[논문리뷰] Minimalist Visual Inertial Odometry
링크: 논문 PDF로 바로 열기
저자: Francesco Pasti, Jeremy Klotz, Nicola Bellotto, Shree K. Nayar
1. Key Terms & Definitions (핵심 용어 및 정의)
- Visual-Inertial Odometry (VIO): 카메라의 시각 정보와 IMU (Inertial Measurement Unit)의 측정값을 융합하여 로봇의 궤적을 계산하는 내비게이션 기술입니다.
- Minimalist Vision: 비전 태스크를 해결하는 데 필요한 최소한의 시각 정보를 탐색하는 접근 방식으로, 고도로 최적화된 센서나 프로세싱을 활용합니다.
- Gabor Masks: 가우시안 엔벨롭으로 변조된 사인파 형태의 가버 함수로 설계된 광학 마스크로, 지면 텍스처에서 특정 공간 주파수를 분리하는 데 사용됩니다.
- Temporal Convolutional Network (TCN): 시간 순서 데이터를 처리하는 데 사용되는 신경망 아키텍처로, 본 논문에서는 포토다이오드 신호로부터 속도를 디코딩하는 데 활용됩니다.
- Planar Odometry: 로봇의 2차원 평면 상 위치와 자세(궤적)를 추정하는 기술입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 자원 제약적인 로봇 플랫폼에서 기존 VIO (Visual-Inertial Odometry) 시스템의 높은 전력 소모 및 계산 요구사항이 가지는 한계점을 해결하고자 합니다. 전통적인 VIO는 고해상도 카메라 이미지를 활용하기 때문에, 모바일 로봇 내비게이션에 필수적임에도 불구하고 전력 소비가 픽셀 수에 비례하여 증가하는 문제가 있습니다. 또한, 기존의 효율적인 광학 흐름(optical flow) 센서는 디지털화 및 처리 요구사항이 높고, 센서와 지면 간의 고도(standoff distance) 변화에 매우 민감하여 불균일한 지형에서의 견고성이 부족합니다. 이벤트 카메라(event cameras)는 데이터 속도를 줄이지만, 여전히 움직임 추출을 위해 씬(scene)의 조밀한 공간 샘플링이 필요합니다. 따라서, 저자들은 기존 연구들의 한계를 극복하고 최소한의 센싱 자원으로 견고하고 효율적인 평면 오도메트리를 달성할 새로운 접근 방식의 필요성을 제기합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 단 네 개의 하향식 포토다이오드와 IMU를 사용하여 견고한 평면 오도메트리를 제공하는 최소주의 접근 방식을 제안합니다 [cite: 1, Figure 1]. 저자들은 광학 가버 마스크(optical Gabor masks)를 통해 지면 텍스처에서 특정 공간 주파수를 분리하여 로봇의 선형 속도를 인코딩하는 시간 신호를 생성합니다. 특히, 두 개의 직교(quadrature) 가버 마스크(cosine 및 sine Gabor 함수)를 사용하여 운동 방향의 모호성을 해결하며, 이 마스크들은 물리적으로는 네 개의 비음수(non-negative) 마스크 쌍으로 구현됩니다 [cite: 1, Figure 3]. 제안하는 시스템은 물리적으로 기반을 둔 시뮬레이터를 활용하여 가버 마스크 파라미터(공간 주파수 ξ0, 시그마 σ, 진폭 α)와 시간적 컨볼루션 네트워크(TCN) 디코더를 End-to-End로 공동 최적화하는 학습 프레임워크를 사용합니다 [cite: 1, Figure 4]. TCN은 1초 길이의 입력 신호 윈도우를 처리하여 선형 속도를 예측하며, 지면 텍스처 변화에 따른 신호 대 잡음비(SNR) 변동을 완화하기 위해 어텐션 풀링(attention pooling) 레이어를 포함합니다.
