[논문리뷰] SciOrch: Learning to Orchestrate Expert LLMs for Solving Frontier Multimodal Scientific Reasoning Tasks
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jingru Guo, Xiangyuan Xue, Lian Zhang, Wanghan Xu, Siki Chen, Philip Torr, Wanli Ouyang, Lei Bai, Zhenfei Yin
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- SciOrch: 경량화된 8B 파라미터 모델을 오케스트레이터(Orchestrator)로 활용하여 전문화된 상용 LLM들을 동적으로 제어 및 조합하는 프레임워크입니다.
- Orchestration: 복잡한 다중 모달 과학 문제를 여러 하위 문제로 분해하고, 각 문제에 최적화된 특정 전문 모델(Expert LLM)에 API 호출을 통해 작업을 위임하는 전략적 의사결정 과정입니다.
- MCTS (Monte Carlo Tree Search): API 호출의 비용과 지연 시간(Latency) 문제로 인한 실시간 강화학습의 한계를 극복하기 위해, 다양한 오케스트레이션 경로를 탐색하고 학습 데이터를 생성하는 트리 탐색 알고리즘입니다.
- GRPO (Group Relative Policy Optimization): 에이전트의 정책 업데이트를 최적화하기 위해 그룹 내 상대적 보상을 활용하는 강화학습 기법으로, 본 논문에서는 REINFORCE++와 결합하여 사용됩니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 frontier multimodal scientific reasoning 분야에서 단일 상용 LLM 시스템이 전문가 수준의 성능을 달성하지 못하는 한계를 극복하고자 합니다. 기존의 프롬프트 기반 다중 에이전트 기법들은 작업 난이도나 도메인 특성과 상관없이 일괄적인 프로토콜을 사용하여 비용 효율성이 낮고 성능 향상이 정체되는 단점이 있습니다. 