[논문리뷰] Safety Alignment as Continual Learning: Mitigating the Alignment Tax via Orthogonal Gradient Projection
링크: 논문 PDF로 바로 열기
메타데이터
저자: Guanglong Sun, Siyuan Zhang, Liyuan Wang, Jun Zhu, Hang Su, Yi Zhong
1. Key Terms & Definitions (핵심 용어 및 정의)
- Alignment Tax: 안전성 강화를 위한 post-training(SFT, DPO 등) 과정에서 모델이 기존에 보유한 일반적인 문제 해결 능력(reasoning, coding, truthfulness 등)이 저하되는 현상을 지칭합니다.
- Heterogeneous Continual Learning (HCL): 데이터 분포뿐만 아니라 최적화 목적 함수(objective)까지 단계적으로 변화하는 LLM post-training 과정을 연속 학습 문제로 재정의한 관점입니다.
- General-Capability Subspace: 모델의 핵심 능력(Helpfulness, Truthfulness 등)을 보존하는 파라미터 업데이트 방향을 정의하는 저차원(low-rank) 기울기 공간을 의미합니다.
- OGPSA (Orthogonal Gradient Projection for Safety Alignment): 안전성 향상을 위한 기울기를 일반 능력 보존 공간과 직교(orthogonal)하도록 투영하여, 능력 손실 없이 안전성만을 최적화하는 제안 방법론입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM의 안전성 정렬 과정에서 발생하는 Alignment Tax가 본질적으로는 서로 다른 최적화 목적이 충돌하며 발생하는 'catastrophic forgetting'의 일종임을 규명합니다 [Figure 1]. 기존 연구들은 Replay(데이터 재사용)나 KL penalty와 같은 소프트 제약 방식을 사용했으나, 이는 계산 비용 증가, 복잡한 하이퍼파라미터 튜닝, 능력 저하라는 한계를 가집니다. 특히, 이러한 방식들은 안전성 업데이트가 일반 능력 보존에 중요한 파라미터 방향을 간섭하는 것을 근본적으로 차단하지 못합니다. 따라서 저자들은 안전성 목적과 능력 보존 목적을 기하학적으로 분리하는 새로운 해결책을 제안합니다 [Figure 2].
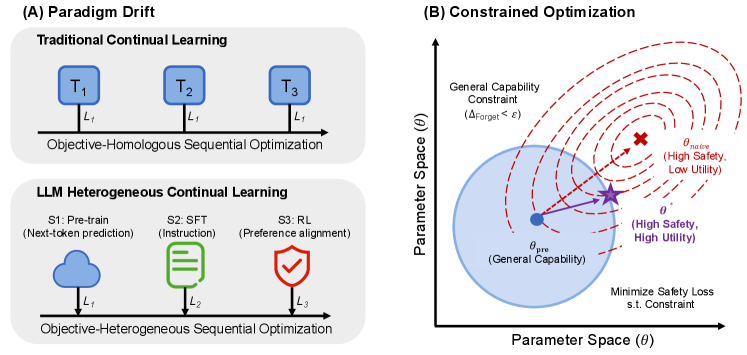
Figure 1 — 정렬 문제를 CL로 재정의
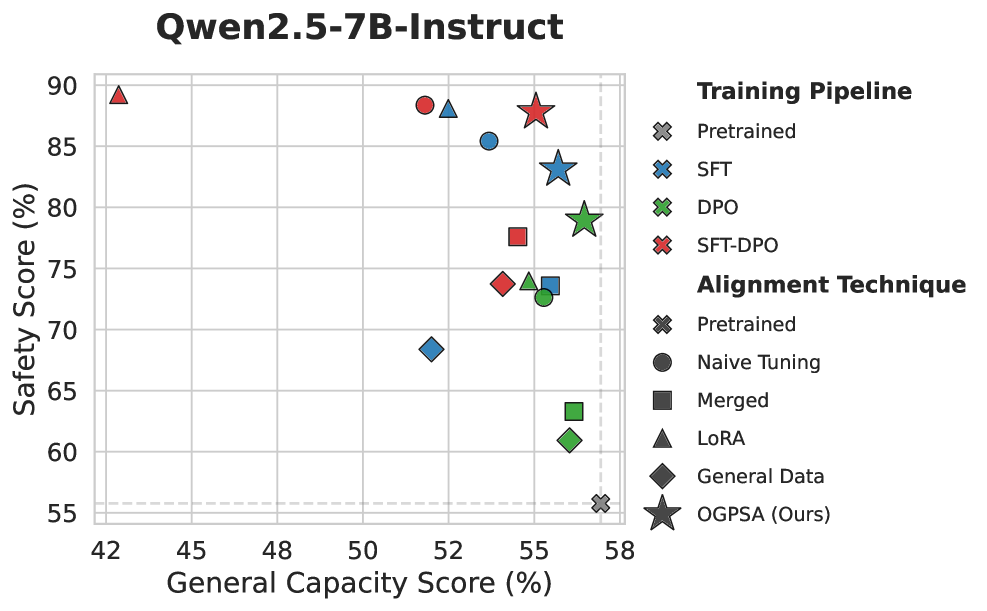
Figure 2 — 모델 성능 비교 그래프
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 안전성 기울기를 일반 능력 보존을 위한 subspace의 직교 보수(orthogonal complement)로 투영하여 업데이트하는 OGPSA를 제안합니다 [Figure 3]. 이 방법론은 일반 능력의 기울기 subspace를 estimation하고, 안전성 기울기 $g_{\text{safe}}$에서 이 subspace 성분을 제거한 투영된 기울기 $\tilde{g}_{\text{safe}}$만을 사용하여 가중치를 업데이트합니다 [Algorithm 1]. 실험 결과, Qwen2.5-7B-Instruct를 이용한 SFT-DPO 시나리오에서 OGPSA는 SimpleQA 점수를 기존 0.53%에서 3.03%로, IFEval 점수를 51.94%에서 63.96%로 회복시키며 성능 우위를 입증했습니다 [Table 1]. 또한, Llama3.1-8B-Instruct 등 다양한 모델 규모에서도 일관되게 안전성과 일반 능력 간의 Pareto frontier를 개선하였으며, 매우 적은 수의 reference 데이터만으로도 효과적인 subspace 구축이 가능하다는 점을 확인했습니다 [Table 3].
