[논문리뷰] Same Architecture, Different Capacity: Optimizer-Induced Spectral Scaling Laws
링크: 논문 PDF로 바로 열기
메타데이터
저자: Nandan Kumar Jha, Brandon Reagen
1. Key Terms & Definitions (핵심 용어 및 정의)
- Spectral Scaling Laws: 모델의 FFN(Feed-Forward Network) 폭(width) 확장이 잠재 공간(latent space)의 유효 차원과 어떻게 변화하는지 정량화한 법칙입니다.
- Soft/Hard Spectral Rank: 행렬의 고유값 분포를 통해 모델의 유효 용량을 측정하는 지표입니다.
Soft rank는 정보 엔트로피 기반의 분포를,Hard rank는 참여율(participation ratio) 기반의 지배적 고유값 집중도를 측정합니다. - FFN Width: Transformer 모델에서 연산 용량의 핵심을 담당하는 feed-forward 레이어의 중간층 차원을 의미합니다.
- Rényi-family Effective Rank: 고유값 스펙트럼의 집중도(concentration)를 다양한 관점에서 평가하기 위해 Rényi 엔트로피를 활용한 계층적 용량 측정 프레임워크입니다.
- Optimizer Geometry: 특정 최적화 알고리즘(AdamW, Muon 등)이 가중치 업데이트 과정에서 모델 표현(representation)에 부여하는 고유한 구조적 특성을 뜻합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 스케일링 법칙이 최적화기(optimizer)를 고정된 요소로 간주하여, 모델 내부 표현의 구조적 차이를 간과한다는 점을 문제로 지적합니다. 저자들은 동일한 아키텍처와 컴퓨팅 자원을 사용하더라도 최적화기 선택에 따라 FFN 폭이 실제 유효 용량으로 전환되는 효율이 크게 달라질 수 있음을 밝힙니다 [Figure 1]. 특히, Validation Loss가 유사하더라도 내부 표현 기하학(representation geometry)이 구조적으로 다를 수 있다는 점을 규명하며, 이를 분석하기 위한 새로운 Spectral Scaling 프레임워크의 필요성을 강조합니다.
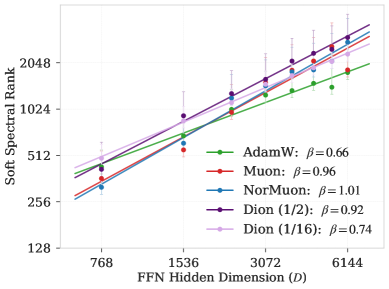
Figure 1 — 최적화기별 Spectral Scaling 지수 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 FFN의 입출력 표현에 대한 공분산 행렬의 고유값 스펙트럼을 분석하여, AdamW와 Muon 등 다양한 최적화기의 Spectral Scaling 지표를 측정하는 방법을 제안합니다. 실험 결과, AdamW는 TAIL 토큰 영역에서 낮은 하드 랭크(hard-rank) 스케일링 지수($\beta \approx 0.44$)를 보이는 반면, Muon은 선형에 가까운 스케일링($\beta \approx 1.02$)을 달성함을 확인했습니다 [Figure 2]. 또한, AdamW는 extended training을 통해 perplexity를 최적화기 간 비슷하게 맞추더라도, 내부적인 Hard-rank 스케일링 지수는 오히려 퇴화하거나 정체되는 현상을 발견했습니다 [Figure 3]. 이는 최적화기 선택이 단순한 수렴 속도의 문제를 넘어, 모델이 추가된 파라미터를 어떻게 유용한 표현으로 활용하는지를 결정하는 핵심 설계 요소임을 입증합니다 [Table 2].
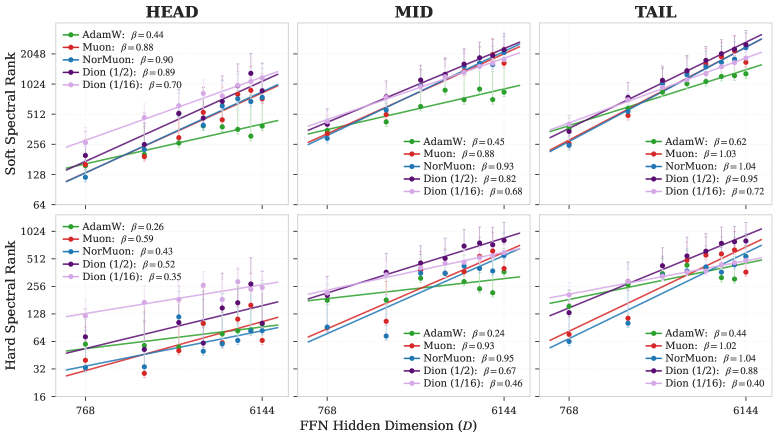
Figure 2 — 토큰 빈도별 최적화기 스케일링 차이
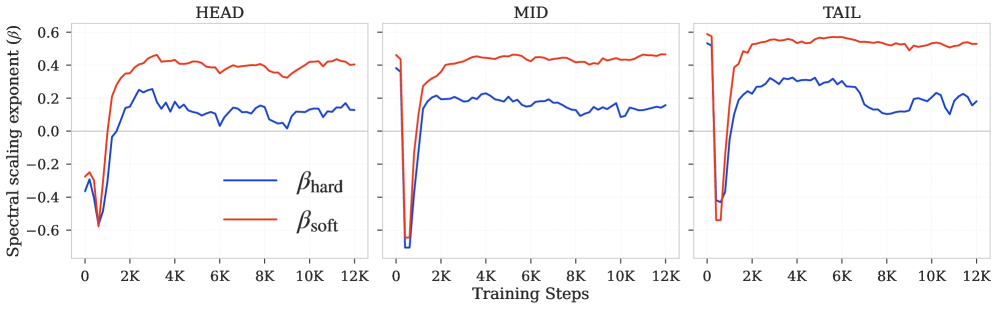
Figure 3 — 장기 학습 시 Hard-rank 퇴화 현상
4. Conclusion & Impact (결론 및 시사점)
본 논문은 최적화기를 모델 설계의 '일등석(first-class)' 축으로 격상시켜야 한다는 결론을 도출합니다. 연구 결과는 아키텍처 변경(Attention rank 조정, RoPE 제거 등)이 가져오는 효과가 최적화기의 기하학적 특성에 의해 좌우되거나 가려질 수 있음을 시사합니다. 따라서 향후 LLM 개발 시 최적화기와 아키텍처를 독립적으로 선택하는 것이 아닌, 표현의 유효 용량 효율을 극대화하는 'Optimizer–Architecture Co-design' 접근법이 필수적임을 학계에 제언합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] xHC: Expanded Hyper-Connections
- [논문리뷰] Xiaomi-Robotics-1: Scaling Vision-Language-Action Models with over 100K Hours of Real-World Trajectories
- [논문리뷰] When Does Muon Help Agentic Reinforcement Learning?
- [논문리뷰] VideoRAE: Taming Video Foundation Models for Generative Modeling via Representation Autoencoders
Review 의 다른글
- 이전글 [논문리뷰] Q-ARVD: Quantizing Autoregressive Video Diffusion Models
- 현재글 : [논문리뷰] Same Architecture, Different Capacity: Optimizer-Induced Spectral Scaling Laws
- 다음글 [논문리뷰] SceneAligner: 3D-Grounded Floorplan Localization in the Wild
댓글