[논문리뷰] Unsupervised Process Reward Models
링크: 논문 PDF로 바로 열기
저자: Artyom Gadetsky, Maxim Kodryan, Siba Smarak Panigrahi, Hang Guo, Maria Brbic
1. Key Terms & Definitions (핵심 용어 및 정의)
- uPRM (Unsupervised Process Reward Models): 인간의 단계별 주석(step-level annotation)이나 정답 확인 없이, LLM의 next-token 확률을 기반으로 추론 과정의 타당성을 평가하고 학습하는 모델입니다.
- ProcessBench: 수학적 추론 과정에서 단계별 오류를 탐지하는 능력을 평가하기 위해 설계된 벤치마크 데이터셋입니다.
- Test-Time Scaling (TTS): 추론 시점에 계산 자원을 추가로 할당하여 생성된 다수의 후보 답변 중 최적의 결과를 선택하거나 추론 경로를 최적화하는 기법입니다.
- Reward Hacking (RH): 보상 모델이 의도하지 않은 비논리적 패턴(예: 빈 답변 또는 짧은 답변)을 학습하여, 실제 추론 품질 향상 없이 보상 점수만 최대화하는 현상입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 PRM 학습에 필수적인 인간 전문가의 단계별 주석 데이터가 갖는 높은 비용과 확장성 문제를 해결하고자 합니다. 기존의 Outcome Reward Models (ORMs)는 추론 결과의 정답 여부만을 평가하여 긴 추론 과정에서 발생하는 논리적 오류를 효과적으로 잡아내지 못하며, 반대로 기존 PRM들은 대규모의 수작업 라벨링이나 외부 검증자에 의존해야 하는 한계가 있습니다. 저자들은 이러한 제약에서 벗어나, 인간의 개입 없이도 LLM 스스로의 평가 능력을 활용하여 정밀한 과정 보상(process reward)을 생성할 수 있는 완전 비지도 학습 방법을 제안합니다 [Figure 1].
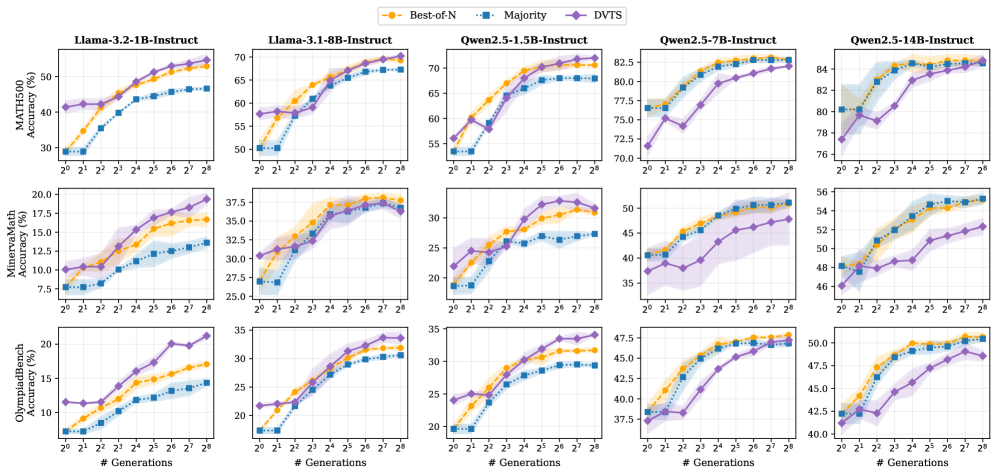
Figure 1 — TTS 성능 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 LLM의 next-token 확률을 사용하여 추론 단계의 타당성을 평가하는 Scoring Function을 정의하고, 이를 통해 uPRM을 최적화하는 새로운 프레임워크를 제안합니다. 저자들은 여러 추론 궤적(trajectories)을 동시에 평가하는 'Joint Scoring' 방식을 통해 LLM의 in-context learning 능력을 극대화하여 더 신뢰할 수 있는 평가를 수행합니다 [Figure 1]. 또한, LoRA를 통해 Qwen2.5-14B-Instruct 모델을 경량화하여 효율적으로 학습시키고, PURE 프레임워크 기반의 강화학습을 통해 보상 신호를 모델 정책에 내재화합니다. 실험 결과, uPRM은 ProcessBench에서 LLM-as-a-Judge 대비 최대 15%의 절대적 정확도 향상을 기록하였습니다. 또한, Test-Time Scaling 실험에서 256개의 후보 생성 시 majority voting 대비 최대 6.9%의 성능 향상을 보였으며, 강화학습 환경에서는 기존 지도학습 기반의 sPRM보다 reward hacking에 더 강건한 특성을 보이며 Qwen2.5-Math-1.5B 모델에서 4%의 정확도 향상을 달성하였습니다 [Table 2].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 완전 비지도 학습을 통해 PRM을 구축함으로써, 복잡한 추론 태스크에서 인간 전문가의 개입 없이도 정밀한 과정 지도를 가능하게 하는 새로운 경로를 열었습니다. 실험을 통해 입증된 uPRM의 성능과 reward hacking에 대한 강건함은 보상 모델의 정확도가 반드시 하위 작업(downstream task)의 효율성을 보장하지는 않는다는 점을 시사하며, 더 나아가 연구 비용을 획기적으로 낮출 수 있는 실용적 가치를 제공합니다. 이 접근 방식은 향후 오픈 소스 LLM의 추론 성능을 향상하고, 더 확장 가능한 강화학습 파이프라인을 설계하는 데 중요한 기반이 될 것입니다.
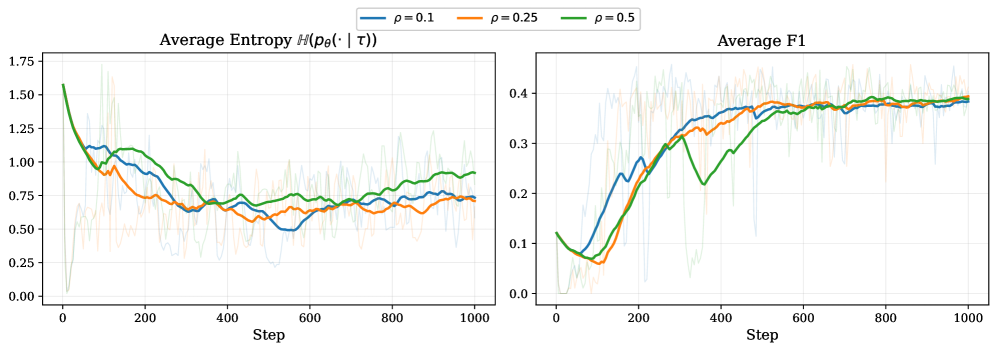
Figure A1 — 예산 하이퍼파라미터 영향
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Understanding Reasoning from Pretraining to Post-Training
- [논문리뷰] Agon: Competitive Cross-Model RL with Implicit Rival Grading of Reasoning
- [논문리뷰] TREK: Distill to Explore, Reinforce to Refine
- [논문리뷰] Native Active Perception as Reasoning for Omni-Modal Understanding
- [논문리뷰] VibeThinker-3B: Exploring the Frontier of Verifiable Reasoning in Small Language Models
Review 의 다른글
- 이전글 [논문리뷰] TransitLM: A Large-Scale Dataset and Benchmark for Map-Free Transit Route Generation
- 현재글 : [논문리뷰] Unsupervised Process Reward Models
- 다음글 [논문리뷰] WorldKV: Efficient World Memory with World Retrieval and Compression
댓글