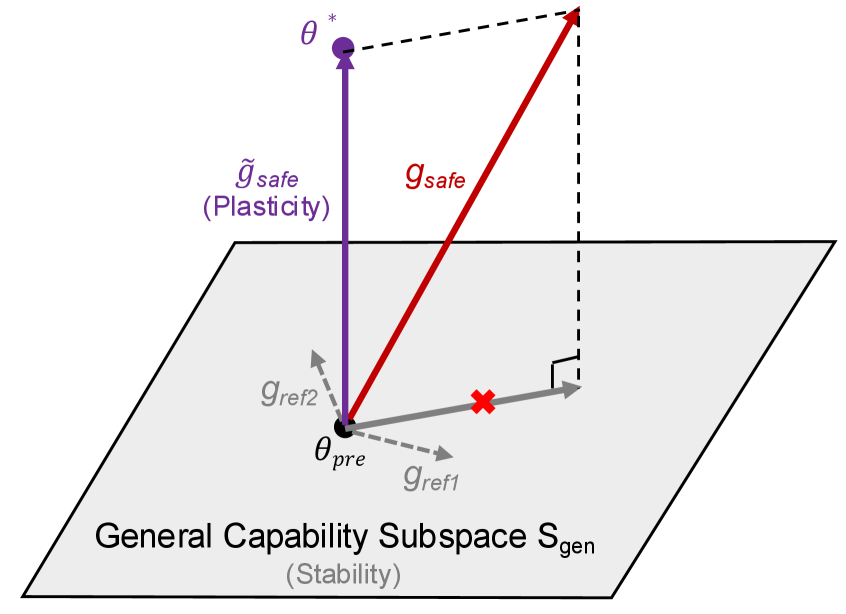
Figure 3 — OGPSA 프레임워크
4. Conclusion & Impact (결론 및 시사점)
본 연구는 안전성 정렬을 Continual Learning의 프레임워크 내에서 해석함으로써, Alignment Tax를 해결할 수 있는 기하학적이고 경량화된 최적화 기법을 제시하였습니다. 제안된 OGPSA는 복잡한 replay나 retraining 없이 기존 학습 파이프라인에 플러그 앤 플레이(plug-and-play)로 적용 가능하다는 점에서 높은 실용성을 가집니다. 이 연구는 앞으로의 LLM 개발 과정에서 안전성과 유틸리티를 동시에 보존하는 표준적인 정렬 방법론으로서 중요한 기술적 토대를 제공할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Language Models Need Sleep: Learning to Self-Modify and Consolidate Memories
- [논문리뷰] Efficient Continual Learning in Language Models via Thalamically Routed Cortical Columns
- [논문리뷰] CLARE: Continual Learning for Vision-Language-Action Models via Autonomous Adapter Routing and Expansion
- [논문리뷰] RECALL: REpresentation-aligned Catastrophic-forgetting ALLeviation via Hierarchical Model Merging
- [논문리뷰] KORE: Enhancing Knowledge Injection for Large Multimodal Models via Knowledge-Oriented Augmentations and Constraints
Review 의 다른글
- 이전글 [논문리뷰] Rethinking Visual Attribution for Chest X-ray Reasoning in Large Vision Language Models
- 현재글 : [논문리뷰] Safety Alignment as Continual Learning: Mitigating the Alignment Tax via Orthogonal Gradient Projection
- 다음글 [논문리뷰] SpecBench: Measuring Reward Hacking in Long-Horizon Coding Agents
댓글