[논문리뷰] Conditional Equivalence of DPO and RLHF: Implicit Assumption, Failure Modes, and Provable Alignment
링크: 논문 PDF로 바로 열기
메타데이터
저자: Zhiqin Yang, Yonggang Zhang, Wei Xue, Dong Fang, Bo Han, Yike Guo
1. Key Terms & Definitions (핵심 용어 및 정의)
- DPO (Direct Preference Optimization): 보상 모델(Reward Model) 없이 선호 데이터셋을 활용해 정책 모델(Policy Model)을 직접 최적화하는 기법입니다.
- RLHF (Reinforcement Learning from Human Feedback): 인간 피드백을 기반으로 한 보상 모델을 사용하여 LLM을 정렬(Alignment)하는 기법입니다.
- CPO (Constrained Preference Optimization): RLHF 객체에 명시적 제약(Constraints)을 추가하여 DPO의 정렬 실패 모드를 방지하고 선호 정렬을 보장하는 제안 방법론입니다.
- BT Model (Bradley-Terry Preference Model): 선호 데이터의 확률을 두 응답의 보상 차이로 모델링하는 표준적인 통계 프레임워크입니다.
- Undesirable Solution Space (𝒰): DPO가 손실 함수를 감소시키면서도 실제로는 인간의 선호에 반하는 응답을 선택하는 병리적(Pathological) 정책 영역을 지칭합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 DPO와 RLHF 간의 이론적 동치성이 모든 경우에 성립하는 것이 아니라, 특정 가정에 의존하는 조건부 동치성임을 밝힙니다. 기존 연구들은 RLHF 최적 정책이 항상 인간 선호 응답을 더 높게 평가한다는 암묵적 가정 하에 DPO를 도출했으나, 실제 RLHF 환경에서는 기준 정책(Reference Policy)의 품질이 낮을 경우 이 가정이 성립하지 않습니다. 이로 인해 DPO는 인간과의 절대적 정렬이 아닌 기준 정책 대비 상대적 우위만을 최적화하게 되며, 결과적으로 손실값은 줄어들지만 인간 선호에 위배되는 응답을 생성하는 병리적 수렴 현상이 발생합니다. 저자들은 이러한 현상이 발생하는 Undesirable Solution Space를 정의하고, 기존 DPO의 정렬 보증 한계를 이론적으로 규명합니다. [Figure 1]
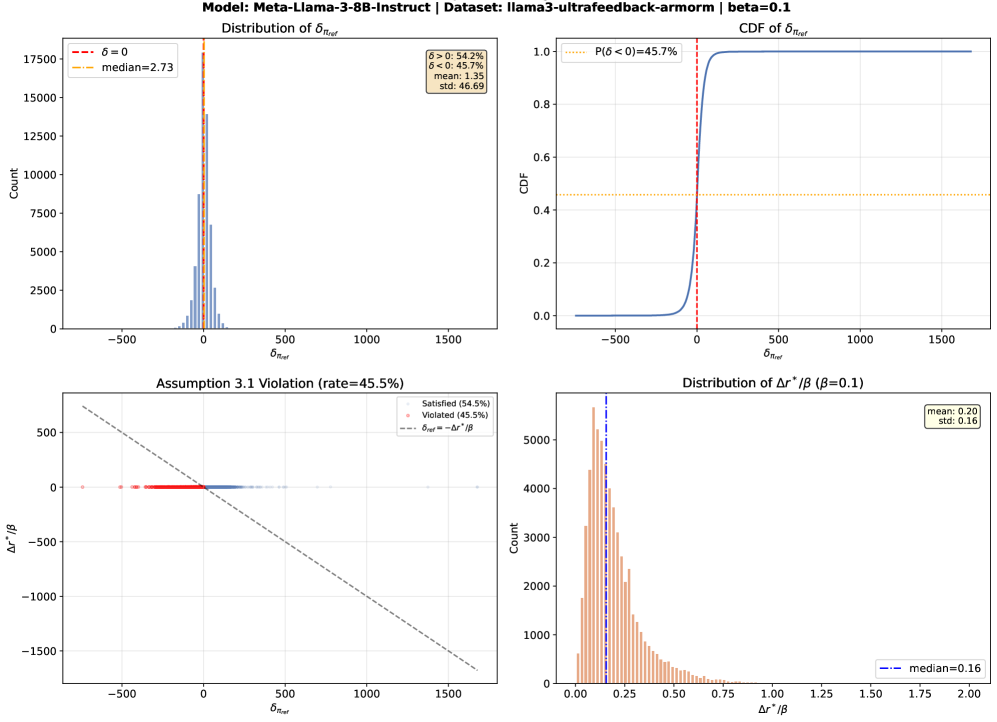
Figure 1 — 정렬 위반 빈도 분석
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 RLHF 목적함수에 명시적 제약 조건을 추가한 CPO(Constrained Preference Optimization)를 제안하여 절대적인 선호 정렬을 보장합니다. 또한 보상 모델링이 불필요한 보수적 변형 기법인 E-CPOC를 도입하여, 표준 통계적 학습 가정 하에 제약 있는 RLHF와 공식적으로 동등한 정렬 성능을 달성합니다. 