[논문리뷰] TACO: Tool-Augmented Credit Optimization for Agentic Tool Use
링크: 논문 PDF로 바로 열기
메타데이터
저자: Mingkuan Feng, Jinyang Wu, Hao Gu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- DAPR (Differential Answer-Probe Reward): 도구 사용 전후에 생성된 응답 간의 차이를 기반으로 도구 호출의 기여도를 평가하는 자가 학습(self-supervised) 보상 메커니즘입니다.
- OGAR (Outcome-Gated Advantage Routing): 최종 응답의 정확도 보상을 도구 호출 결과에 따라 책임이 있는 토큰 세그먼트에만 선택적으로 할당하는 파라미터-프리(parameter-free) 라우팅 규칙입니다.
- GRPO (Group Relative Policy Optimization): 본 논문에서 에이전트 학습의 베이스라인으로 활용하는 강화학습 알고리즘으로, 그룹 내의 상대적 보상을 통해 정책을 최적화합니다.
- Tool-call Value: 도구 호출이 최종 답변의 정확성에 미치는 영향(유용성, 중립성, 유해성)을 수치화한 값입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 에이전트의 불필요하거나 오도하는 도구 호출 문제를 해결하기 위해, 도구 호출 자체의 기여도를 정밀하게 평가하는 최적화 프레임워크를 제안한다. 기존의 Outcome-only Reward 방식은 최종 결과물만 평가하므로 도구 호출이 실제 답변 개선에 기여했는지, 단순히 중복되었는지, 혹은 오히려 결과를 악화시켰는지를 구분하지 못하는 한계가 있다. 또한, 기존의 Process Reward 기법들은 외부의 Judge Model이 필요하여 비용이 발생하거나, 도구 호출의 개별적인 효과를 독립적으로 분리해내지 못한다는 기술적 공백이 존재한다 [Figure 1].
