[논문리뷰] Mem-π: Adaptive Memory through Learning When and What to Generate
링크: 논문 PDF로 바로 열기
저자: Xiaoqiang Wang, Chao Wang, Hadi Nekoei, Christopher Pal, Alexandre Lacoste, Spandana Gella, Bang Liu, Perouz Taslakian
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Mem-π: 에이전트의 작업 맥락(context)에 맞춰 필요한 경우에만 맞춤형 가이드를 생성하는 매개변수 기반의 생성형 메모리 프레임워크입니다.
- Decision-Content Decoupled Policy Optimization: 메모리 생성 여부를 결정하는 'when'과 생성될 가이드의 내용을 결정하는 'what'을 구조화된 카운터팩추얼 롤아웃을 통해 분리하여 학습하는 강화학습 기법입니다.
- Experience Distillation: 오프라인 경험 뱅크를 지도 학습(Supervised Learning)을 통해 메모리 정책 모델 내부의 매개변수로 압축하여 재사용 가능한 행동 지식을 내재화하는 단계입니다.
- Adaptation Distillation: 강화학습을 통해 메모리 정책을 사후 최적화하여, 에이전트의 작업 결과(Task Success)와 실질적으로 정렬되도록 조정하는 단계입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 기존 LLM 에이전트의 정적인 메모리 검색 패러다임이 갖는 한계를 극복하기 위해 제안되었습니다. 현재의 메모리 증강 에이전트들은 주로 외부 저장소에서 과거의 경험을 검색하는 방식에 의존하지만, 이러한 검색된 데이터는 현재의 에이전트 맥락과 맞지 않거나 지나치게 특수하여 범용성이 떨어지는 문제가 있습니다. 또한, 기존의 생성형 접근 방식들조차 맥락에 대한 조건 없이 가이드를 무조건 생성하거나 검색 결과를 모방하는 수준에 머물러 있어, 오히려 잘못된 정보를 전파할 위험이 있습니다 [Figure 1]. 이러한 문제를 해결하기 위해 저자들은 에이전트가 스스로 메모리 생성이 필요한 상황을 판단하고, 가장 적절한 가이드를 생성하도록 하는 프레임워크를 설계하였습니다.
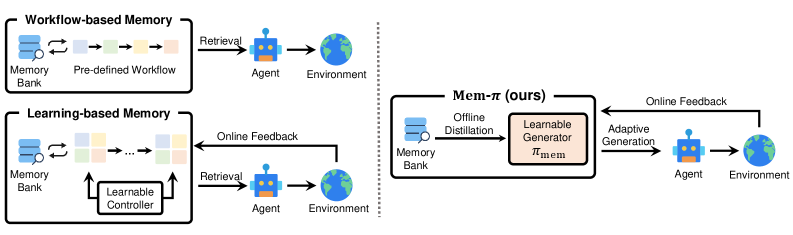
Figure 1 — 기존 메모리 시스템과 Mem-π 비교
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 저자들이 제안하는 Mem-π는 메모리를 별도의 생성형 정책 모델($\pi_{\text{mem}}$)로 정의하며, Experience Distillation과 Adaptation Distillation이라는 두 단계의 학습 과정을 거칩니다 [Figure 2]. 특히 Decision-Content Decoupled Policy Optimization을 도입하여 메모리 생성 여부를 결정하는 [GENERATE]/[ABSTAIN] 토큰과 생성되는 가이드 내용을 분리된 advantage로 학습함으로써, 메모리가 불필요한 상황에서는 스스로 생성을 중단(abstain)하는 적응적 메모리 생성 능력을 확보하였습니다. 실험 결과, Mem-π는 WebArena, WorkArena, LifelongAgentBench, ALFWorld 등 4개 주요 벤치마크에서 기존의 검색 기반(RAG, Mem0) 및 RL 최적화 메모리(Memory-R1, MemRL) 방식 대비 평균적으로 20% 이상의 성능 향상을 달성하였습니다 [Table 1]. 특히, 복잡한 웹 탐색 작업인 WebArena에서는 50%에 육박하는 상대적 성능 개선을 보였으며, 시각적 정보가 결합된 멀티모달 환경에서도 Qwen2.5-VL-7B-Instruct 기반의 모델이 높은 범용성을 입증하였습니다 [Figure 3].
