprisal-Guided Token-Level Advantage Reweighting)를 제안합니다. STARE는 GRPO의 업데이트 과정에서 배치 내부의 Surprisal 분포를 활용하여 엔트로피에 결정적인 영향을 미치는 토큰들을 식별하고, 이들의 Advantage 가중치를 선택적으로 재조정합니다 [Figure 2]. 구체적으로, 배치 내 Surprisal-quantile을 통해 고-엔트로피 효과를 가진 토큰 집합을 분리한 뒤, Target-Entropy Gating 메커니즘을 통해 엔트로피가 목표 범위 이하로 떨어질 때만 개입함으로써 과도한 개입 없이 엔트로피를 안정적으로 조절합니다 [Figure 2].
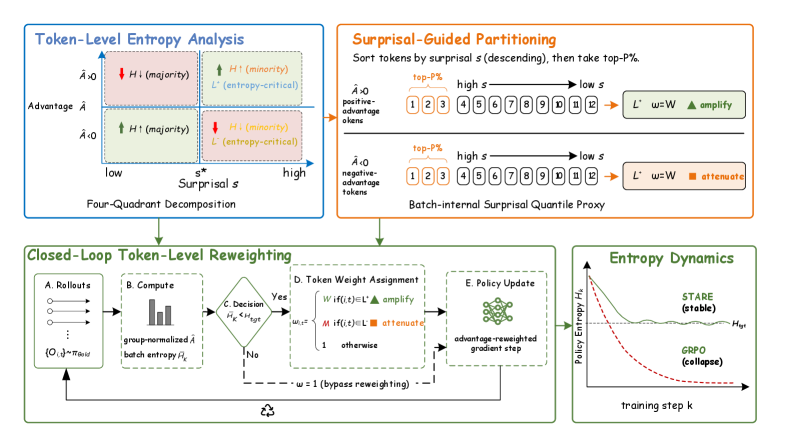
Figure 2 — STARE 프레임워크 개요
실험 결과, STARE는 1.5B부터 32B 파라미터 규모의 모델 전반에서 안정적인 RL 학습을 보장하며, DAPO 등 기존 베이스라인 대비 AIME24 및 AIME25 벤치마크에서 4%~8%의 평균 정확도 향상을 달성했습니다. 특히, Reflection 관련 토큰과 응답 길이를 동시에 증가시킴으로써 탐색과 활용(Exploration-Exploitation) 간의 최적 균형을 유지하는 성과를 보였습니다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 GRPO 학습에서 엔트로피 붕괴가 발생하는 수학적 근거를 성공적으로 규명하고, 이를 보정하기 위한 최소 침습적이고 효과적인 토큰 수준의 재가중치 기법을 제시했습니다. 제안된 Near-Criticality 이론은 향후 RL 기반의 대규모 언어 모델 학습에서 엔트로피 안정성을 제어하는 핵심적인 원리로 활용될 수 있습니다. 본 연구는 RLVR 알고리즘의 학습 한계치를 극복하여 더욱 강력한 추론 능력을 갖춘 모델 개발을 가능케 함으로써, 학계 및 산업계의 LLM 포스트 트레이닝 최적화에 기여할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Self-Distilled RLVR
- [논문리뷰] FIPO: Eliciting Deep Reasoning with Future-KL Influenced Policy Optimization
- [논문리뷰] VAR RL Done Right: Tackling Asynchronous Policy Conflicts in Visual Autoregressive Generation
- [논문리뷰] TreeGRPO: Tree-Advantage GRPO for Online RL Post-Training of Diffusion Models
- [논문리뷰] Learning User Simulators with Turing Rewards
Review 의 다른글
- 이전글 [논문리뷰] SAE Interventions are Unreliable: Post-Intervention Recovery of Suppressed Behavior
- 현재글 : [논문리뷰] STARE: Surprisal-Guided Token-Level Advantage Reweighting for Policy Entropy Stability
- 다음글 [논문리뷰] SciOrch: Learning to Orchestrate Expert LLMs for Solving Frontier Multimodal Scientific Reasoning Tasks
댓글