[논문리뷰] Rethinking Visual Attribution for Chest X-ray Reasoning in Large Vision Language Models
링크: 논문 PDF로 바로 열기
메타데이터
저자: Guangzhi Xiong, Qiao Jin, Sanchit Sinha, Zhiyong Lu, Aidong Zhang
1. Key Terms & Definitions (핵심 용어 및 정의)
- LVLM (Large Vision Language Models): 이미지와 텍스트를 동시에 처리하여 의료 영상 분석 및 진단 지원 등의 작업을 수행하는 거대 모델군을 지칭합니다.
- Visual Attribution: 모델의 특정 예측(prediction) 결과가 입력 이미지의 어느 부분(visual evidence)에 근거하였는지를 설명하는 기법입니다.
- Faithfulness: attribution 방법이 제공한 설명이 실제로 모델의 내부 추론 과정을 충실히 반영하는지 나타내는 지표입니다.
- UOT (Unbalanced Optimal Transport): 이미지 내 해부학적 구조(concept)를 국소화하기 위해 최적 운송 이론을 변형한 기법으로, 기준 영상과 대상 영상 간의 질량 불균형을 허용하며 매핑을 수행합니다.
- MedGround-Bench: 논문에서 제안한 CXR-VQA 기반의 인과적 평가 벤치마크로, counterfactual editing을 통해 ground-truth attribution이 검증된 샘플들로 구성됩니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 의료 분야에서 활용되는 LVLM의 예측 결과에 대한 Visual Attribution 방식이 실제로 모델의 판단 근거를 정확히 반영하는지 검증하는 데 핵심적인 한계를 해결하고자 합니다. 기존의 다양한 attribution 기법들은 모델의 추론 과정에 대한 객관적인 ground-truth 없이 적용되어 왔으며, 이는 의료 현장에서 모델에 대한 임상적 신뢰도를 저하시키는 원인이 됩니다. 저자들은 기존 기법들이 단순히 diffuse한 heatmap을 생성하거나, 모델이 실제로는 사용하지 않는 spurious cues를 강조하는 등의 문제가 있음을 지적합니다. 이를 위해 인과적 필터링을 통해 진정한 근거를 포함하는 데이터를 구축하고, 이를 바탕으로 기존 방법들의 불충분한 성능을 입증합니다 [Figure 1].
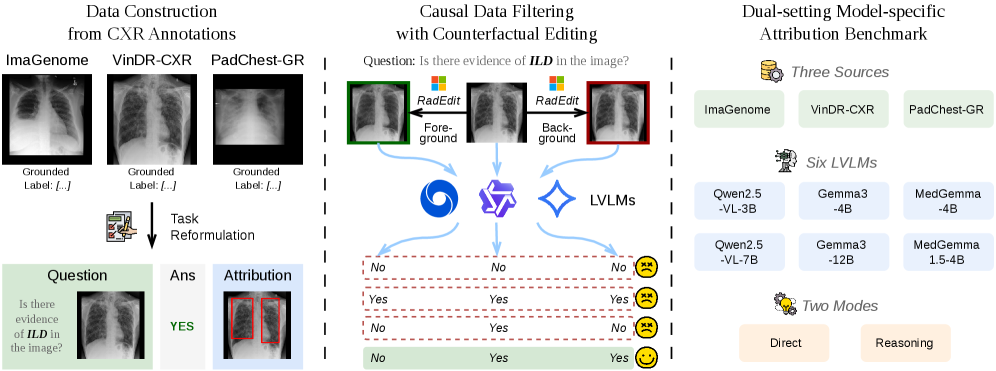
Figure 1 — MedGround-Bench 구축 프레임워크
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 해부학적 개념(anatomical concept) 기반의 인과적 attribution 프레임워크인 MedFocus를 제안합니다. MedFocus는 UOT를 사용하여 입력 CXR 내의 임상적으로 유의미한 anatomical region을 분할(segmentation)하고, MedSAM을 통해 해당 영역의 mask를 정교화합니다 [Figure 2]. 이후, 각 영역에 대한 인과적 개입(targeted intervention)을 수행하여 모델 출력의 log-probability 변화량을 측정함으로써 각 개념의 인과적 기여도를 산출합니다.
