[논문리뷰] PlanningBench: Generating Scalable and Verifiable Planning Data for Evaluating and Training Large Language Models
링크: 논문 PDF로 바로 열기
저자: Ziliang Zhao, Zenan Xu, Shuting Wang, Hongjin Qian, Yan Lei, Minda Hu, Zhao Wang, Shihan Dou, Zhicheng Dou, Pluto Zhou
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- PlanningBench: 실세계 계획 시나리오를 추상화하여 확장 가능하고 검증 가능한 계획 데이터를 생성하는 합성 데이터 프레임워크입니다.
- Constraint-driven Synthesis: 데이터 생성을 위해 구조화된 task-constraint 구성을 샘플링하고, 검증 가능한 인스턴스를 동적으로 제안하는 파이프라인입니다.
- All-pass: 모델이 단일 응답으로 체크리스트의 모든 제약 조건을 만족했는지 측정하는 완벽한 솔루션 달성 지표입니다.
- Avg-pass: 체크리스트의 전체 항목 중 모델이 만족시킨 항목의 비율을 측정하는 지표로, 부분적인 계획 수립 능력을 나타냅니다.
- GRPO (Group Relative Policy Optimization): PlanningBench 데이터를 활용하여 모델의 추론 및 계획 능력을 강화하기 위해 사용된 강화학습 알고리즘입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 기존의 계획 벤치마크가 고정된 인스턴스 집합에 의존하여 시나리오의 다양성과 구조적 복잡도를 충분히 반영하지 못하는 한계를 극복하기 위해 제안되었습니다. 기존 연구들은 단순히 프롬프트 길이 등 표면적인 지표로 난이도를 측정하며, 자동화된 검증 및 확장 가능한 데이터 생성이 결여되어 있었습니다. 결과적으로 frontier LLM들이 복잡하게 결합된 제약 조건 하에서 일관된 계획을 수립하는 데 어려움을 겪고 있으며, 이는 고도화된 planning 능력을 평가하기 위한 보다 체계적인 데이터 생성 체계의 필요성을 시사합니다. [Figure 2]는 이러한 문제를 해결하기 위한 PlanningBench의 제어 가능한 생성 파이프라인을 보여줍니다.
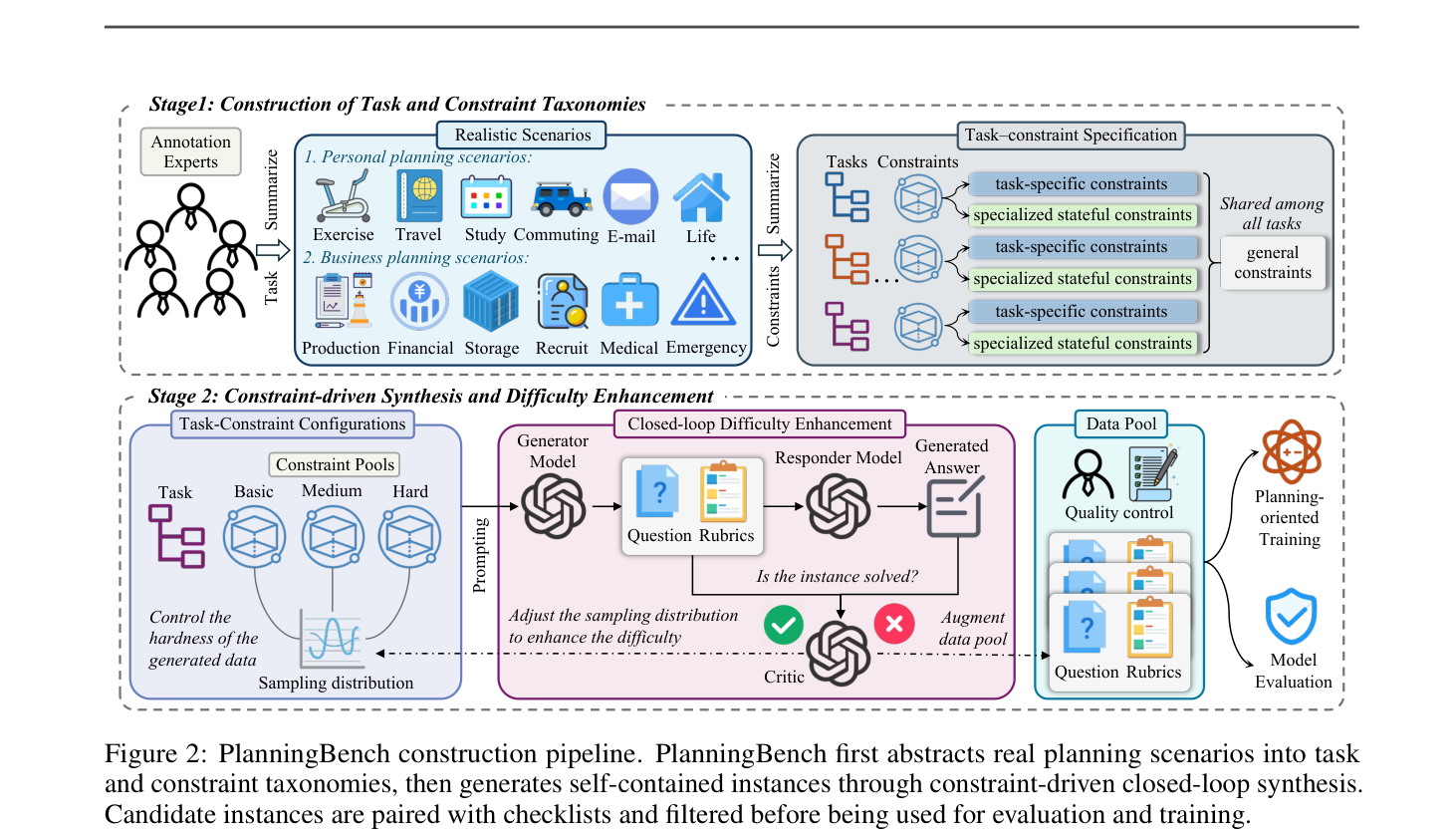
Figure 2 — 태스크 및 제약 조건의 합성부터 데이터 풀 생성까지의 전체 프레임워크 아키텍처
## 3. Method & Key Results (제안 방법론 및 핵심 결과) PlanningBench는 real-world planning 시나리오를 추상화한 30개 이상의 태스크 유형과 태스크별 제약 조건 구조를 바탕으로, closed-loop 강화학습 환경에서 최적화된 데이터를 생성합니다. 이 프레임워크는 task taxonomy를 통해 구조적 복잡도를 확보하고, constraint-driven 합성을 통해 adaptive한 난이도 조절을 수행합니다. 