또한, 기존의 라우팅 기반 기법은 모델을 사전 선택한 후 중간 증거에 따라 동적으로 전략을 수정하거나 문제를 분해하지 못하는 한계를 보입니다. 이러한 문제점들을 해결하기 위해, 연구진은 모델 간의 상호 보완성을 활용하여 문제 해결을 위한 동적인 오케스트레이션 전략이 필수적임을 정의하였습니다. [Figure 1]은 서로 다른 모델들이 과학 분야별로 보여주는 상호 보완적 성능을 시각화하여, 단일 모델이 아닌 조합된 모델 풀이 가진 잠재력을 강조합니다.
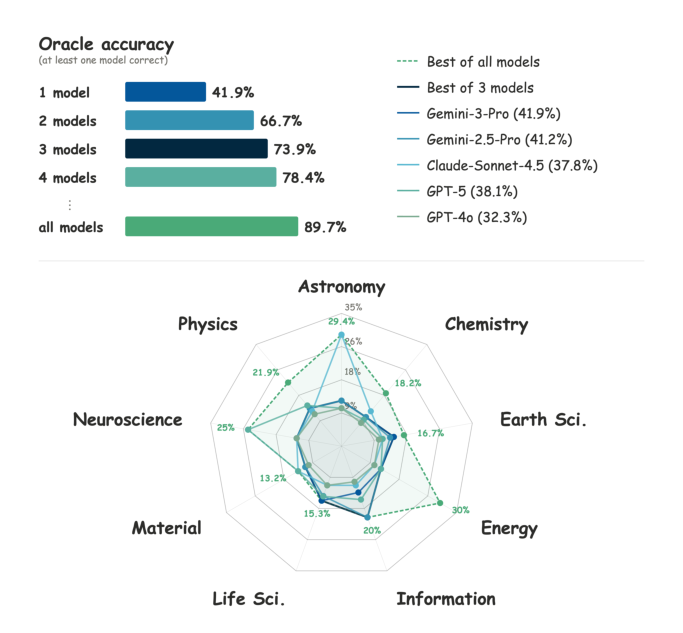
Figure 1 — 모델 간의 성능 상호 보완성을 보여주는 핵심 데이터 시각화
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 논문은 SciOrch를 제안하여 LLM을 활용한 과학적 추론을 다단계 의사결정 문제로 재구성하고, API 호출 기반의 환경에서 학습 효율을 극대화하기 위해 MCTS를 통합한 강화학습 기법을 적용하였습니다. [Figure 2]는 기존의 정적 다중 에이전트 방식과 대비되는 SciOrch의 동적 오케스트레이션 구조를 설명합니다. 훈련 과정에서는 오케스트레이터가 Qwen3-VL-8B 모델을 백본으로 사용하며, MCTS를 통해 다양한 오케스트레이션 경로를 탐색한 후 노드별 보상(non-cumulative reward)을 사용하여 **REINFORCE++**로 정책을 업데이트합니다. 이 접근 방식은 대규모 온라인 롤아웃 없이도 효율적인 학습이 가능하게 합니다. 실험 결과, SciOrch는 240개의 테스트 문제셋에서 평균 정확도 56.66%를 달성하여 가장 강력한 단일 모델인 Gemini-3-Pro 대비 3.74% 향상된 성능을 보였습니다. 또한, 기존의 강력한 다중 에이전트 기반 기법과 비교해서도 3.33% 높은 성능을 기록하였으며, API 비용 또한 경쟁 기법 대비 절반 이하 수준으로 대폭 절감했습니다. [Table 2]는 이러한 성능 비교 지표를 명확히 제시합니다.
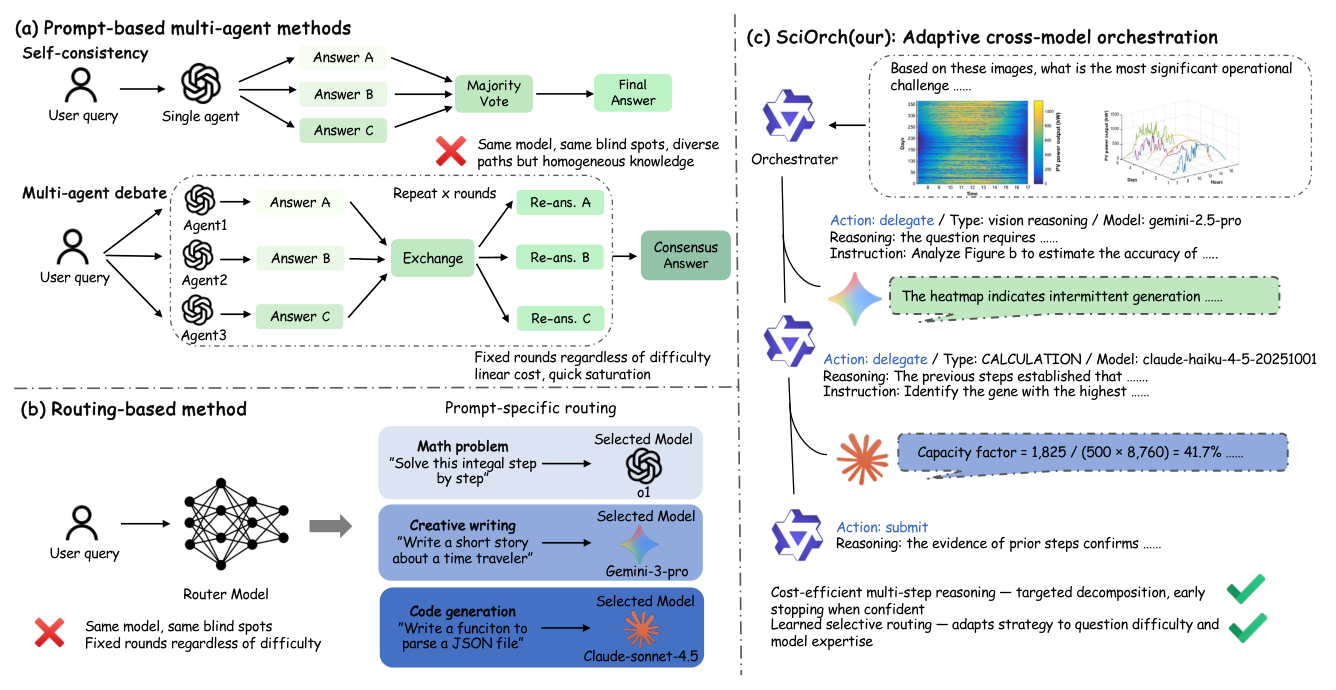
Figure 2 — 제안 모델인 SciOrch의 동적 오케스트레이션 방식과 기존 방식 간의 구조적 차이를 명시
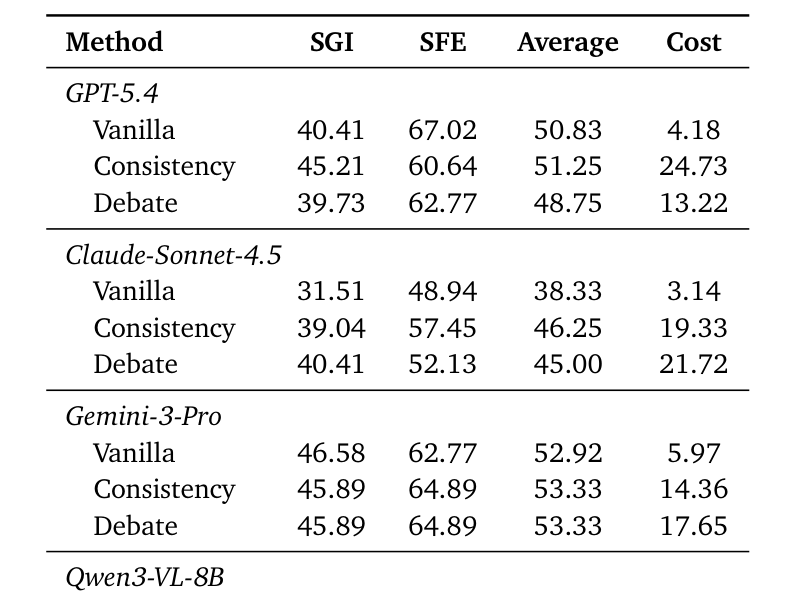