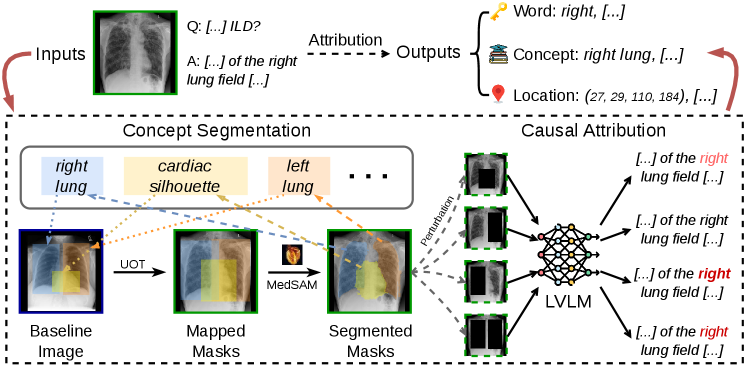
Figure 2 — MedFocus attribution 파이프라인
정량적 실험 결과, MedFocus는 제안된 MedGround-Bench 환경에서 기존의 attention-based, gradient-based, perturbation-based, prompting-based 기법들을 모두 압도하는 성능을 보였습니다 [Table 1]. 특히 MedFocus는 공간적 정확도를 나타내는 IoU와 F1 지표에서 기존 기법들 대비 현저한 우위를 점하였으며, 이는 모델의 판단이 해부학적으로 유의미한 영역과 긴밀하게 연결되어 있음을 시사합니다 [Table 1]. 또한 모델의 다단계 추론(step-by-step reasoning) 과정에서도 각 단계별로 어떤 해부학적 개념이 결정에 기여하는지 추적할 수 있어 해석 가능성을 극대화합니다 [Figure 5].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 인과적 평가 프레임워크를 통해 의료용 LVLM의 Visual Attribution 성능을 엄밀하게 평가할 수 있는 지표를 마련했습니다. 제안된 MedFocus는 단순한 pixel-level heatmap을 넘어Clinician이 직접 이해할 수 있는 해부학적 개념 기반의 해석을 제공함으로써 임상적 신뢰도를 확보하는 데 크게 기여합니다. 이 연구는 향후 고위험군 의료 AI 시스템의 안전한 도입을 위한 모델 해석성 연구의 표준이 될 것으로 기대됩니다.
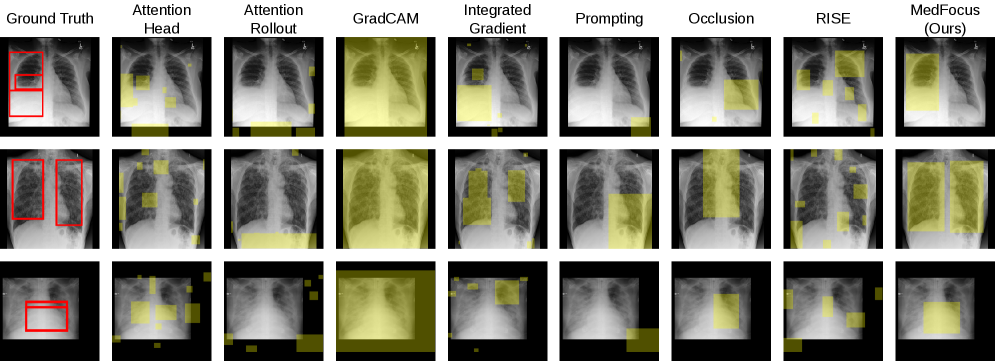
Figure 4 — 기존 방법들과의 정성적 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Transition-Aware best-of-N sampling for Longitudinal Chest X-ray Reports
- [논문리뷰] Geometry-Aware Image Flow Matching
- [논문리뷰] Chain of Evidence: Pixel-Level Visual Attribution for Iterative Retrieval-Augmented Generation
- [논문리뷰] OpenVLThinkerV2: A Generalist Multimodal Reasoning Model for Multi-domain Visual Tasks
- [논문리뷰] On Token's Dilemma: Dynamic MoE with Drift-Aware Token Assignment for Continual Learning of Large Vision Language Models
Review 의 다른글
- 이전글 [논문리뷰] PlanningBench: Generating Scalable and Verifiable Planning Data for Evaluating and Training Large Language Models
- 현재글 : [논문리뷰] Rethinking Visual Attribution for Chest X-ray Reasoning in Large Vision Language Models
- 다음글 [논문리뷰] Safety Alignment as Continual Learning: Mitigating the Alignment Tax via Orthogonal Gradient Projection
댓글