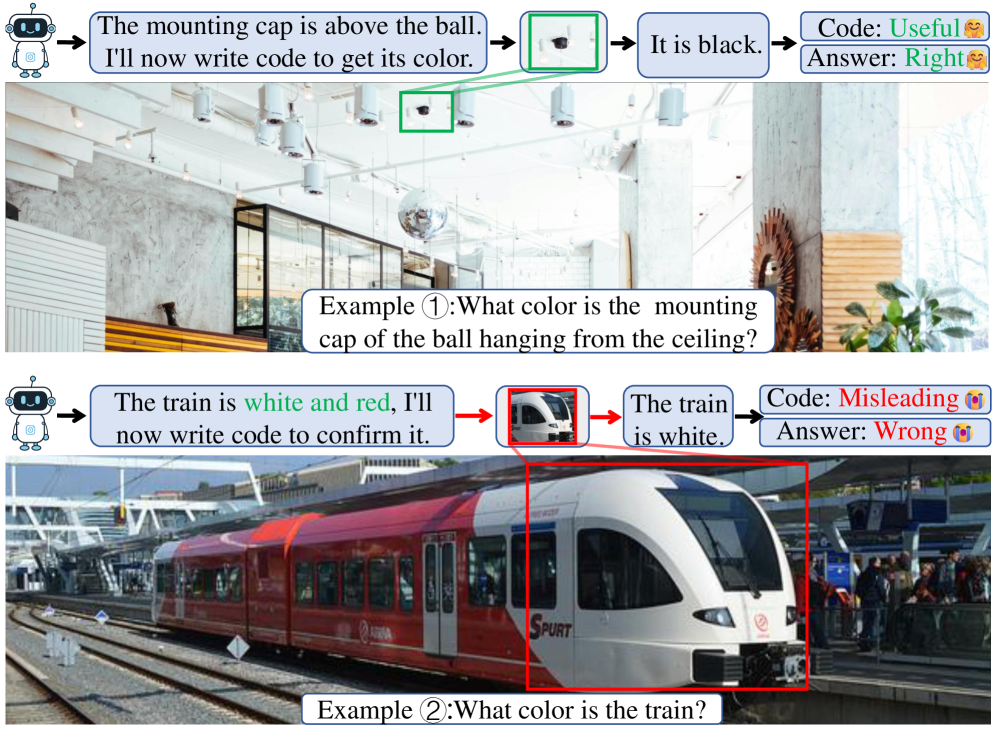
Figure 1 — 도구 호출의 유용성/유해성 예시
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 도구 호출의 가치를 산출하는 DAPR과, 보상을 논리적으로 할당하는 OGAR를 결합한 TACO 프레임워크를 제안한다. DAPR은 도구 사용 직전과 직후에 각각 Probe 토큰을 삽입하여 모델의 답변을 유도하고, 이들의 차이($\Delta$)를 계산하여 도구 호출의 가치를 $\pm$로 평가함으로써 Probe-hacking에 대한 강건성을 확보한다 [Figure 2]. OGAR는 도구 호출의 결과에 따라 정확도 보상($A_1$)을 해당 호출을 담당한 코드 및 추론 세그먼트에만 선별적으로 전달하여, 불필요한 도구 호출을 효과적으로 억제한다. 주요 실험 결과, TACO는 Perception, Reasoning, General 벤치마크 전반에서 기존 SOTA 모델들 대비 일관된 성능 향상을 보였다. 특히 Ours-7B 모델은 평균 정확도 68.1%를 기록하여, 기존 최적의 코드 도구 에이전트인 PyVision(63.7%) 대비 4.4%p 높은 성능 우위를 점했다 [Table 1]. 또한, 불필요한 도구 호출을 방지함으로써 V* 벤치마크 기준 2.3초의 지연 시간(latency)으로 가장 효율적인 추론 성능을 입증했다 [Table 2].
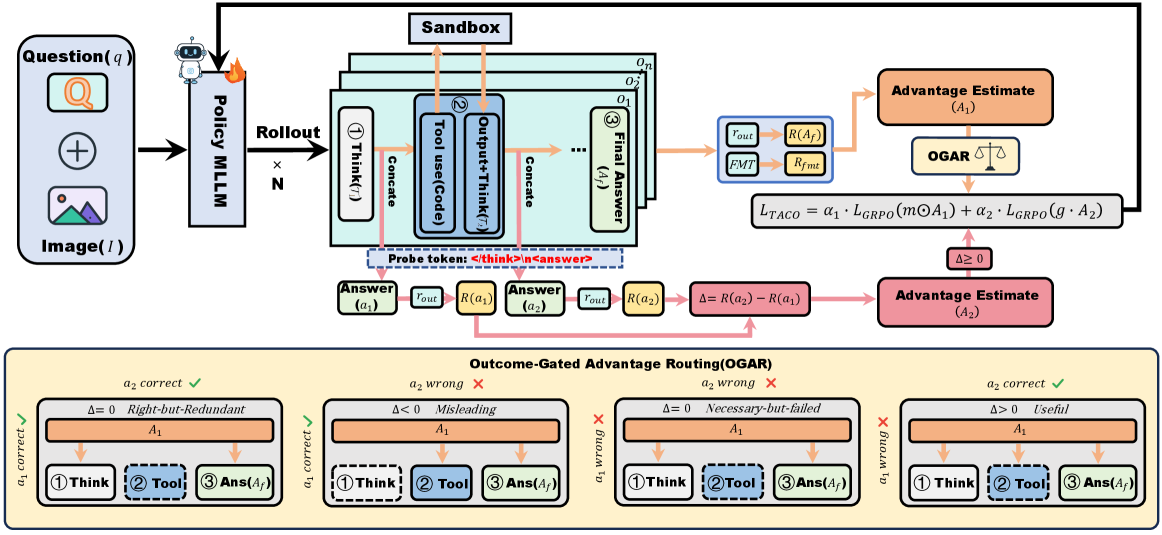
Figure 2 — TACO 프레임워크 개요
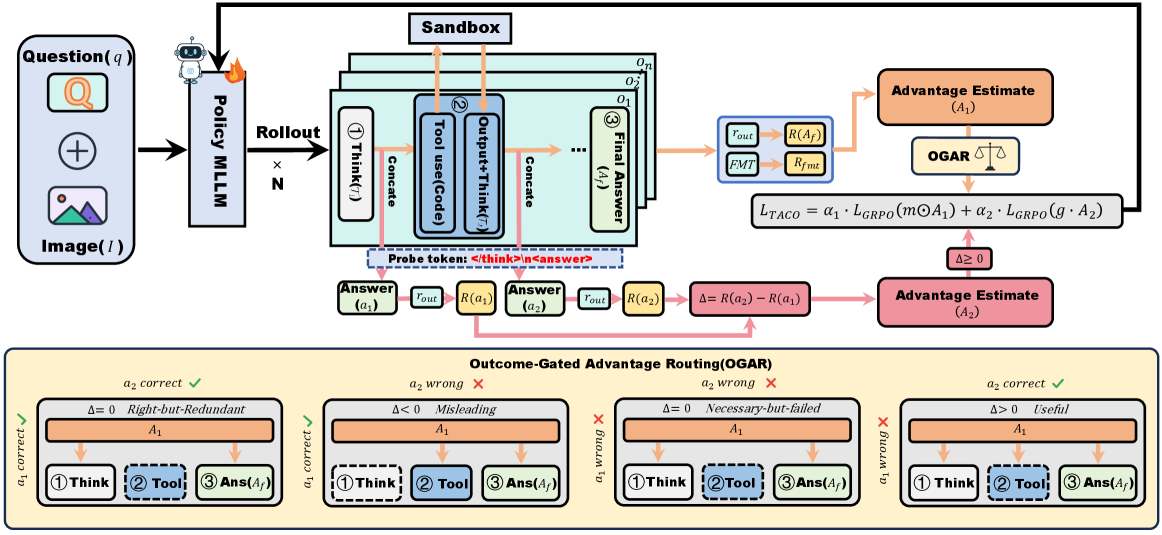
Table 1 — 벤치마크 성능 비교 결과
4. Conclusion & Impact (결론 및 시사점)