성능 평가 결과, 가장 우수한 모델인 GPT-5.4-xhigh조차 All-pass 기준 63.17%의 성과를 기록하여 평가 데이터셋이 매우 도전적임을 증명했습니다. [Table 2]에서 확인할 수 있듯이, 모델 간 All-pass와 Avg-pass 사이의 격차는 모델이 부분적으로는 조건을 만족할 수 있으나, 전역적인 일관성을 유지하는 계획 수립에는 여전히 큰 한계가 있음을 시사합니다. 또한 Syn-PlanningBench로 학습된 모델은 외부 벤치마크인 ChinaTravel과 TravelPlanner에서 All-pass 기준 각각 약 7.44%, 18.01% 이상의 성능 향상을 보이며 우수한 전이 학습 성능을 입증했습니다. [Table 1]은 본 연구가 기존의 고정형 벤치마크와 달리 확장 가능한 제어와 검증 가능성을 모두 갖췄음을 보여줍니다.

Table 1 — 기존 계획 벤치마크들과의 기능적 차이점을 비교한 핵심 표
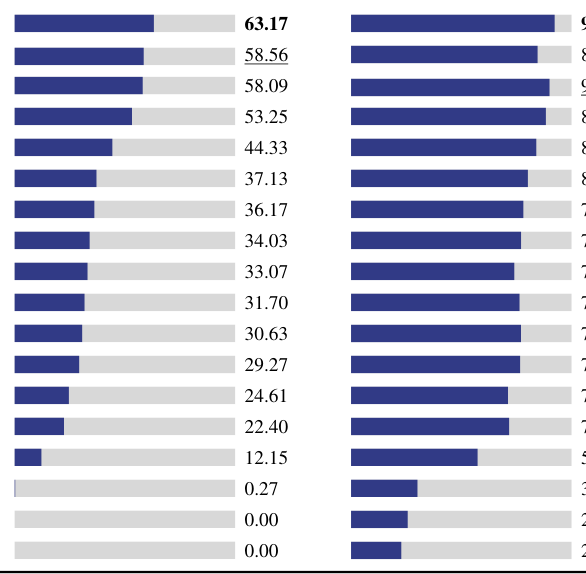
Table 2 — 다양한 모델들에 대한 성능 평가 결과를 비교한 핵심 지표 테이블
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 고도로 구조화된 계획 데이터를 합성하고 이를 통해 LLM의 전역적 일관성 및 추론 능력을 강화하는 새로운 패러다임을 제시합니다. PlanningBench 프레임워크는 단순한 벤치마크 제공을 넘어, 강화학습을 위한 고품질의 보상 신호를 생성함으로써 모델의 generalizable한 계획 수립 능력을 배양하는 핵심 도구가 됩니다. 연구 결과는 보상 결정론(reward determinacy)이 학습 안정성과 전이 성능에 매우 중요하다는 점을 학계에 시사하며, 향후 LLM이 복잡한 제약 조건 하에서 실행 가능한 솔루션을 도출하는 데 중추적인 역할을 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Agon: Competitive Cross-Model RL with Implicit Rival Grading of Reasoning
- [논문리뷰] Spectral Rewiring for Exploration, Purification, and Model Merging
- [논문리뷰] Weak-to-Strong Generalization via Direct On-Policy Distillation
- [논문리뷰] UP: Unbounded Positive Asymmetric Optimization for Breaking the Exploration-Stability Dilemma
- [논문리뷰] When LLMs Read Tables Carelessly: Measuring and Reducing Data Referencing Errors
Review 의 다른글
- 이전글 [논문리뷰] PanoWorld: A Generative Spatial World Model for Consistent Whole-House Panorama Synthesis
- 현재글 : [논문리뷰] PlanningBench: Generating Scalable and Verifiable Planning Data for Evaluating and Training Large Language Models
- 다음글 [논문리뷰] Rethinking Visual Attribution for Chest X-ray Reasoning in Large Vision Language Models
댓글