[논문리뷰] Scaling the Horizon, Not the Parameters: Reaching Trillion-Parameter Performance with a 35B Agent
링크: 논문 PDF로 바로 열기
메타데이터
저자: Lei Bai, Zongsheng Cao, Yang Chen, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Agents-A1: 35B Mixture-of-Experts 아키텍처를 기반으로 하며, 파라미터 확장이 아닌 에이전트 호라이즌(Horizon) 확장을 통해 1T-parameter 모델급 성능을 달성한 에이전트 모델입니다.
- Knowledge-Action Graph (KAG): 외부 지식, 에이전트의 Action, Observation, 그리고 Verifier의 결과를 통합하여 에이전트의 의사결정 과정을 추적 가능한 데이터 구조로 표현한 인프라입니다.
- Salient Vocabulary Alignment (SVA): On-Policy Distillation 과정에서 학생 모델과 교사 모델 간의 확률 분포를 교사가 선택한 핵심적인(Salient) 로컬 어휘 집합 내에서 일치시켜 지식 전이 효율을 극대화하는 기법입니다.
- Domain-Routed Normalized Objective: 여러 도메인에 걸쳐 학습할 때, 특정 도메인이 학습 과정을 지배하지 않도록 도메인별로 손실을 정규화하여 학습 안정성을 높이는 최적화 방식입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 에이전트 모델의 성능을 향상시키기 위한 기존의 파라미터 스케일링 전략이 갖는 높은 비용과 재현성 문제를 해결하기 위해 에이전트 호라이즌(Horizon) 확장을 제안합니다 [Figure 2]. 기존 모델들은 파라미터를 늘려 지식을 내재화하려 하지만, 이는 복잡한 long-horizon 작업에서 실수를 누적시키고 중간 의사결정 과정을 불투명하게 만듭니다. 저자들은 에이전트가 정보를 수집하고 도구를 활용하며 결과를 검증하는 전 과정을 명시적인 학습 데이터로 변환할 필요가 있다고 지적합니다. 이를 통해 모델이 단순히 정답을 맞히는 것을 넘어, 문제 해결의 전 과정을 학습하여 1T-parameter 모델 수준의 능력을 35B 모델에서도 구현하고자 합니다.
