[논문리뷰] SceneAligner: 3D-Grounded Floorplan Localization in the Wild
링크: 논문 PDF로 바로 열기
메타데이터
저자: Junhyeong Cho, Ruojin Cai, Hadar Averbuch-Elor, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Density Map: 3D 포인트 클라우드를 수평면(x-z plane)에 orthographic projection하여 생성한 2D 표현으로, floorplan과 정렬을 위한 중간 매개체(proxy)로 사용됨.
- Cross-modal Correspondence: 서로 다른 모달리티(자연 이미지 기반 3D 재구성 결과인 Density Map과 architectural floorplan) 사이의 대응 관계를 추정하는 기술.
- LoRA (Low-Rank Adaptation): 대규모 사전 학습된 모델(예: DINOv3)의 가중치를 고정한 채, 적은 수의 파라미터만을 최적화하여 특정 도메인에 효율적으로 적응시키는 기법.
- Similarity Transform (𝐌): 두 이미지 간의 scale, rotation, translation을 포함하는 2D 변환 행렬로, 본 논문에서는 Density Map을 floorplan에 정렬하기 위해 사용됨.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 대규모 환경 및 상업용 건물의 비정형(in-the-wild) 이미지 컬렉션 내에서 카메라 관측치를 2D floorplan에 로컬라이제이션하는 문제를 다룬다. 기존 연구들은 제어된 환경에서 정밀한 벡터 기반(vectorized) floorplan을 가정하여 로컬라이제이션을 수행했으나, 실제 환경에서는 rasterized 혹은 심볼 형태의 floorplan이 주를 이루어 기존 방식의 적용이 어렵다. 또한, 기존의 exhaustive pose search 방식은 계산 복잡도가 높고 유연성이 떨어지는 한계가 있다. 저자들은 이러한 제약을 극복하기 위해, unconstrained 사진으로부터 3D 장면을 재구성하고 이를 floorplan과 정렬하는 새로운 접근 방식을 제안한다 [Figure 1].

Figure 1 — SceneAligner의 전체 로컬라이제이션 흐름
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 SceneAligner를 제안하며, 이는 gravity-aligned 3D 재구성으로부터 Density Map을 추출하고, 이를 foundation model 기반의 feature matching을 통해 floorplan과 정렬하는 파이프라인이다. 구체적으로 DINOv3를 shared encoder로 활용하고, LoRA 레이어를 주입하여 Density Map과 floorplan 간의 appearance gap을 해소하는 세밀한 fine-tuning 기법을 도입했다 [Figure 2, Figure 3]. 정량적 실험 결과, SceneAligner는 C3 데이터셋에서 기존 모델인 C3Po 대비 combined angular-positional recall에서 약 123% 향상된 성능을 기록했으며, RMSE 오차는 129% 개선되었다 [Table 1, Table 2]. 특히, 단일 이미지(sparse-view) 설정에서도 강력한 로컬라이제이션 성능을 발휘하며, 기존의 정교한 floorplan 전처리가 필요한 UnLoc과 같은 최신 기법들을 Structured3D 데이터셋에서 능가하는 결과를 보여주었다 [Table 3].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 SceneAligner를 통해 3D 재구성 모델의 기하학적 사전 지식과 2D foundation model의 표현 능력을 결합하여 비정형 환경에서의 floorplan 로컬라이제이션을 성공적으로 구현하였다. 이 연구는 기존의 복잡한 pose space 검색 방식에서 벗어나, 3D 장면 이해와 지도 정렬을 통합하는 새로운 패러다임을 제시하였다. 향후 본 기술은 증강 현실(AR), 로봇 내비게이션, 그리고 실내-외 장면의 통합 정렬 등 다양한 공간 지능(spatial intelligence) 응용 분야에서 핵심적인 역할을 할 것으로 기대된다.
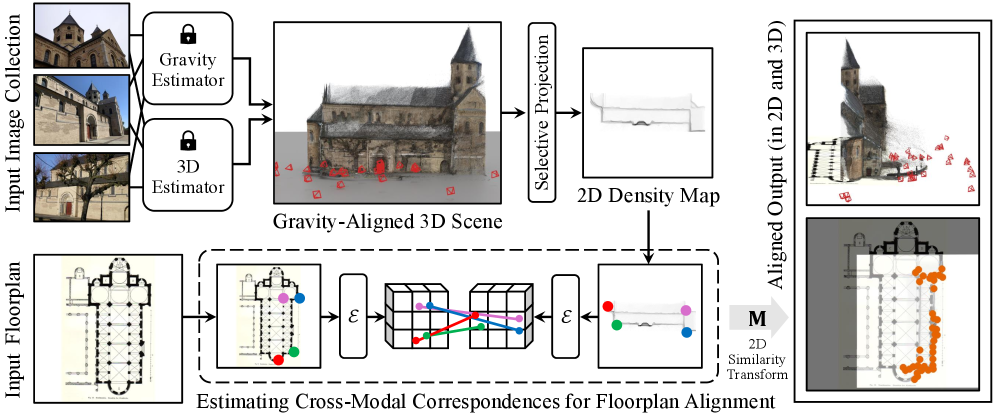
Figure 2 — 제안 모델의 전체 아키텍처 및 파이프라인

Figure 3 — Foundation model 기반 정렬 결과 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] From RGB Generation to Dense Field Readout: Pixel-Space Dense Prediction with Text-to-Image Models
- [논문리뷰] Vision as Unified Multimodal Generation
- [논문리뷰] Program-as-Weights: A Programming Paradigm for Fuzzy Functions
- [논문리뷰] Discrete Diffusion Language Models for Interactive Radiology Report Drafting
- [논문리뷰] DreamForge-World 0.1 Preview: A Low-Compute Real-Time Controllable World Model
Review 의 다른글
- 이전글 [논문리뷰] Same Architecture, Different Capacity: Optimizer-Induced Spectral Scaling Laws
- 현재글 : [논문리뷰] SceneAligner: 3D-Grounded Floorplan Localization in the Wild
- 다음글 [논문리뷰] Segment Anything with Motion, Geometry, and Semantic Adaptation for Complex Nonlinear Visual Object Tracking
댓글