이 방법론들은 Soft Margin Ranking 관점에서 DPO를 해석할 때, 잠재적으로 음수일 수 있는 타겟 마진을 강제로 비음수(Non-negative)로 수정함으로써 정렬의 안전성을 확보합니다. 실험 결과, Llama-3-8B-Instruct 모델 기준 CPO는 AlpacaEval 2와 Arena-Hard 벤치마크에서 기존 DPO를 유의미하게 상회하는 성능을 보였습니다. 특히 Arena-Hard에서 CPO는 32.6%의 Win Rate를 기록하며, SimPO(30.0%) 대비 +2.6%, DPO(28.9% 수준) 대비 +3.7% 높은 정량적 우위를 확인하였습니다. 이는 CPO가 기준 정책이 미정렬된 상황에서도 강건하게 성능을 유지함을 보여줍니다. [Figure 2]
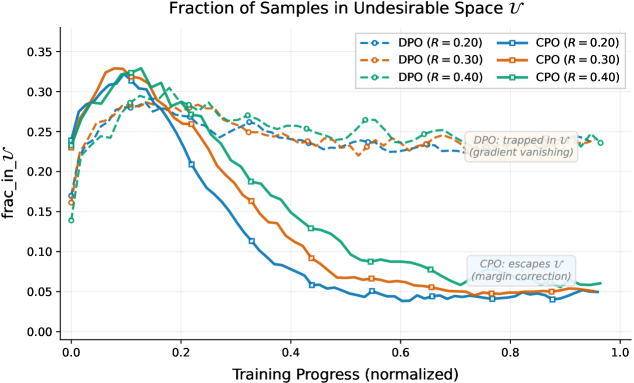
Figure 2 — 병리적 공간 𝒰 내 샘플 비율
4. Conclusion & Impact (결론 및 시사점)
본 논문은 DPO와 RLHF가 조건부로만 동치임을 증명하고, DPO의 정렬 실패 메커니즘을 이론적으로 정립하였습니다. 제안된 CPO와 E-CPOC는 마진 기반의 정렬 강제 기법을 통해 병리적 수렴을 방지하며, 실무적으로는 보상 모델 없이도 안정적인 학습을 가능하게 합니다. 이 연구는 LLM 정렬 분야에서 마진 기반 최적화의 중요성을 재조명하며, 데이터 신뢰도가 낮은 환경에서도 정렬 안정성을 확보할 수 있는 이론적/실천적 근거를 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Reproducing, Analyzing, and Detecting Reward Hacking in Rubric-Based Reinforcement Learning
- [논문리뷰] Reward Hacking in the Era of Large Models: Mechanisms, Emergent Misalignment, Challenges
- [논문리뷰] DRIFT: Learning from Abundant User Dissatisfaction in Real-World Preference Learning
- [논문리뷰] The Mirage of Optimizing Training Policies: Monotonic Inference Policies as the Real Objective for LLM Reinforcement Learning
- [논문리뷰] Qwen-Image-2.0-RL Technical Report
Review 의 다른글
- 이전글 [논문리뷰] A Survey of Large Audio Language Models: Generalization, Trustworthiness, and Outlook
- 현재글 : [논문리뷰] Conditional Equivalence of DPO and RLHF: Implicit Assumption, Failure Modes, and Provable Alignment
- 다음글 [논문리뷰] CutVerse: A Compositional GUI Agents Benchmark for Media Post-Production Editing
댓글