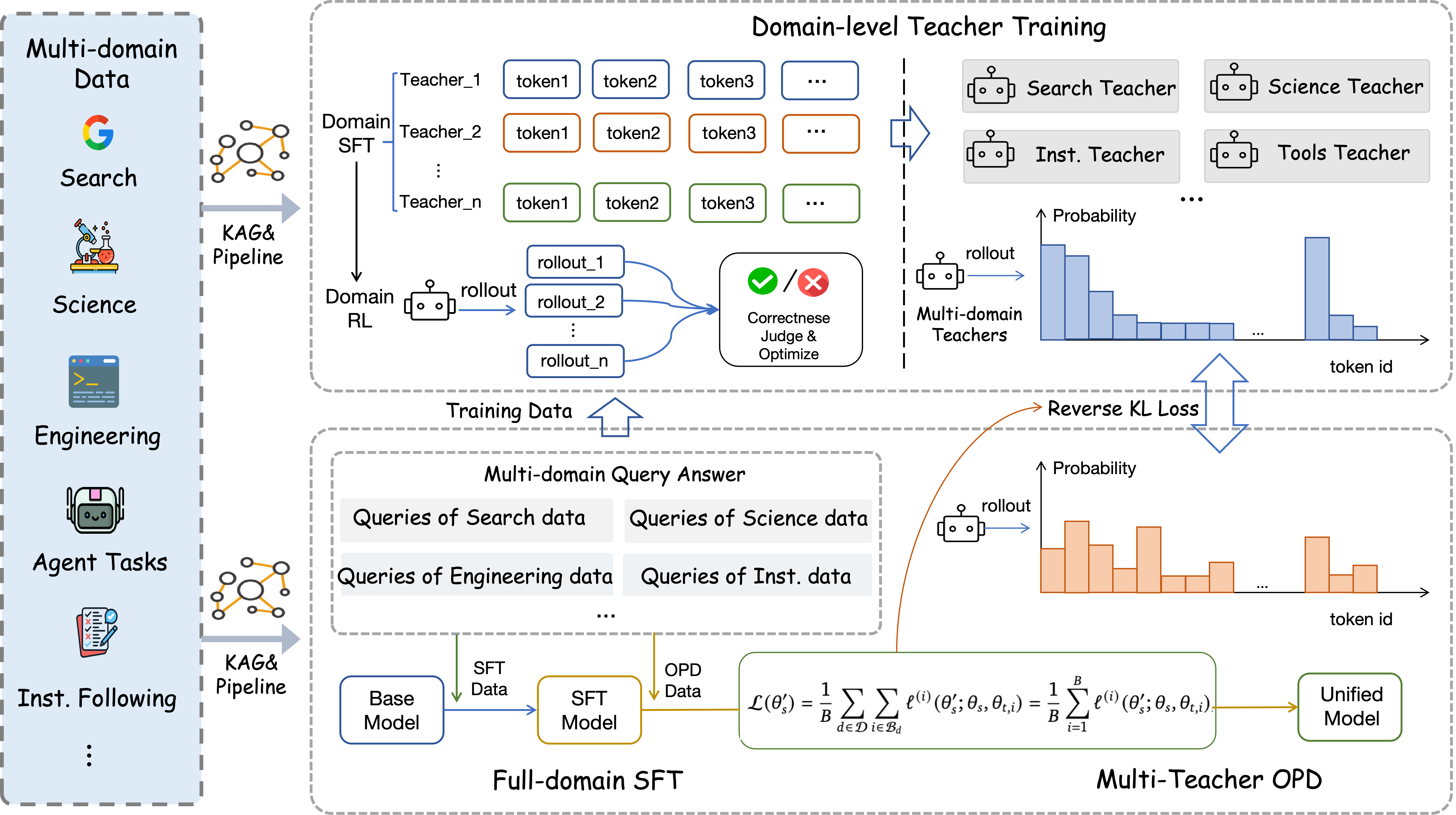
Figure 2 — 3단계 학습 파이프라인 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 세 단계의 Three-stage Training Recipe를 통해 Agents-A1을 학습시킵니다 [Figure 2]. 첫 번째 단계인 Full-domain Supervised Fine-Tuning을 통해 전반적인 에이전트 행동을 정렬하고, 두 번째 단계에서는 각 도메인별로 특화된 교사 모델을 훈련합니다. 마지막으로 Domain-routed On-Policy Distillation을 수행하여 여러 도메인의 전문 지식을 단일 학생 모델로 통합합니다. 이 과정에서 Salient Vocabulary Alignment를 사용하여 교사 모델의 핵심 지식만을 효과적으로 전이합니다. 실험 결과, Agents-A1은 SEAL-0에서 56.4, IFBench에서 80.6, FrontierScience-Olympiad에서 79.0의 점수를 기록하며 1T-parameter 급 모델인 Kimi-K2.6 및 DeepSeek-V4-pro와 대등하거나 우수한 성능을 입증했습니다 [Figure 1]. 이러한 성과는 45K tokens에 달하는 긴 호라이즌 트레이닝 데이터와 정교한 Knowledge-Action Infrastructure의 결합을 통해 가능했습니다.
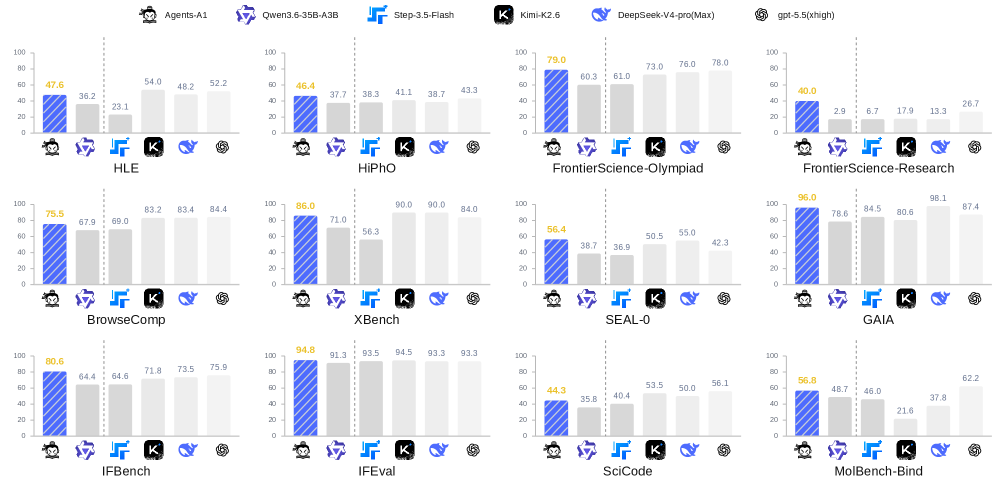
Figure 1 — 모델 벤치마크 성능 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 파라미터 크기 경쟁에서 벗어나 에이전트 호라이즌과 지식 인프라를 확장하는 것이 고성능 에이전트 구현의 실질적인 경로임을 증명합니다. 35B 모델인 Agents-A1이 1T 모델의 성능을 달성했다는 점은 향후 효율적인 에이전트 학습 연구에 중요한 이정표가 될 것입니다. 특히 도메인 특화 지식을 통합하는 정교한 증류 방법론은 산업계의 다양한 에이전트 응용 분야에 즉각적으로 활용될 수 있는 기술적 토대를 제공합니다.
