[논문리뷰] Segment Anything with Motion, Geometry, and Semantic Adaptation for Complex Nonlinear Visual Object Tracking
링크: 논문 PDF로 바로 열기
저자: Deyi Zhu, Yuji Wang, Yong Liu, Yansong Tang, Bingyao Yu, Jiwen Lu, Jie Zhou
1. Key Terms & Definitions (핵심 용어 및 정의)
- SAM 2: 다양한 이미지 및 비디오 세그멘테이션 작업에 대해 강력한 비디오 이해 능력을 갖춘 Foundation Model로, 본 논문에서는 VOT 태스크를 위한 백본으로 활용됩니다.
- Nonlinear Motion: 속도 변화, 방향 전환, 카메라 움직임, 형상 변화 등 일정한 속도 모델로 설명하기 어려운 복잡한 대상의 움직임 패턴을 지칭합니다.
- MP (Motion Predictor): 고차 Markov 모델을 기반으로 비선형 대상의 움직임을 예측하고, mask selection 및 memory filtering을 가이드하는 경량 모듈입니다.
- EDRM (Error Detection-Recovery Module): 추적 중 발생하는 오류를 기하학적 및 의미론적 큐로 탐지하고 복구하여 오차 누적을 방지하는 모듈입니다.
- TAMB (Target-Aware Memory Bank): 대상의 visibility, 마스크 품질, 움직임 정보를 통합하여 신뢰할 수 있는 메모리 프레임을 선별적으로 관리하는 장치입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 VOT 방식들이 task-specific supervised training에 의존하여 unseen 환경에 대한 일반화 능력이 제한적이라는 점을 지적합니다. 최근 Foundation Model인 SAM 2가 등장했으나, SAM 2를 직접 VOT에 적용할 경우 대상의 복잡한 움직임 역학이나 기하학적/의미론적 일관성을 명시적으로 모델링하지 못해 성능이 저하되는 문제가 발생합니다 [Figure 1]. 특히, 실제 시나리오에서 빈번하게 발생하는 Nonlinear Motion 패턴은 기존의 constant-velocity 모델인 Kalman Filter 등으로는 적절히 대응하기 어렵습니다. 따라서 저자들은 SAM 2의 강점인 사전 학습된 비디오 이해 능력에 명시적인 추적 지향 모델링(motion, geometry, semantic cues)을 결합한 새로운 프레임워크인 SAMOSA를 제안합니다.
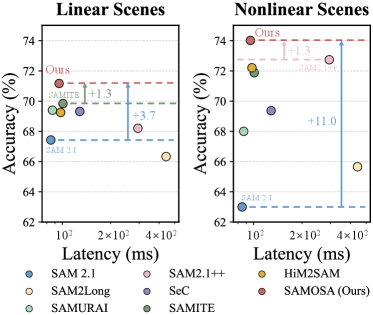
Figure 1 — Anti-UAV300 성능 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 SAMOSA를 통해 복잡한 비선형 VOT 시나리오를 해결하기 위해 Motion, Geometry, Semantic 큐를 통합적으로 활용하는 프레임워크를 제안합니다 [Figure 3]. MP는 고차 Markov 가정을 도입하여 비선형 움직임을 예측하며, 이는 추적 시 Mask Selection을 유도합니다. EDRM은 대상의 기하학적/의미론적 일관성을 모니터링하여 추적 실패를 탐지하고 복구하는 역할을 수행합니다. 또한 TAMB는 mask quality와 motion 정보를 반영하여 가장 대표성 있는 프레임을 메모리에 저장함으로써 장기적인 안정성을 확보합니다. 실험 결과, SAMOSA는 LaSOT_ext, TrackingNet 등 일반적인 벤치마크뿐만 아니라 복잡한 움직임이 특징인 Anti-UAV 시리즈 벤치마크에서도 기존의 최첨단 SAM 2 기반 접근 방식들보다 일관되게 높은 성능을 기록했습니다 [Table I, Table II]. 특히 Anti-UAV300 RGB 데이터셋에서 기존 대비 AUC 지표를 유의미하게 개선하며, 추론 과정에서의 latency 오버헤드 또한 최소화하였습니다 [Figure 1, Table III].
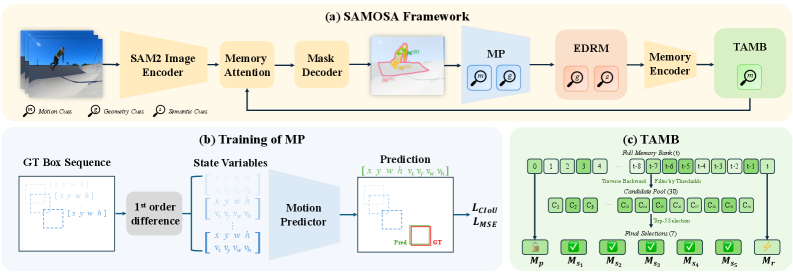
Figure 3 — SAMOSA 전체 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 연구는 SAM 2의 잠재력을 극대화하여 복잡한 비선형 환경에서도 안정적인 성능을 발휘하는 트래커인 SAMOSA를 성공적으로 구축하였습니다. 이 연구는 비전 파운데이션 모델에 명시적인 모션 및 기하학적 제약 조건을 플러그인 형태로 결합하는 것이 추적 정확도 향상에 결정적임을 입증했습니다. SAMOSA는 기존 모델과 비교하여 더 우수한 일반화 성능과 효율성을 제공하므로, 향후 자율 주행이나 무인기 추적과 같은 고난도 실시간 추적 분야에 실질적인 기여를 할 것으로 기대됩니다. 또한 본 프레임워크는 멀티 객체 추적이나 3D 세그멘테이션 등 더 넓은 도메인으로의 확장 가능성을 제시합니다.
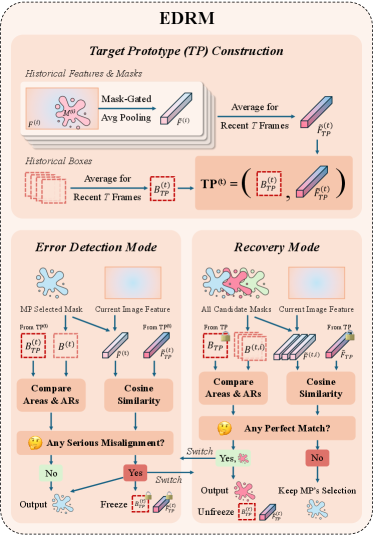
Figure 4 — EDRM 모듈 구성
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Video Generation Models are General-Purpose Vision Learners
- [논문리뷰] Scalable Visual Pretraining for Language Intelligence
- [논문리뷰] Vision as Unified Multimodal Generation
- [논문리뷰] PixCon: Clean-Positive Contrastive Learning for Foundation-Model Semi-Supervised Segmentation
- [논문리뷰] One Scene, Two Depths: Probing Geometric Ambiguity in Monocular Foundation Models
Review 의 다른글
- 이전글 [논문리뷰] SceneAligner: 3D-Grounded Floorplan Localization in the Wild
- 현재글 : [논문리뷰] Segment Anything with Motion, Geometry, and Semantic Adaptation for Complex Nonlinear Visual Object Tracking
- 다음글 [논문리뷰] Sensor2Sensor: Cross-Embodiment Sensor Conversion for Autonomous Driving
댓글