실험 결과, TCN 파라미터와 가버 마스크 파라미터를 공동으로 최적화한 Learned Gabor 방식이 고정된 파라미터의 Fixed Gabor 마스크 대비 시뮬레이션 데이터에서 속도 추정 정확도를 크게 향상시켰습니다. 특히, RMSE는 0.054 m/s, MAE는 0.034 m/s로, Fixed Gabor 대비 RMSE에서 29%, MAE에서 35% 감소를 보였습니다 [cite: 1, Table I]. 또한, ±25%의 균일한 높이 무작위화(height randomization)를 통해 훈련된 모델은 높이 변화에 대한 견고성을 확보하며, 속도 RMSE가 0.048 m/s를 달성했습니다 [cite: 1, Table II]. 실제 환경 테스트(총 920m, 87분)에서 4-Pixel + IMU 시스템(1 kHz 업데이트 속도)은 실내에서 평균 ATE (Absolute Trajectory Error) 0.28 m 및 평균 Endpoint Drift 0.60%를, 실외에서는 ATE 0.42 m 및 Drift 0.62%를 기록했습니다 [cite: 1, Table III, Figure 6]. 이는 기존의 Wheel Encoders + IMU Baseline이 실내에서 ATE 0.75 m 및 Drift 1.62%를, 실외에서 ATE 0.74 m 및 Drift 1.37%를 기록한 것과 비교하여 현저히 우수한 성능입니다 [cite: 1, Table III]. 제안된 최소주의 센서는 기존 카메라 센서 대비 두 자릿수 낮은 2.5 mW의 전력을 소모합니다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 단 네 개의 마스크된 검출기로 구성된 센서를 활용한 최소주의 평면 오도메트리 접근 방식을 성공적으로 제시합니다. 이론적 분석을 통해 가버 마스크가 속도 추정에 이상적임을 보였고, 맞춤형 시뮬레이터를 통해 가버 마스크 파라미터와 TCN 네트워크를 공동으로 최적화했습니다. 이 연구는 자원 제약적인 로봇 플랫폼에서 정확하고 효율적인 평면 오도메트리를 위한 최소주의 센싱이 실행 가능한 솔루션임을 입증했습니다. 시뮬레이션 데이터만으로 최적화되었음에도 불구하고, 프로토타입 센서는 다양한 실내외 환경에서 견고한 성능을 보여 실제 환경으로의 일반화 가능성을 확인시켰습니다. 이러한 결과는 초저전력 임베디드 오도메트리 구현 및 드론과 같은 다른 플랫폼으로의 확장은 물론, 지형 분류 및 충돌 회피와 같은 다른 로봇 공학 태스크에 최소주의 센싱을 활용할 수 있는 잠재력을 시사합니다.
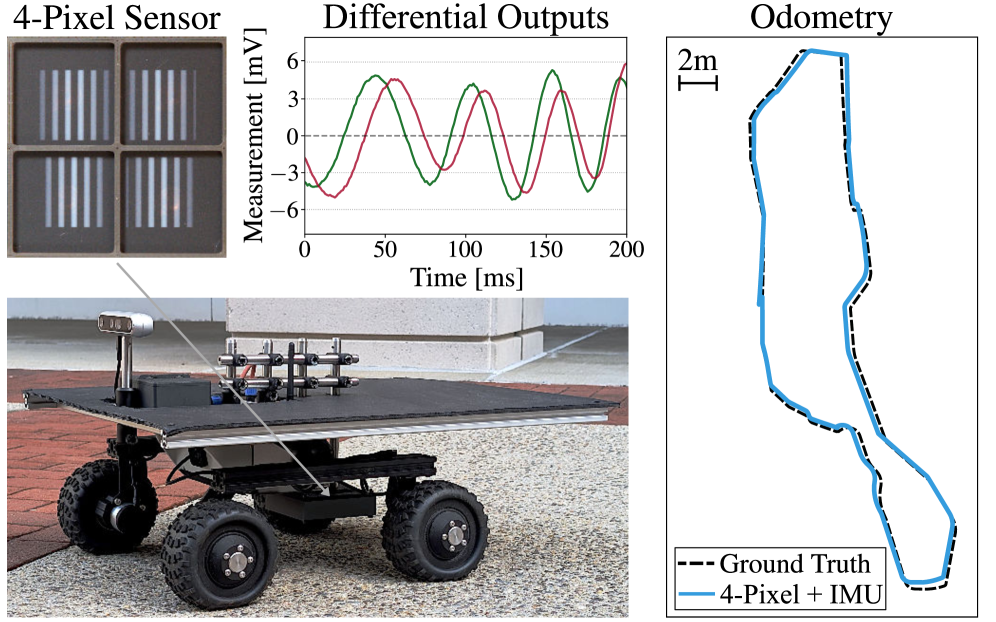
Figure 1 — 최소주의 오도메트리 시스템

Figure 4 — 학습 프레임워크 개요

Figure 6 — 실내외 실험 궤적
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Revisiting Articulated Parts Perception in Robot Manipulation
- [논문리뷰] AffordBot: 3D Fine-grained Embodied Reasoning via Multimodal Large Language Models
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] xHC: Expanded Hyper-Connections
- [논문리뷰] Xiaomi-Robotics-1: Scaling Vision-Language-Action Models with over 100K Hours of Real-World Trajectories
Review 의 다른글
- 이전글 [논문리뷰] Maestro: Reinforcement Learning to Orchestrate Hierarchical Model-Skill Ensembles
- 현재글 : [논문리뷰] Minimalist Visual Inertial Odometry
- 다음글 [논문리뷰] More Context, Larger Models, or Moral Knowledge? A Systematic Study of Schwartz Value Detection in Political Texts
댓글