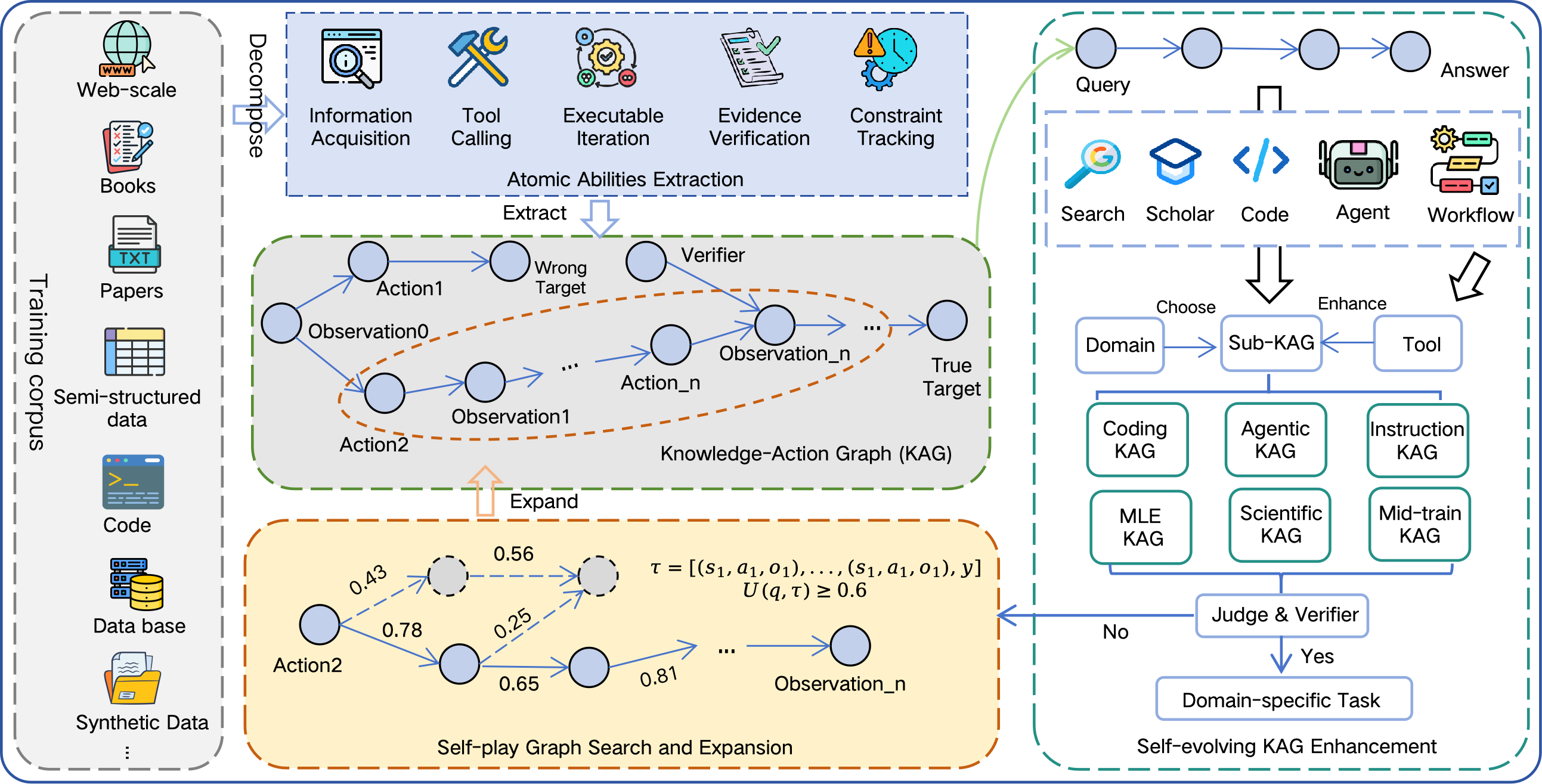
Figure 3 — 지식-행동 인프라 구조
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] QVal: Cheaply Evaluating Dense Supervision Signals for Long-Horizon LLM Agents
- [논문리뷰] Focusing on What Matters: Saliency-Harnessing Accurate Routing for Diffusion MoE
- [논문리뷰] OPID: On-Policy Skill Distillation for Agentic Reinforcement Learning
- [논문리뷰] DanceOPD: On-Policy Generative Field Distillation
- [논문리뷰] CoffeeBench: Benchmarking Long-Horizon LLM Agents in Heterogeneous Multi-Agent Economies
Review 의 다른글
- 이전글 [논문리뷰] SafePyramid: A Hierarchical Benchmark for In-context Policy Guardrailing
- 현재글 : [논문리뷰] Scaling the Horizon, Not the Parameters: Reaching Trillion-Parameter Performance with a 35B Agent
- 다음글 [논문리뷰] TACO: Tool-Augmented Credit Optimization for Agentic Tool Use
댓글