[논문리뷰] Native Active Perception as Reasoning for Omni-Modal Understanding
링크: 논문 PDF로 바로 열기
메타데이터
저자: Zhenghao Xing, Ruiyang Xu, Yuxuan Wang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- OmniAgent: 비디오 이해를 POMDP(Partially Observable Markov Decision Process) 기반의 Observation-Thought-Action (OTA) 사이클로 정립하여, 능동적 정보 추출과 추론을 수행하는 네이티브 옴니 모달 에이전트입니다.
- OTA Cycle: 비디오 이해를 위한 반복적 프로세스로, Observation(오디오-비주얼 큐 추출), Thought(추론), Action(후속 행동 결정)이 유기적으로 연결된 아키텍처입니다.
- TAURA (Turn-aware Adaptive Uncertainty Rescaled Advantage): 다중 턴 추론에서 Advantage Homogenization 문제를 해결하기 위해 턴 수준의 엔트로피(Turn-level entropy)를 사용하여 핵심적인 추론 전환점에 더 높은 가중치를 부여하는 Reinforcement Learning 기법입니다.
- Agentic SFT (Supervised Fine-Tuning): Best-of-N trajectory 합성과 이중 단계 품질 제어(Outcome Verification 및 Rationality Audit)를 통해 에이전트의 초기 능동적 인식 능력을 강화하는 학습 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 패시브한 Long Video Understanding 모델들이 가진 컴퓨팅 자원 및 성능의 한계를 해결하기 위해 제안되었습니다. 기존 연구들은 비디오 전체를 균일하게 처리하거나 전역적 사전 스캔에 의존함으로써, 비디오 길이에 따라 계산 비용이 선형적으로 증가하는 고질적인 병목 현상을 겪고 있습니다 [Figure 1]. 또한, 에이전트 기반 모델들도 외부 모듈에 의존하여 추론과 인식 간의 그래디언트 흐름이 단절되는 문제가 발생합니다. 이에 따라 저자들은 비디오 길이에 독립적인 복잡도를 가지며, 명시적인 Active Perception을 통해 추론을 수행하는 새로운 프레임워크가 필요함을 강조합니다.
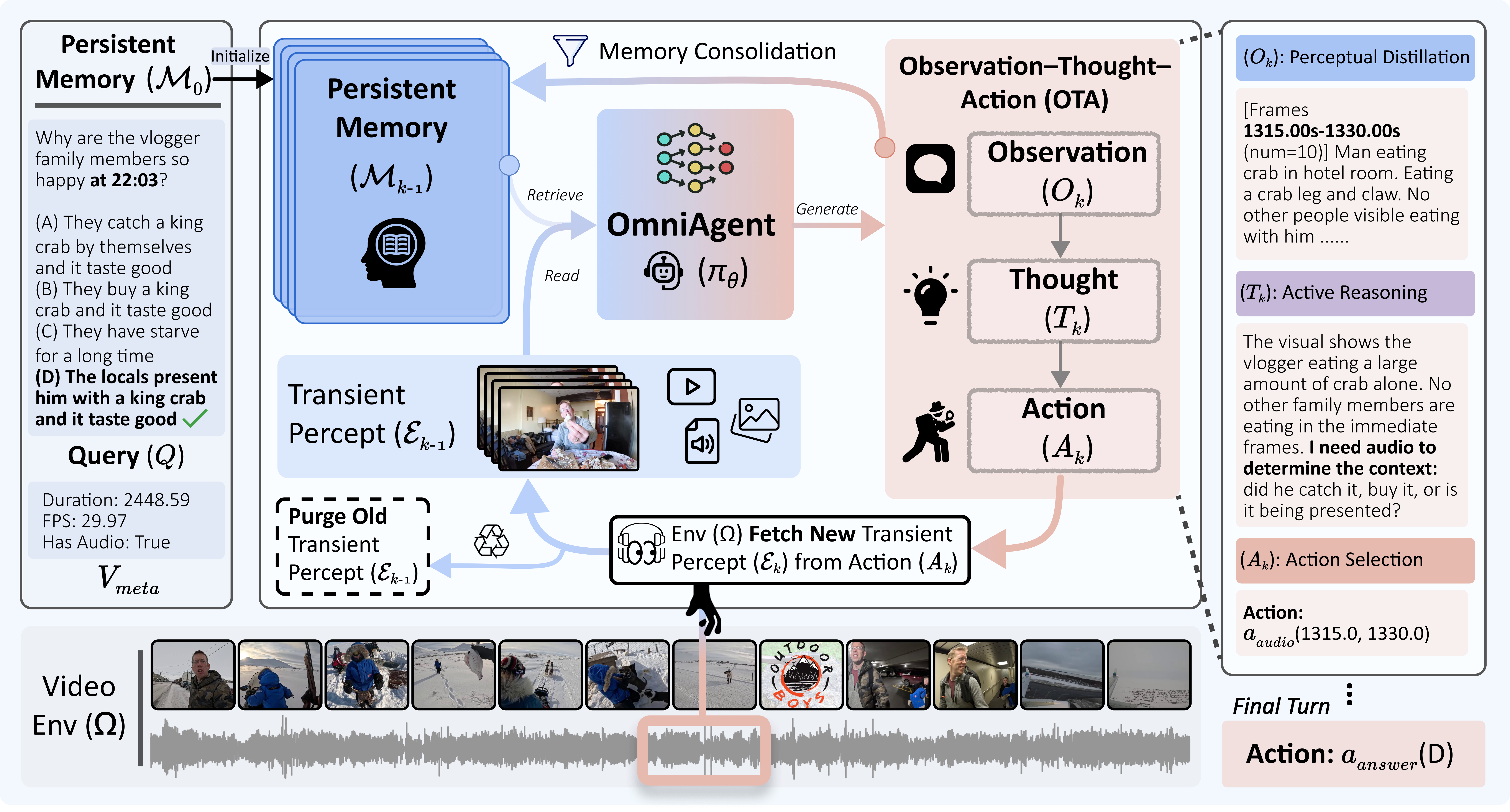
Figure 1 — OmniAgent 프레임워크
