[논문리뷰] Maestro: Reinforcement Learning to Orchestrate Hierarchical Model-Skill Ensembles
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jinyang Wu, Guocheng Zhai, Ruihan Jin, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Maestro: 다중 모달 작업을 위해 Frozen 상태의 여러 Expert 모델과 Hierarchical 스킬 라이브러리를 동적으로 구성하는 RL 기반의 Orchestration 프레임워크입니다.
- Hierarchical Model-Skill Registry: Coarse-grained Level-1 스킬과 Fine-grained Level-2 스킬로 구성된 2단계 스킬 라이브러리와 전문가 모델 풀을 포함하는 구조입니다.
- Compositional Action Space: 모델 선택(Model selection)과 스킬 호출(Skill invocation)을 결합하여 단일 추론 단계에서 최적의 연합을 수행하는 결정 구조입니다.
- GRPO (Group Relative Policy Optimization): 대규모 언어 모델의 에이전트 학습에 최적화된 학습 기법으로, 복잡하고 희소한(Sparse) 보상 구조에서 효율적으로 정책을 최적화합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대 LLM 에이전트가 특정 도메인에 강점을 가진 다양한 전문가 모델과 모듈식 스킬을 효과적으로 활용하지 못하는 Coordination Bottleneck 문제를 해결하고자 합니다. 기존 방식은 단일 거대 모델(Monolithic LLM)이나 정적인 디스패칭 로직에 의존하여, 복잡한 다중 모달 작업에 필요한 도메인별 Inductive Bias를 제대로 활용하지 못합니다. Maestro는 이를 해결하기 위해 개별 모델에 지식을 통합하는 대신, Lightweight한 오케스트레이터가 필요 시점에 맞춰 최적의 Expert 모델과 스킬 조합을 동적으로 구성하도록 설계되었습니다 [Figure 1].
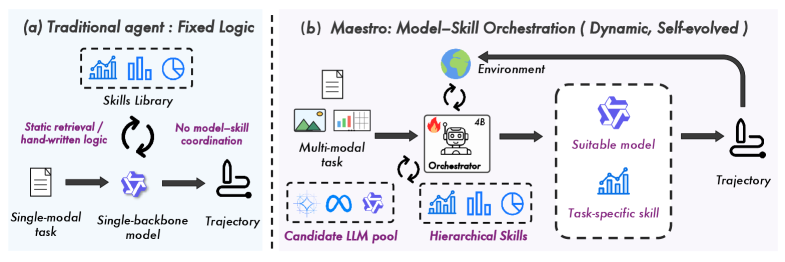
Figure 1 — 에이전트 패러다임 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 다중 모달 작업을 POMDP(Partially Observable Markov Decision Process)로 정의하고, Outcome-based RL을 통해 오케스트레이션 정책을 학습하는 Maestro 프레임워크를 제안합니다 [Figure 2]. 오케스트레이터는 내부 추론(Think)과 외부 도구 호출(Search)을 반복하며, Multi-dimensional Reward 모델을 통해 작업 성공과 프로토콜 준수 여부를 학습합니다. 실험 결과, 4B 규모의 오케스트레이터만으로도 10개 이상의 다중 모달 벤치마크에서 70.1%의 평균 정확도를 달성하여 GPT-5(69.3%) 및 Gemini-2.5-Pro(68.7%)를 능가하는 성능을 보였습니다 [Table 1]. 특히, 사전 학습 없이 새로운 전문가 모델과 스킬을 레지스트리에 추가하는 Plug-and-play 일반화 능력을 통해, 확장된 OOD(Out-of-Domain) 벤치마크에서도 59.5%의 평균 정확도를 기록하며 최신 베이스라인을 압도했습니다 [Table 2]. 이는 제안된 RL 기반 라우팅이 복잡한 작업 환경에서 추론 효율성을 극대화하면서도 도메인 확장에 유연함을 증명합니다 [Figure 3].
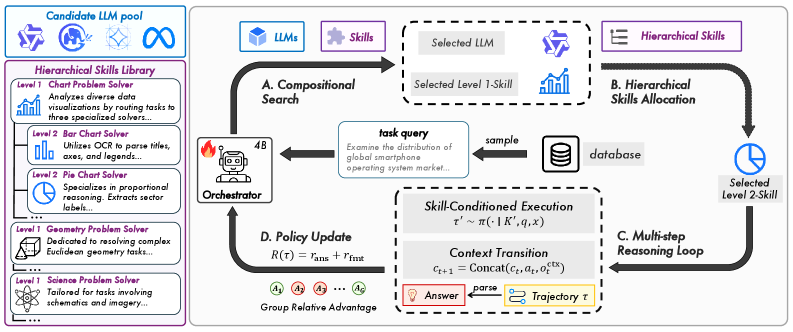
Figure 2 — Maestro 프레임워크 개요
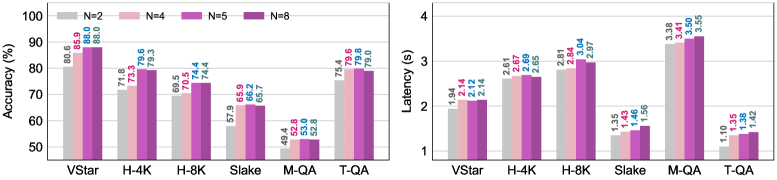
Figure 3 — 스킬 풀 크기에 따른 성능
4. Conclusion & Impact (결론 및 시사점)
본 연구는 모델 규모를 단순히 확장하는 대신, 전략적인 Orchestration을 통해 지능형 에이전트 시스템을 구축하는 것이 성능과 효율성 면에서 더 우월한 경로임을 입증했습니다. Maestro의 성공적인 결과는 대규모 에이전트 생태계에서 개방형 소스 모델들을 결합하여 frontier 모델과 대등하거나 더 뛰어난 성능을 확보할 수 있는 새로운 이정표를 제시합니다. 향후 연구에서는 스스로 진화하는 Skill Registry와 실시간 정책 적응(Online policy adaptation)을 통해 더 광범위하고 개방적인 도메인으로 확장이 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Gen-Searcher: Reinforcing Agentic Search for Image Generation
- [논문리뷰] The Era of Agentic Organization: Learning to Organize with Language Models
- [논문리뷰] Seeing, Listening, Remembering, and Reasoning: A Multimodal Agent with Long-Term Memory
- [논문리뷰] Understanding Reasoning from Pretraining to Post-Training
- [논문리뷰] On-Policy Delta Distillation
Review 의 다른글
- 이전글 [논문리뷰] Lean Refactor: Multi-Objective Controllable Proof Optimization via Agentic Strategy Search
- 현재글 : [논문리뷰] Maestro: Reinforcement Learning to Orchestrate Hierarchical Model-Skill Ensembles
- 다음글 [논문리뷰] Minimalist Visual Inertial Odometry
댓글