[논문리뷰] Sumi: Open Uniform Diffusion Language Model from Scratch
링크: 논문 PDF로 바로 열기
메타데이터
저자: Mengyu Ye, Keito Kudo, Wataru Ikeda, Ryosuke Matsuda, Keisuke Sakaguchi, Jun Suzuki
1. Key Terms & Definitions (핵심 용어 및 정의)
- UDLM (Uniform Diffusion Language Model): 모든 토큰이 업데이트 가능한 확산 기반 언어 모델로, 생성의 유연성과 자기 교정 잠재력을 가진 모델 아키텍처를 지칭함.
- GIDD (Generalized Interpolating Discrete Diffusion): Sumi가 기반으로 하는 확산 프레임워크로, SNR(Signal-to-Noise Ratio)을 통해 ELBO를 재매개변수화하여 학습 안정성을 높인 기법임.
- Canvas Length: 생성 과정에서 모델이 사용할 수 있는 총 토큰 공간의 크기를 의미하며, 고정된 크기의 버퍼로 작동함.
- Confidence Sampling: 생성 과정에서 모델의 확신도에 따라 토큰 업데이트 우선순위를 결정하는 샘플링 기법임.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 대규모 파라미터와 데이터 스케일로 scratch부터 사전 학습된 UDLM의 부재를 해결하고자 한다. 기존의 Autoregressive (AR) 모델이나 Masked Diffusion Language Models (MDLMs)와 달리, Uniform Diffusion은 마스킹 공정의 제약을 완화하여 더 유연한 생성과 자기 교정을 가능하게 하지만, 데이터가 풍부한 환경에서의 대규모 학습 연구는 미흡했다 [Figure 1]. 저자들은 7B 규모의 Sumi 모델을 통해 대규모 Uniform Diffusion의 확장 법칙(scaling behavior)과 생성 역학을 탐구하고자 한다.
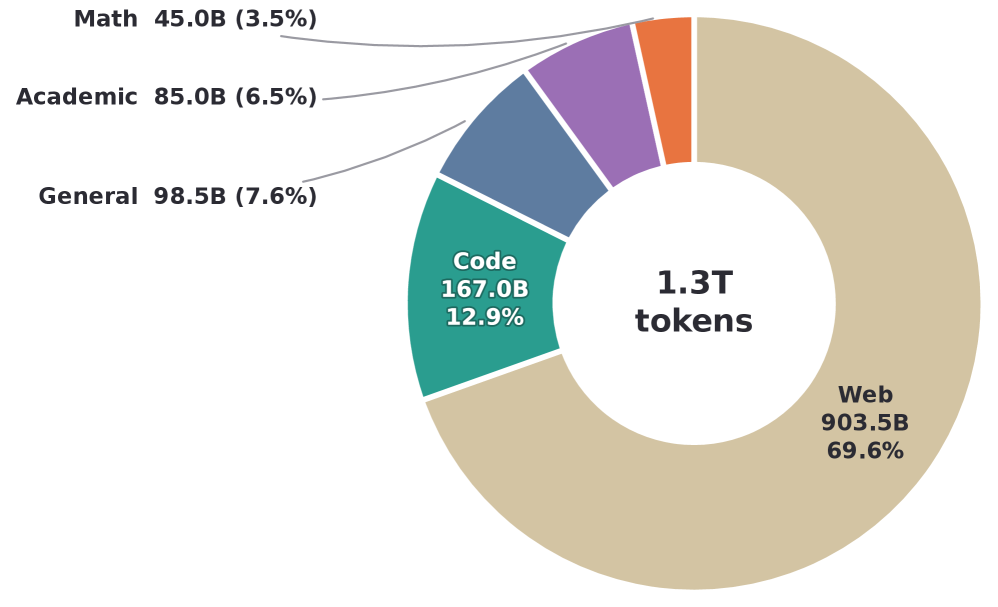
Figure 1 — Sumi의 학습 데이터 구성
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 7B 파라미터의 Sumi 모델을 1.5T 토큰 규모로 scratch부터 사전 학습시킨 프레임워크를 제안한다. 아키텍처는 GIDD 목적함수를 기반으로 하며, 학습 효율성을 위해 RoPE 임베딩과 SwiGLU MLP, 그리고 Megatron-LM 프레임워크를 활용하였다 [Figure 1]. 실험 결과, Sumi-7B는 지식, 추론, 코딩 벤치마크에서 동등한 컴퓨팅 자원으로 학습된 AR 모델들과 경쟁력 있는 성능을 보였다 [Table 1]. 특히 HumanEval에서 22.6, MBPP에서 26.6의 점수를 기록하며 코딩 태스크에서 강점을 드러냈다 [Table 1]. 반면, 상식 추론 태스크에서는 데이터 구성의 영향으로 성능 격차가 관찰되었으며, 이는 교육 중심의 데이터 혼합이 주요 원인으로 분석된다 [Figure 1, Table 1].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 대규모로 사전 학습된 최초의 UDLM인 Sumi를 공개하여 Uniform Diffusion 연구의 기준점을 마련하였다. 연구진의 분석은 Uniform Diffusion이 고유한 생성 구조와 제한적 병렬 디코딩 능력을 갖추고 있음을 시사하며, 이는 차세대 언어 모델 아키텍처 연구에 중요한 통찰을 제공한다. 본 모델의 오픈 소스 공개는 커뮤니티가 네이티브 Uniform Diffusion의 확장성과 제어 능력을 심도 있게 탐구할 수 있는 발판이 될 것으로 기대된다.
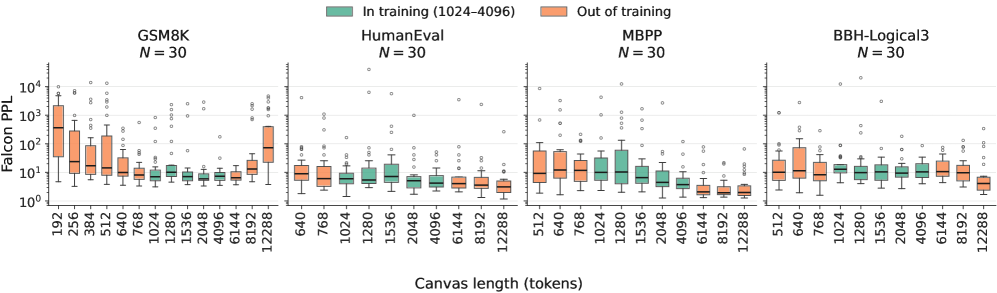
Figure 2 — 캔버스 길이에 따른 생성 유창성

Figure 3 — 샘플링 방식에 따른 커밋 순서
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] villa-X: Enhancing Latent Action Modeling in Vision-Language-Action Models
- [논문리뷰] No Resource, No Benchmarks, No Problem? Evaluating and Improving LLMs for Code Generation in No-Resource Languages
- [논문리뷰] Moebius: 0.2B Lightweight Image Inpainting Framework with 10B-Level Performance
- [논문리뷰] FreeStyle: Free Control of Style-Content Dual-Reference Generation from Community LoRA Mining
- [논문리뷰] Text-Vision Co-Instructed Image Editing
Review 의 다른글
- 이전글 [논문리뷰] SciOrch: Learning to Orchestrate Expert LLMs for Solving Frontier Multimodal Scientific Reasoning Tasks
- 현재글 : [논문리뷰] Sumi: Open Uniform Diffusion Language Model from Scratch
- 다음글 [논문리뷰] Trust the Right Teacher: Quality-Aware Self-Distillation for GUI Grounding
댓글