[논문리뷰] Sensor2Sensor: Cross-Embodiment Sensor Conversion for Autonomous Driving
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jiahao Wang, Bo Sun, Yijing Bai, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Sensor2Sensor: In-the-wild monocular dashcam 영상을 고도의 다중 모달(multi-modal) AV 센서 로그로 변환하는 생성 모델 프레임워크입니다.
- 4DGS (4D Gaussian Splatting): 3D Gaussian Splatting의 동적 버전을 활용하여 기존 AV 로그로부터 고품질 4D 장면을 재구성하고, 가상의 dashcam 뷰를 렌더링하는 데이터 생성 도구입니다.
- Cross-Sensor Attention: 다중 카메라와 LiDAR 간의 공간적 일관성을 강화하기 위해, 서로 다른 센서 모달리티의 토큰들 사이에서 정보를 교환하는 신경망 모듈입니다.
- DAgger (Dataset Aggregation): 모델이 자기 자신의 출력값에 의존할 때 발생하는 오차 누적(drifting) 문제를 완화하기 위해, 훈련 과정에 모델의 생성 결과를 반복적으로 포함하는 학습 알고리즘입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 자율주행 시스템(ADS) 검증에 필수적인 long-tail 데이터 확보의 어려움을 해결하기 위해 제안되었다. 기존의 fleet 데이터는 고품질이지만 규모와 다양성에 한계가 있으며, 인터넷상의 in-the-wild 비디오는 풍부한 다양성을 제공하지만 ADS가 요구하는 multi-modal sensor 형식과 불일치하는 embodiment gap 문제가 존재한다. 기존의 unpaired domain translation 방식은 강력한 기하학적 사전 지식(geometric prior)이 부족하여 복잡한 자율주행 장면을 temporally-consistent하게 생성하는 데 한계가 있다. 따라서 저자들은 실제 도로 영상의 현실성을 유지하면서도 타겟 AV 환경의 정밀한 다중 모달 포맷으로 변환하는 새로운 프레임워크를 개발하였다 [Figure 2].
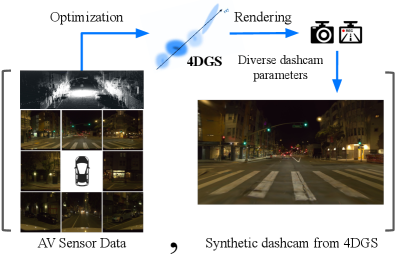
Figure 2 — 4DGS 기반 합성 데이터 생성 파이프라인
3. Method & Key Results (제안 방법론 및 핵심 결과)
Sensor2Sensor는 4DGS 기반의 합성 데이터 생성 파이프라인과 다중 모달 확산(diffusion) 모델로 구성된다. 먼저 4DGS를 통해 AV 로그의 장면을 재구성하고, 임의의 dashcam 뷰를 렌더링하여 Pair-wise training corpus를 구축한다. 이후, 이 데이터를 바탕으로 단일 입력 카메라 영상으로부터 8개의 다중 뷰 이미지와 LiDAR point cloud를 동시 생성하는 조건부 확산 모델을 학습시킨다. 이때 모델 내부에 Cross-Sensor Attention 모듈을 삽입하여 modality-specific U-Net branch 간의 일관성을 강화한다 [Figure 3]. 또한, DAgger 학습을 통해 비디오 생성의 시간적 안정성을 확보하였다 [Figure 5]. 실험 결과, 본 모델은 기존 Reconstruction 기반 모델인 VGGT나 $\pi^3$ 대비 월등한 FID(6.47) 및 FVD(278.12) 수치를 기록하며 SOTA 성능을 입증하였다 [Table 1, Table 2]. 특히, In-the-wild 데이터에 대한 human evaluation에서 85% 이상의 사용자가 제안 모델의 생성 결과물을 선호하였다 [Table 4].
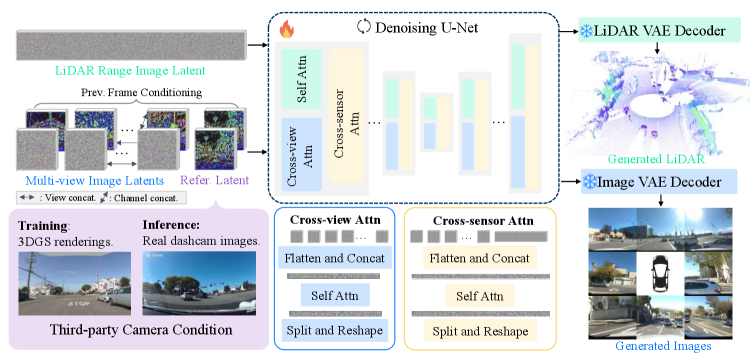
Figure 3 — 다중 모달 센서 생성 모델 아키텍처

Figure 5 — DAgger를 이용한 시간적 비디오 안정화 비교
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Sensor2Sensor를 통해 풍부하지만 활용이 어려웠던 in-the-wild 영상 데이터를 고품질의 AV 시뮬레이션용 자산으로 전환하는 가능성을 제시하였다. 제안된 모델은 단순히 시각적 생성을 넘어 LiDAR와 카메라 간의 다중 모달 일관성을 성공적으로 확보함으로써 실제 자율주행 검증에 활용 가능한 수준의 정밀도를 구현하였다. 이 연구는 데이터 부족으로 인한 긴 꼬리(long-tail) 시나리오 대응의 한계를 극복하고, 더욱 견고하고 안전한 자율주행 시스템을 구축하는 데 중요한 기술적 토대를 제공할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Learning A Unified Risk Map for Autonomous Driving in Partially Observable Environments
- [논문리뷰] VideoRAE: Taming Video Foundation Models for Generative Modeling via Representation Autoencoders
- [논문리뷰] PanoWorld: Real-World Panoramic Generation
- [논문리뷰] Flow-ERD: Agent-type Aware Flow Matching with Entropy-Regularized Distillation for Diverse Traffic Simulation
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
Review 의 다른글
- 이전글 [논문리뷰] Segment Anything with Motion, Geometry, and Semantic Adaptation for Complex Nonlinear Visual Object Tracking
- 현재글 : [논문리뷰] Sensor2Sensor: Cross-Embodiment Sensor Conversion for Autonomous Driving
- 다음글 [논문리뷰] SpaceDG: Benchmarking Spatial Intelligence under Visual Degradation
댓글