본 논문은 도구 호출의 개별 가치를 학습 과정에 반영함으로써 에이전트의 불필요한 도구 의존성을 성공적으로 개선하였다. 제안된 TACO 프레임워크는 외부 모델의 도움 없이도 모델 내부의 자기 성찰적 신호를 활용하여 정교한 크레딧 할당이 가능하다는 점에서 학술적 가치가 높다. 이는 향후 에이전트가 도구 호출을 더욱 지능적으로 판단하게 함으로써, 고성능 멀티모달 에이전트의 효율성과 정확성을 극대화하는 표준적인 학습 프레임워크로 자리 잡을 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] STARE: Surprisal-Guided Token-Level Advantage Reweighting for Policy Entropy Stability
- [논문리뷰] FIPO: Eliciting Deep Reasoning with Future-KL Influenced Policy Optimization
- [논문리뷰] VAR RL Done Right: Tackling Asynchronous Policy Conflicts in Visual Autoregressive Generation
- [논문리뷰] TreeGRPO: Tree-Advantage GRPO for Online RL Post-Training of Diffusion Models
- [논문리뷰] Learning User Simulators with Turing Rewards
Review 의 다른글
- 이전글 [논문리뷰] Scaling the Horizon, Not the Parameters: Reaching Trillion-Parameter Performance with a 35B Agent
- 현재글 : [논문리뷰] TACO: Tool-Augmented Credit Optimization for Agentic Tool Use
- 다음글 [논문리뷰] TUA-Bench: A Benchmark for General-Purpose Terminal-Use Agents
댓글