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 OmniAgent라는 네이티브 옴니 모달 에이전트 프레임워크를 제안하여, 추론 과정에서 선택적으로 오디오-비주얼 정보를 추출하고 이를 Persistent Textual Memory에 저장함으로써 비디오 길이와 관계없이 일관된 연산 성능을 유지하게 합니다 [Figure 1]. 먼저, Agentic SFT를 통해 58K 개의 궤적 데이터셋으로 성공적인 탐색 경로를 학습하고, 이중 품질 제어 기법을 통해 논리적으로 근거가 있는 행동만을 강화합니다. 이후 TAURA를 도입하여 GRPO 학습 시 턴별 엔트로피를 통해 중요한 발견 지점에 대한 보상을 증폭함으로써, 단순 추측을 배제하고 추론의 효율성을 극대화합니다. 정량적 실험 결과, OmniAgent-7B는 LVBench에서 50.5%의 정확도를 기록하여 10배 더 큰 Qwen2.5-VL-72B 모델(47.3%)을 능가하는 성능을 보였습니다 [Table 1]. 또한, VideoMME-Long 등 10개의 벤치마크에서 기준 모델 대비 뛰어난 정량적 지표 개선을 입증했으며, 특히 LongVALE에서 Temporal Grounding 정확도가 33.4% 향상되었습니다 [Table 1, Table 2].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 비디오 이해를 능동적인 POMDP 문제로 재정의하여 OmniAgent라는 혁신적인 에이전트 아키텍처를 성공적으로 구현하였습니다. 이 연구는 Active Perception이 단순히 보조적인 기술이 아니라 대규모 모델의 핵심 추론 능력과 결합될 수 있음을 증명했습니다. 특히 TAURA와 같은 보상 할당 기법은 다중 턴 에이전트 학습의 새로운 방향성을 제시합니다. 이로써 향후 산업계의 장시간 비디오 분석 및 고차원 멀티모달 추론 태스크에서 높은 효율성과 확장성을 제공하는 표준 프레임워크로 자리매김할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] VibeThinker-3B: Exploring the Frontier of Verifiable Reasoning in Small Language Models
- [논문리뷰] Thinking with Imagination: Agentic Visual Spatial Reasoning with World Simulators
- [논문리뷰] Unsupervised Process Reward Models
- [논문리뷰] Unlocking Complex Visual Generation via Closed-Loop Verified Reasoning
- [논문리뷰] Achieving Gold-Medal-Level Olympiad Reasoning via Simple and Unified Scaling
Review 의 다른글
- 이전글 [논문리뷰] MyPCBench: A Benchmark for Personally Intelligent Computer-Use Agents
- 현재글 : [논문리뷰] Native Active Perception as Reasoning for Omni-Modal Understanding
- 다음글 [논문리뷰] PAIWorld: A 3D-Consistent World Foundation Model for Robotic Manipulation
댓글