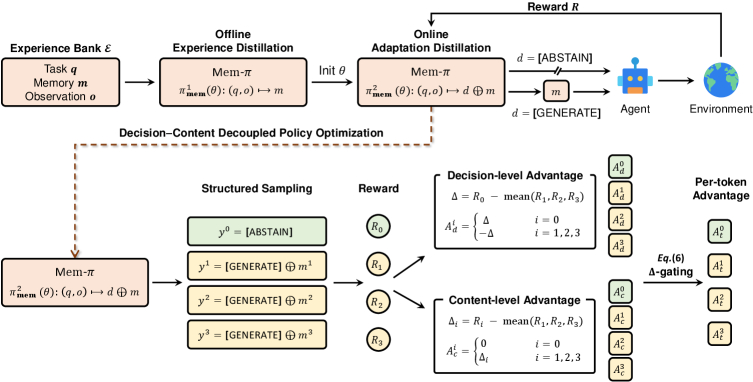
Figure 2 — Mem-π의 전체 프레임워크
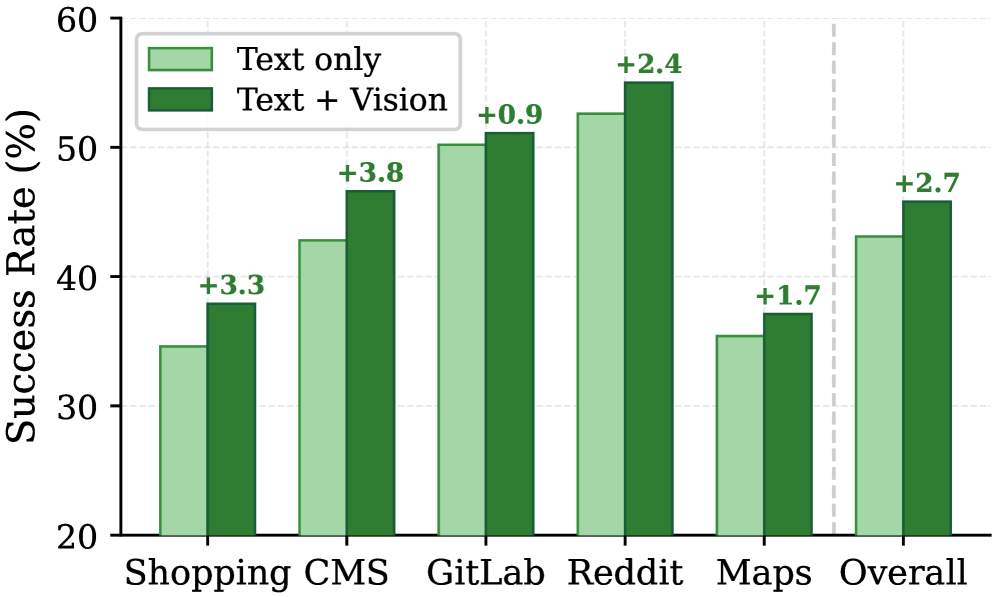
Figure 3 — 시각적 정보 활용에 따른 성능 비교
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 에이전트의 메모리를 고정된 데이터의 검색 결과가 아닌, 동적으로 생성되는 매개변수 기반 정책으로 재정의함으로써 LLM 에이전트의 효율성과 신뢰성을 동시에 확보했습니다. 학습을 통한 적응적 생성을 통해 불필요한 메모리 노이즈를 제거하고 필요한 상황에서만 정교한 가이드를 제공하는 방식은 향후 자율적 에이전트 시스템의 메모리 관리 표준이 될 가능성이 큽니다. 이 연구는 단순한 데이터 검색을 넘어, 에이전트가 경험으로부터 실질적인 절차적 지식을 내부화하여 더 복잡한 환경에 능동적으로 대처할 수 있는 가능성을 제시합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Spreadsheet-RL: Advancing Large Language Model Agents on Realistic Spreadsheet Tasks via Reinforcement Learning
- [논문리뷰] Understanding Reasoning from Pretraining to Post-Training
- [논문리뷰] On-Policy Delta Distillation
- [논문리뷰] Beyond Entropy: Correctness-Aware Advantage Shaping via Contrastive Policy Optimization
- [논문리뷰] Agon: Competitive Cross-Model RL with Implicit Rival Grading of Reasoning
Review 의 다른글
- 이전글 [논문리뷰] Mega-ASR: Towards In-the-wild^2 Speech Recognition via Scaling up Real-world Acoustic Simulation
- 현재글 : [논문리뷰] Mem-π: Adaptive Memory through Learning When and What to Generate
- 다음글 [논문리뷰] Mix-Quant: Quantized Prefilling, Precise Decoding for Agentic LLMs
댓글