Table 2 — 제안 방법론의 정량적 성능 우위 및 비용 효율성을 증명하는 핵심 비교 테이블
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 과학적 추론을 위한 최적의 모델 오케스트레이션이 단일 모델의 성능 향상보다 효율적인 협업 전략 수립에 있음을 입증하였습니다. 제안된 MCTS 기반의 학습 프레임워크는 비용이 높은 API 환경에서도 모델의 추론 성능을 극대화할 수 있는 실용적인 해결책을 제시합니다. 본 연구는 향후 범용적인 과학적 에이전트 시스템을 설계함에 있어, 대규모 모델을 직접 구축하는 방식 외에도 소규모 에이전트가 전문가 모델들을 지휘하는 방식의 효용성을 학계와 산업계에 크게 시사합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Dr. MAS: Stable Reinforcement Learning for Multi-Agent LLM Systems
- [논문리뷰] MASPRM: Multi-Agent System Process Reward Model
- [논문리뷰] Thinking with Visual Grounding
- [논문리뷰] DragMesh-2: Physically Plausible Dexterous Hand-Object Interaction with Articulated Objects
- [논문리뷰] STARE: Surprisal-Guided Token-Level Advantage Reweighting for Policy Entropy Stability
Review 의 다른글
- 이전글 [논문리뷰] STARE: Surprisal-Guided Token-Level Advantage Reweighting for Policy Entropy Stability
- 현재글 : [논문리뷰] SciOrch: Learning to Orchestrate Expert LLMs for Solving Frontier Multimodal Scientific Reasoning Tasks
- 다음글 [논문리뷰] Sumi: Open Uniform Diffusion Language Model from Scratch
댓글